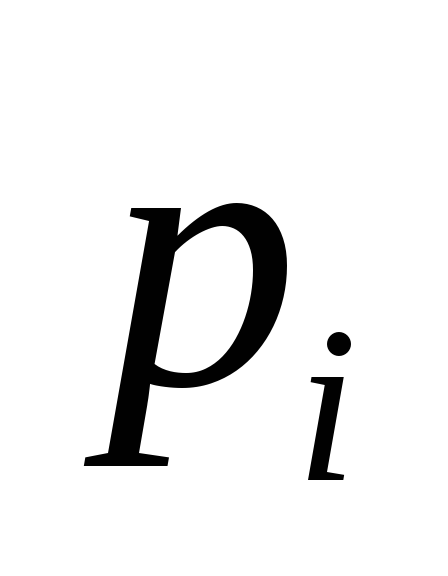




вибір читачів





Популярні статті
Доброго дня! Мене звуть Олександр Георгійович і я є московським професійним репетитором з інформатики та програмування. Вам попалася завдання, пов'язане з кодуванням і, і ви заплуталися в алгоритмі її рішення? Вам терміново потрібно познайомитися зумовою Фано, А також записатися до мене на індивідуальні уроки. На своїх уроках я акцентую увагу на вирішенні тематичних простих і складних вправ.
Значення нуклеїнових кислот як носії генетичної інформації не було визнано протягом тривалого часу. Це було головним чином тому, що білки для художньої освіти несуть відповідальність. Вони забезпечують структурні або ферментні білки для формування характеристик організму.
Оскільки структурні білки представляють собою білки, такі. Наприклад, якщо утворюються характерний синій квітка колір, як і в клітинах пелюсток синього барвника повинні бути синтезовані. Антоціани є ті барвники, які барвник, наприклад, квіти братки. Без антоціани, квіти залишаються білими. Синтез антоціанів контролюється ферментами, які хімічно пов'язаних з класом білків.
Умова Фано названо на честь його творця, італійсько-американського вченого Роберта Фано. Умова є необхідною в теорії кодування при побудові самотермінірующегося коду. З огляду на іншу термінологію, такий код називається префіксним.
Сформулювати дана умова можна наступним чином: « жодне кодове слово не може виступати в якості початку будь-якого іншого кодового слова».
Через їх велике значення в підготовці функцій і їх різноманітності вже давно припускали, що білки повинні бути генетичним матеріалом. По-друге, ви не могли собі уявити, яким чином генетична інформація повинна бути зашифрована для формування певних білків в самих цих молекул.
У своїй хімічній структурі, тому інформація повинна бути зашифрована для формування білка і зберігали. Білки складаються з послідовності амінокислот. Будівля білків, тільки 20 різних амінокислот, як правило, беруть участь. У нуклеїнових кислотах чотирьох різних баз відбуваються. Якщо кожна амінокислота кодується нуклеотидной бази, тому може тільки 4 +1 = 4 амінокислоти кодуються.
З математичної точки зору умова можна сформулювати наступним чином: « якщо код містить словоB, то для будь-якої непорожній рядкиC слова BC не існує в коді».
Існує також і зворотне правило Фано, формулювання якого звучить наступним чином: « жодне кодове слово не може виступати в якості закінчення будь-якого іншого кодового слова».
В ході своїх досліджень, були підтверджені теоретичні міркування. Порядок амінокислот білкової молекули визначається порядком підстав в органічних нуклеотидів. Ці три послідовні основи утворюють триплет. 3 підстави необхідні для визначення амінокислоти.
Оскільки існує 64 різних варіантів кодування і тільки 20 різних амінокислот повинні бути закодовані, існують для однієї і тієї ж амінокислоти, часто кілька способів шифрування. Різні білки містять різну кількість амінокислот. в свою чергу, визначається порядок структурних характеристик і інших властивостей кінцевого білка.
З математичної точки зору зворотне умова можна сформулювати наступним чином: « якщо код містить слово B, то для будь-якої непорожній рядки C слова CB не існує в коді».
Розглянемо телефонні номери в традиційної телефонії. Якщо вже існує номер «102», то номер «1029876» просто не буде виданий. У разі набору перших трьох цифр АТС перестає розпізнавати і приймати всі інші цифри, поєднуючи з абонентом за номером 102. Однак це правило не є дійсним для операторів мобільного зв'язку. Пов'язано це з тим, що для набору номера необхідно натискання відповідної клавіші, якій, в основному, є клавіша із зображенням зеленої телефонної трубки. З цієї причини, номера «102», «1020» і «1029876» можуть існувати і бути закріпленими за різними адресатами.
До досліджень в різних організмах можна було б показати, що - крім дуже рідкісних винятків - все організми використовують одні і ті ж кодони для шифрування амінокислоти. Генетичний код практично універсальний. Кодер не стандартизований, тому є можливості для підвищення ефективності. Однак пропонуються приклади реалізації, які не є особливо швидкими і особливо ефективними.
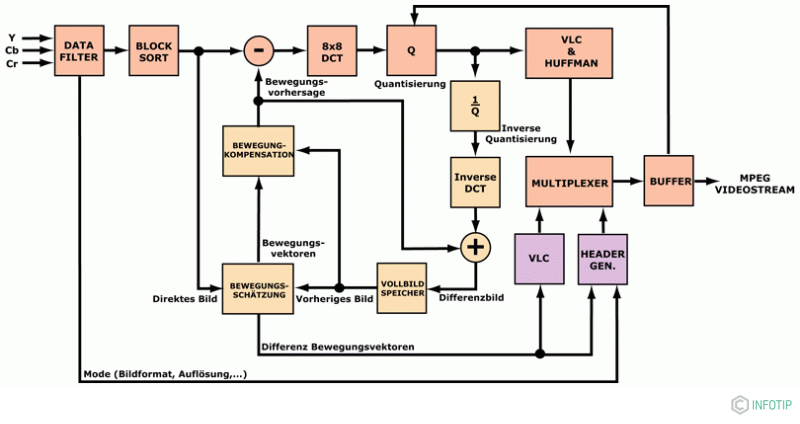
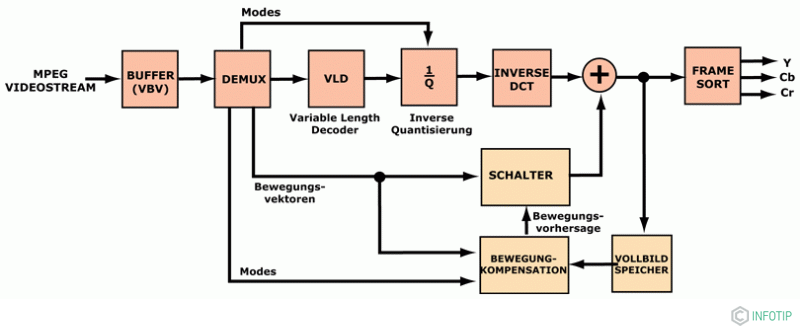
Алгоритм використовує в основному два методи: Дискретне косинусное перетворення для зменшення просторової надмірності і блок-орієнтованого передбачення руху для зменшення тимчасових скорочень. Теорія алгоритмів передбачає, що блок формування зображення має просторову прив'язку до своїх сусідів і посилання на інформацію зображення в тих же координатах на попереднє і наступне таке зображення. Це посилання не означає, що одна і та ж інформація передається кілька разів.
Умова задачі:дана послідовність, яка складається з літер «A», «B», «C», «D» і «E». Для кодування наведеної послідовності застосовується нерівномірний двійковий код, За допомогою якого можна здійснити однозначне декодування.
питання: Чи є можливість для одного з символів скоротити довжину кодового слова таким чином, щоб зберегти можливість однозначного декодування? При цьому коди інших символів повинні залишитися незмінними.
Ця надмірність повинна бути визнана і замінена короткої інформацією про заповнювач. У цьому випадку це, звичайно, як можна менше втрат, тобто без будь-якої видимої деградації якості. На додаток до фактичних призначених для користувача даних кількість даних системи і управління також передається в потоці даних в так званих заголовках.
Тема послідовності, що передує корисним даними, містить інформацію про кількість пікселів, кількості зображень в секунду, форматі зображення, а також необхідного розміру буферної пам'яті, який потрібно для декодування.
Рішення: Для того, щоб збереглася можливість декодування, достатнім є дотримання прямого або зворотногоумови Фано. Проведемо послідовну перевірку варіантів 1, 3 і 4. У разі якщо жоден з варіантів не підійде, правильною відповіддю буде варіант 2 (не представляється можливим).
Варіант 1. Код: A - 00, B - 01, C - 011, D - 101, і E - 111. Пряме умова Фано не виконується: код символу «B» збігається з початком коду символу «C». Зворотне правило Фано не виконується: код символу «B» збігається із закінченням коду символу «D». Варіант не є відповідним.
Для цієї мети різниця визначається в вирізах часткових зображень між окремими блоками пікселів. З цього можна бачити, в якому напрямку і з якою швидкістю рухається частковий об'єкт. Таким чином, може бути сформований прогноз. Чим краще пророкування, тим менше обсяг переданих даних. З цього можна створити нове пророцтво, яке вже враховує, в яких областях руху зображення в певних напрямках очікувати. Якщо цей прогноз є дуже точним, то на виході диференціального етапу створюється потік даних.
Варіант 3. Код: A - 00, B - 010, C - 01, D - 101, і E - 111. Пряме умова Фано не виконується: код символу «C» збігається з початком коду символу «B». Зворотне умова також не виконується: код символу «C» збігається із закінченням коду символу «D». Варіант не є відповідним.
Варіант 4. Код: A - 00, B - 010, C - 011, D - 01, і E - 111. Пряме умова Фано не виконується: код символу «D» збігається з початком коду символів «B» і «C». Однак спостерігається виконання зворотного правила Фано: код символу «D» не збігається із закінченням коду всіх інших символів. З цієї причини, варіант є підходящим.
На додаток до разностному зображенню, проте, два отриманих вектора руху також повинні передаватися по величині і напрямку з короткими кодовими словами, так що блок з компенсацією руху може бути відновлений з боку декодера. 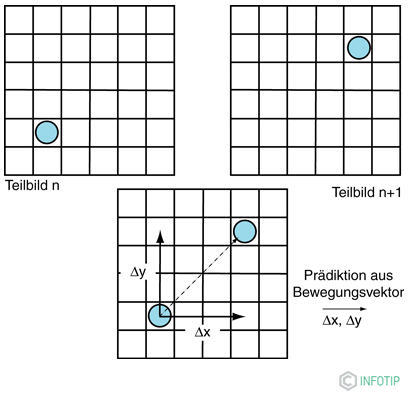
Тому немає скорочення тимчасової надмірності.
Таким чином, кодування і, отже, декодування є нелінійними, а не зображення по картинці. 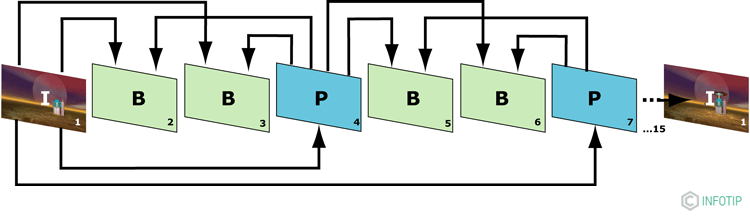
Щоб мінімізувати цифровий відеосигнал в його бітової швидкості, необхідно шукати і пригнічувати нерелевантні інформацію. Вони формуються деталями зображення і високою роздільною здатністю кольоровості. Через чутливості людського ока вони можуть бути зменшені в певній мірі, якщо це не сприймається як погіршується за якістю. Ця колірна модель має ту перевагу, що тільки сигнал яскравості повинен передаватися з повною пропускною здатністю.
Після перевірки варіантів вирішення завдання на відповідність прямому і зворотному умові Фано, Було встановлено, що правильним є варіант 4.
відповідь: 4
А зараз я вам пропоную ознайомитися з мультимедійним рішенням завдання, яка була запропонована в демонстраційному варіанті ЄДІ з інформатики та ІКТ. До речі, дана задача відноситься до типу завдань, що вирішуються за використанням умови Фано.
Інформація про колір передається зі зменшеним дозволом. Тільки цей захід дозволяє скоротити дані на 50% без помітного зниження якості. Однак скорочення невідповідності завжди призводить до втрати інформації. Отже, це також називається кодуванням з втратами.
Відмінності в яскравості, що відбуваються там, приведуть до змінного компоненту як в горизонтальному, так і у вертикальному напрямку, яке, відповідно, називається горизонтальною або вертикальною просторової частотою. Таким чином, в разі вертикальної смуговий картини виникають тільки горизонтальні просторові частоти, а в разі горизонтальної смуги - тільки вертикальні просторові частоти. Наприклад, відтінки сірого, це тільки рівна частина. Однак, як правило, всі три компоненти завжди присутні.
Якщо після прочитання цієї публікації у вас все одно залишилися якісь питання, нерозуміння або ви хочете закріпити пройдений матеріал практичними рішеннями, то телефонуйте і записуйтеся до мене на приватні уроки з інформатики та ІКТ.
Наприклад, якщо є код 110, то вже не можуть використовуватися коди 1, 11, 1101, 110101 та ін.
На стороні введення спочатку обробляються невеликі області зображення з використанням дискретного косинусного перетворення. В результаті виходить рівна частка всіх 64 пікселів. Цей коефіцієнт присвоюється верхньому лівому кутку нової матриці. Всі значення вправо відносяться до зростаючим горизонтальним частотам, все значення зменшуються до зростаючих вертикальних частот. Чим вище ці просторові частоти, тим більше нечутливим стає очей, тому що тонкі структури на зображенні оптично менш домінують, ніж грубі структури.
Якщо умова Фано виконується, то при прочитанні (декодування, розшифрування) закодованого повідомлення шляхом зіставлення з таблицею кодів завжди можна точно вказати, де закінчується один код і починається інший.
приклад 1. Чи є коди, представлені втабл. 4, префіксними? Коди, представлені в табл. 4, не є префіксними. Див., Наприклад, коди букв «О» і «Е», «А» і «Н», «С» і «М», «Д» і «Ч».
Тому навіть коефіцієнти для великих просторових частот можна знехтувати без зниження якості зображення. Зменшення нерелевантності реалізується шляхом квантування відеосигналу. У цьому випадку деталі в шаблоні зображення переносяться зі зменшеним дозволом після залежного від частоти зважування. Ускладнення здійснюється за допомогою матриць квантування, інтегрованих в кодировщик. Оскільки око сприймає низькі просторові частоти краще, ніж високі, дільник стає вище з частотою.
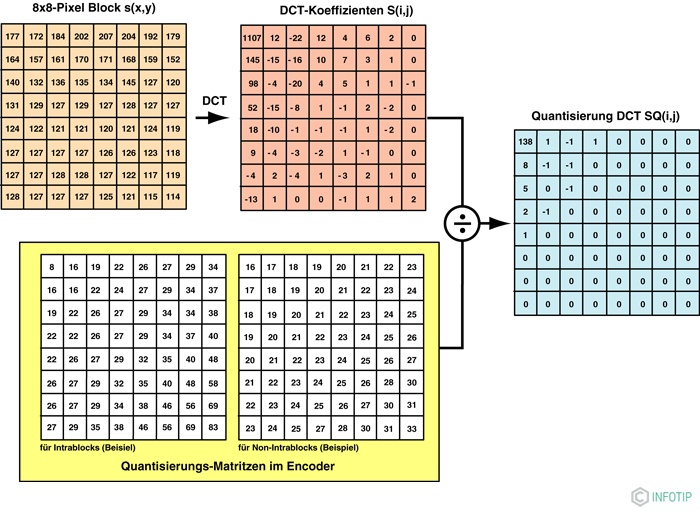
Матриці квантування можуть використовуватися для визначення того, скільки і яка інформація видаляється з вхідного потоку, і, отже, також визначається якість передачі. Наприклад, щоб забезпечити стислий потік, Щоб отримати відеопотік з максимально можливою швидкістю передачі даних, Для відео за запитом зображення повинно бути зроблено «плоским». Для цього рекомендується матриця з не настільки сильним збільшенням подільників. Наприклад, на фіг. 8 різні матриці використовуються для внутріблок і невзаємодіючими.
приклад 2. Є таблиця префіксних кодів (табл. 6). Розкодування наступне повідомлення, закодоване з використанням цієї наведеної кодової таблиці:
Табл. 6. Таблиця префіксних кодів
Декодування проводиться циклічним повторенням наступних дій:
Результатом квантування є квантованими рівна частина, яка, в свою чергу, знаходиться в верхньому лівому кутку матриці, а також квантовані горизонтальні і вертикальні просторові частоти. Нулі, які часто зустрічаються в регіонах, вражають матрицю, яка тепер сформована. Їх можна комбінувати з відповідними методами стиснення без втрат, що призводить до зменшення потоків даних.
Для операції зчитування матриці використовується спеціальний алгоритм. В цьому випадку матриця зчитується з важливих глибших і несуттєвих більш високих значень за принципом зигзага, починаючи з тієї ж пропорції і після просторових частот. Тобто дані передаються в порядку падіння важливості. Для тієї ж пропорції кодується тільки різниця з попереднім блоком.
«Відрізати» від поточного повідомлення крайній зліва символ, приєднати його справа до робочого (поточному) кодовим словом;
порівняти поточний кодове слово з кодовою таблицею; якщо збігу немає, повернутися до пункту 1.
За допомогою кодової таблиці поточного кодовим словом поставити у відповідність символ первинного алфавіту;
Перевірити, чи є ще знаки в закодованому повідомленні; якщо так, то перейти до пункту 1.
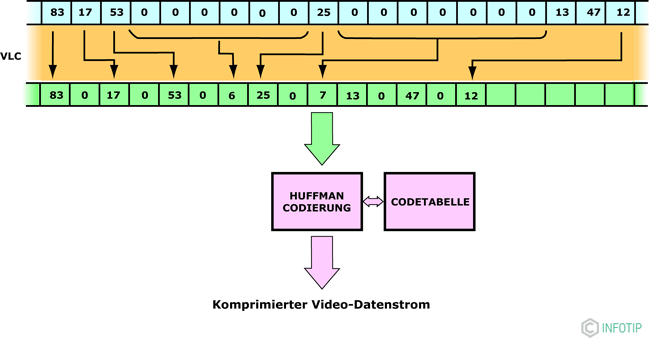
Ентропія - це міра середньої щільності інформації в повідомленні в теорії інформації. Ентропійних кодування - це методи для стиснення без втрат. Таким чином, вони збільшують ентропію. Основний метод полягає в тому, що кожен рядок тексту або фіксована рядок призначається послідовностям біт різної довжини в повідомленні. Якщо кілька послідовних послідовностей відбуваються в потоці даних, кількість нулів і значення числа, наступного без нуля, об'єднуються у вигляді слів даних. Маркер «кінець блоку» вказує, де існують тільки 0 коефіцієнтів.
Застосування даного алгоритму до запропонованого вище закодованого повідомленням дає:
Таким чином, довівши процедуру декодування до кінця, можна отримати повідомлення: «мама мила раму ».
Інші дані піддаються кодування Хаффмана, іншого методу ентропії кодування без втрат. Мета цієї функції - замінити всі шаблони часто зустрічаються пар чисел короткими кодовими словами з даної таблиці. Однак для рідкісних пар цифр необхідно прийняти більш довгі кодові слова.
У більшості випадків кодери вже містять файли шаблонів, в які вводяться параметри для найбільш часто стандартних проектів. Деякі настройки дійсно необхідні, оскільки вони безпосередньо визначають розмір, якість і сумісність цільового файлу. Інші, не менш важливі настройки, є системно-передбачуваними і повинні бути залишені за шаблоном. Описані тут налаштування відносяться до числа перших.
Таким чином, використання префіксного кодування дозволяє робити повідомлення коротшим, оскільки немає необхідності передавати роздільники знаків.
Однак умова Фано не встановлює конкретного способу формування префіксного коду, залишаючи поле для діяльності по розробці найкращого з можливих префіксних кодів.
Розглянемо варіант кодування, який був запропонований в 1948 - 1949 рр. незалежно К. Шенноном і Р. Фано.
Розглянемо схему кодування (як вона будується) Шеннона-Фано на наступному прикладі .
Нехай є первинний алфавіт, що складається з шести знаків:  , де
, де 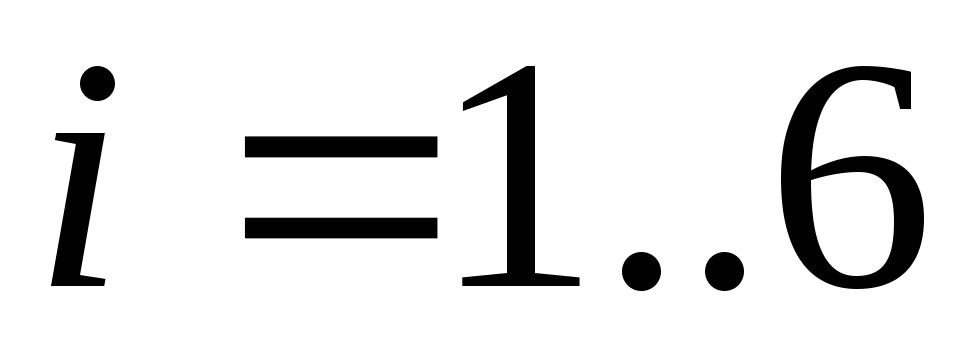 . Нехай ймовірності появи цих знаків в повідомленнях такі:
. Нехай ймовірності появи цих знаків в повідомленнях такі: 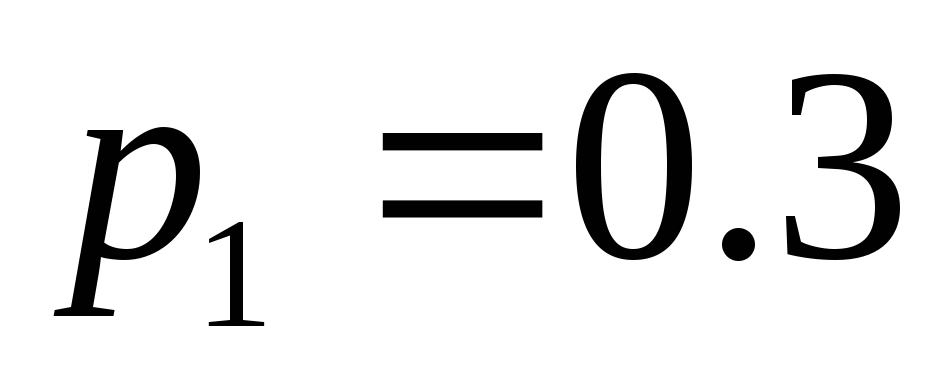 ,
,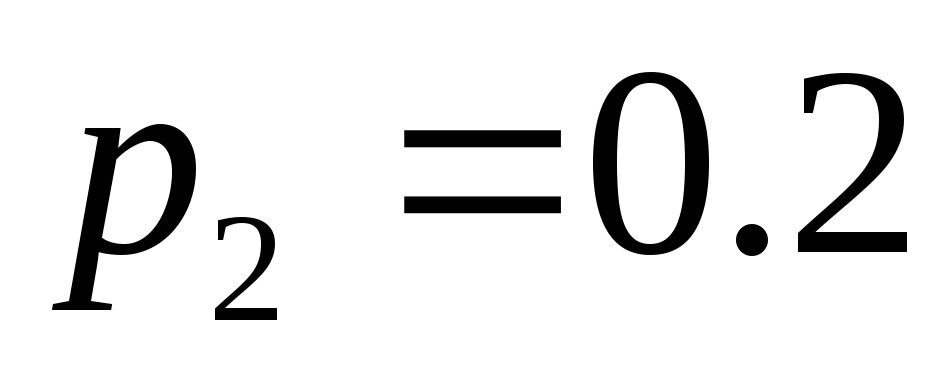 ,
,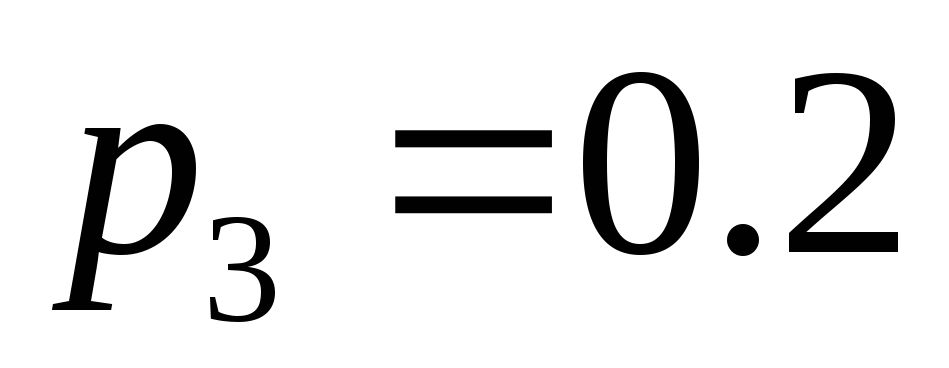 ,
,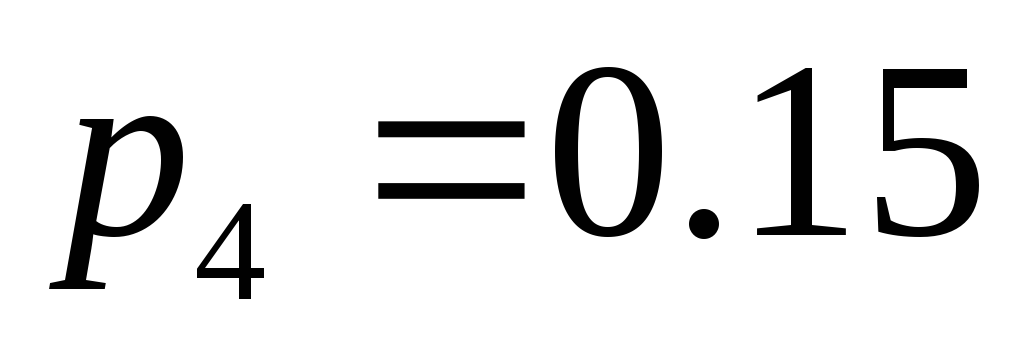 ,
,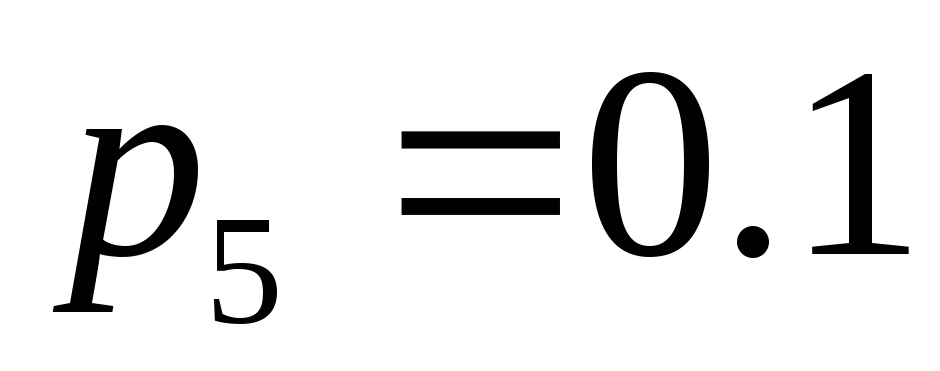 і
і 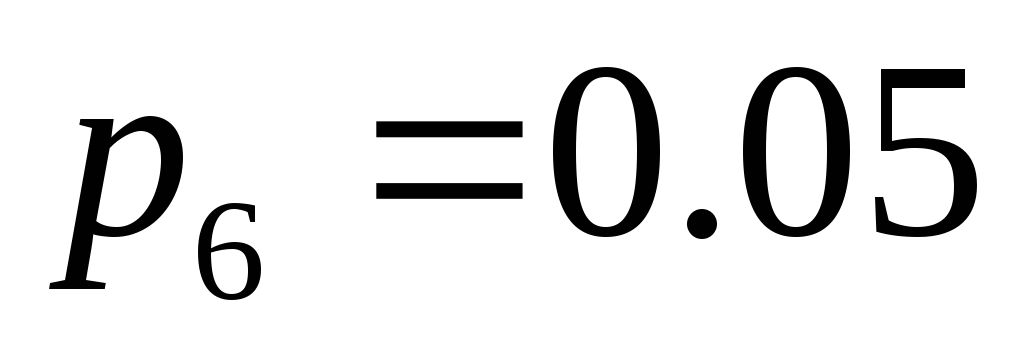 . Розташуємо ці знаки в таблиці в порядку убування ймовірностей.
. Розташуємо ці знаки в таблиці в порядку убування ймовірностей.
Розділимо знаки на дві групи так, щоб суми ймовірностей в кожній з цих двох груп були б приблизно рівними. При цьому в 1-ї групи потраплять 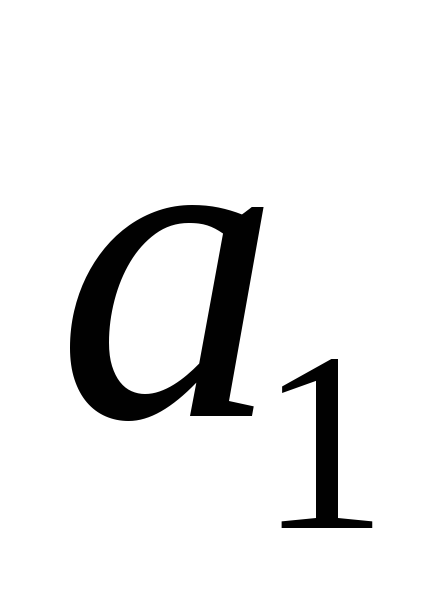 і
і 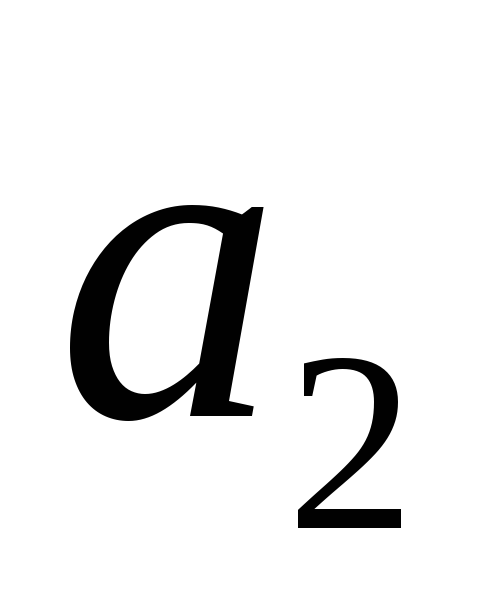 , А решта - до 2-ї групи. знакам першої групи дамо перший зліва розряд їх кодів «0», а першим зліва розрядом кодів символів другої групи нехай буде «1».
, А решта - до 2-ї групи. знакам першої групи дамо перший зліва розряд їх кодів «0», а першим зліва розрядом кодів символів другої групи нехай буде «1».
Продовжимо розподіл кожної з виходять груп на підгрупи за тією ж схемою, тобто так, щоб суми ймовірностей на кожному кроці в обох підгрупах ділимо групи були б максимально близькими. Таким чином будемо отримувати по одному наступні розряди кодів символів . Ці наступні розряди будемо приписувати праворуч до вже наявних.
Вся ця процедура може бути схематично зображено в табл 7.
Табл. 7. Побудова коду Шеннона-Фано
|
знак |
|
розряди коду | ||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
Видно, що побудовані коди знаків задовольняють умові Фано, отже, таке кодування є префіксним.
Знайдемо середню довжину отриманого коду за формулою
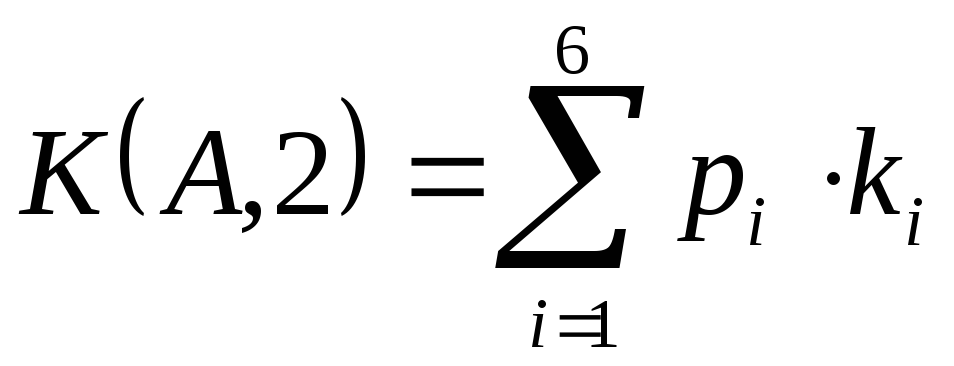 ,
,
де 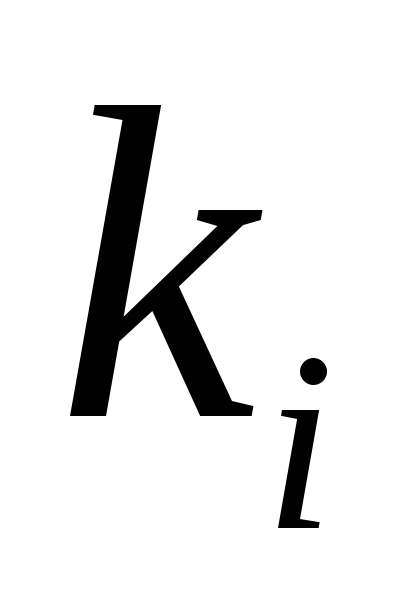 - число розрядів (символів) в коді, відповідному символу .
- число розрядів (символів) в коді, відповідному символу .
З таблиці видно, що 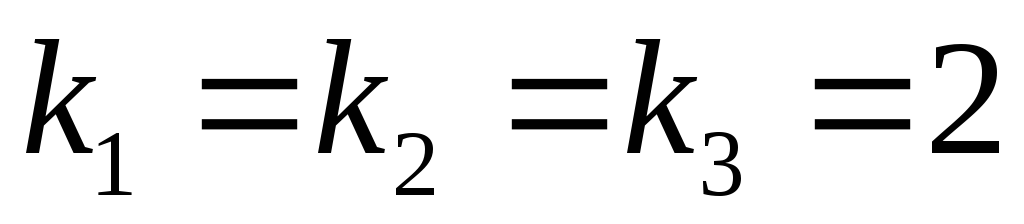 ,
,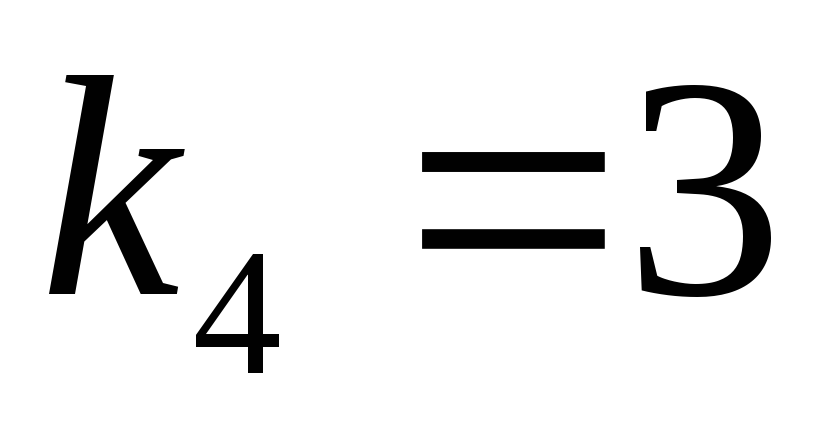 ,
,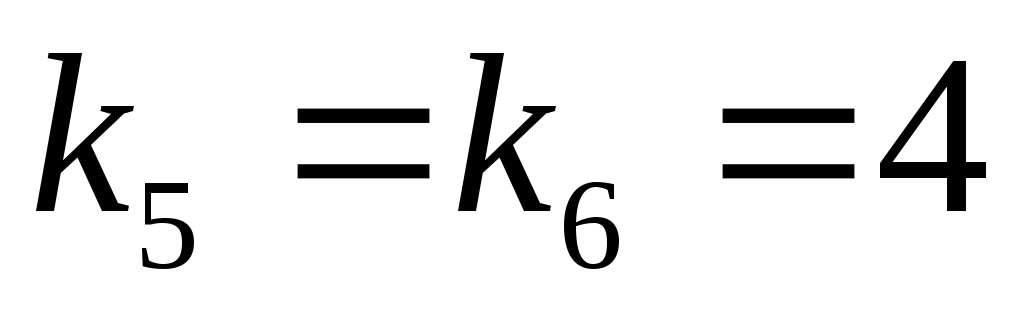 .
.
Таким чином, отримуємо:
Таким чином, для кодування одного символу первинного алфавіту  треба було в середньому 2.45 символів вторинного (довічного) алфавіту.
треба було в середньому 2.45 символів вторинного (довічного) алфавіту.
Визначимо середня кількість інформації, що припадає на знак первинного алфавіту в першому наближенні (з урахуванням різної ймовірності появи цих знаків в повідомленнях). Застосуємо формулу Шеннона:
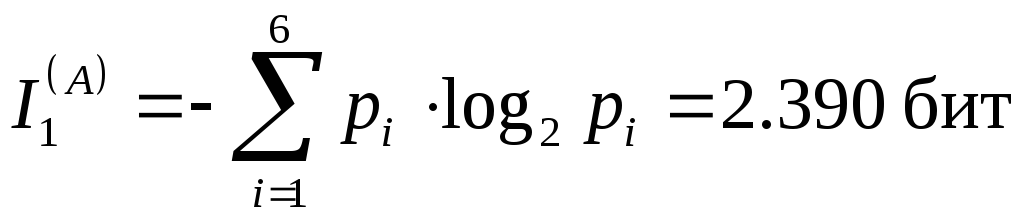 .
.
Знайдемо надмірність отриманого двійкового коду:
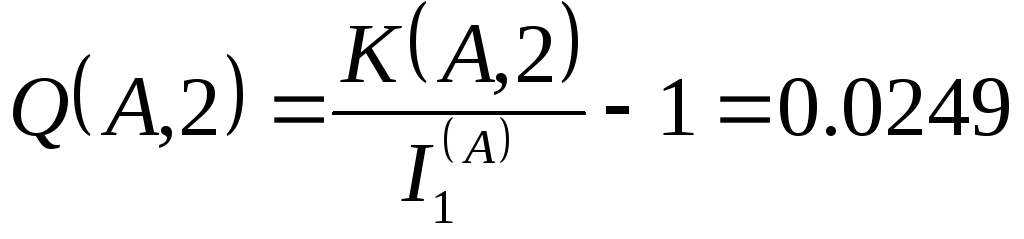 ,
,
тобто надмірність - близько 2.5.
З'ясуємо, чи є отриманий код оптимальним. Нулів в отриманих кодах - 6 штук, а одиниць - 11 штук. Таким чином, ймовірність появи 0 і 1 далеко не однакові. Отже, отриманий код не можна вважати оптимальним.
| Статті по темі: | |
|
Митниця Німеччини: митні правила, що можна провозити
У зв'язку зі вступом в силу антитютюнового закону і прийняття ряду ... У скільки років можна купувати алкоголь в різних країнах
Хто з нас не чув про заборону реалізації алкоголю особам, ... Вводиться заборона на продаж алкоголю
28.08.2017 (Фото: Сайт міста Перм 59.ru) Відповідно до ... | |




