вибір читачів





Популярні статті
22. Кодування ІНФОРМАЦІЇ
22.1. Загальні відомості
кодування - подання інформації в альтернативному виді. За своєю суттю кодові системи (або просто коди) аналогічні, в яких елементів кодируемой інформації відповідають кодові позначення. Відмінність полягає в тому, що в шифри присутній змінна частина (ключ), яка для певного вихідного повідомлення при одному і тому ж алгоритмі шифрування може видавати різні шифртекст. У кодових системах змінної частини немає. Тому один і той же вихідне повідомлення при кодуванні, як правило, завжди виглядає однаково 1. Іншою відмінною рисою кодування є застосування кодових позначень (замін) цілком для слів, фраз або чисел (сукупності цифр). Заміна елементів кодируемой інформації кодовими позначеннями може бути виконана на основі відповідної таблиці (на зразок таблиці шіфрозамен) або визначена за допомогою функції або алгоритму кодування.
В якості елементів кодируемой інформації можуть виступати:
Букви, слова і фрази природної мови;
Різні символи, такі як знаки пунктуації, арифметичні і логічні операції, оператори порівняння і т.д. Слід зазначити, що самі знаки операцій і оператори порівняння - це кодові позначення;
Аудіовізуальні образи;
Ситуації і явища;
Спадкова інформація;
кодові позначення можуть являти собою:
Букви і поєднання букв природної мови;
Графічні позначення;
Електромагнітні імпульси;
Світлові і звукові сигнали;
Набір і поєднання хімічних молекул;
Кодування може виконуватися в цілях:
Зручності зберігання, обробки і передачі інформації (як правило, закодована інформація може надаватися більш компактно, а також придатна для обробки і передачі автоматичними програмно-технічними засобами);
Зручності інформаційного обміну між суб'єктами;
Наочності відображення;
Ідентифікації об'єктів і суб'єктів;
Приховування секретної інформації;
Кодування інформації буває одно- і багаторівневим. Прикладом одноуровневого кодування служать світлові сигнали, що подаються світлофором (червоний - стій, жовтий - приготуватися, зелений - вперед). Як багаторівневого кодування можна привести уявлення візуального (графічного) образу як файл фотографії. Спочатку візуальна картинка розбивається на складові елементарні елементи (пікселі), тобто кожна окрема частина візуальної картинки кодується елементарним елементом. Кожен елемент представляється (кодується) у вигляді набору елементарних кольорів (RGB: англ. Red - червоний, green - зелений, blue - синій) відповідною інтенсивністю, яка в свою чергу представляється у вигляді числового значення. Згодом набори чисел, як правило, перетворюються (кодуються) з метою більш компактного представлення інформації (наприклад, в форматах jpeg, png і т.д.). І нарешті, підсумкові числа представляються (кодуються) у вигляді електромагнітних сигналів для передачі по каналах зв'язку або областей на носії інформації. Слід зазначити, що самі числа при програмній обробці надаються згідно з прийнятою системою кодування чисел.
Кодування інформації може бути оборотним і незворотним. При оборотному кодуванні на основі закодованого повідомлення можна однозначно (без втрати якості) відновити кодуються повідомлення (вихідний образ). Наприклад, кодування за допомогою азбуки Морзе або штрих-коду. При незворотному кодуванні однозначне відновлення вихідного образу неможливо. Наприклад, кодування аудіовізуальної інформації (формати jpg, mp3 або avi) або.
Азбука Морзе - спосіб кодування символів (букв алфавіту, цифр, знаків пунктуації та ін.) За допомогою послідовності «точок» і «тире». За одиницю часу приймається тривалість однієї точки. Тривалість тире дорівнює трьом точкам. Пауза між елементами одного знака - одна точка (близько 1/25 частки секунди), між знаками в слові - 3 точки, між словами - 7 точок. Названий на честь американського винахідника і художника Семюеля Морзе.
| Російська літера |
Латинська літера |
код Морзе | Російська літера |
Латинська літера |
код Морзе | символ | код Морзе |
| A | A | · − | Р | R | · − · | 1 | · − − − − |
| Б | B | − · · · | З | S | · · · | 2 | · · − − − |
| В | W | · − − | Т | T | − | 3 | · · · − − |
| Г | G | − − · | У | U | · · − | 4 | · · · · − |
| Д | D | − · · | Ф | F | · · − · | 5 | · · · · · |
| Е (Е) | E | · | Х | H | · · · · | 6 | − · · · · |
| Ж | V | · · · − | Ц | C | − · − · | 7 | − − · · · |
| З | Z | − − · · | Ч | Ö | − − − · | 8 | − − − · · |
| І | I | · · | Ш | CH | − − − − | 9 | − − − − · |
| Й | J | · − − − | Щ | Q | − − · − | 0 | − − − − − |
| До | K | − · − | ред | Ñ | − − · − − | Крапка | · · · · · · |
| Л | L | · − · · | И | Y | − · − − | кома | · − · − · − |
| М | M | − − | Ь (ред) | X | − · · − | ? | · · − − · · |
| Н | N | − · | Е | É | · · − · · | ! | − − · · − − |
| Про | O | − − − | Ю | Ü | · · − − | @ | · − − · − · |
| П | P | · − − · | Я | Ä | · − · − | Кінець зв'язку (end contact) | · · − · − |
Ріс.22.1. Фрагмент азбуки Морзе
Спочатку азбука Морзе застосовувалася для передачі повідомлень в телеграфі. При цьому точки і тире передавалися у вигляді електричних сигналів, що проходять по дротах. На даний момент азбуку Морзе, як правило, використовують в місцях, де інші засоби обміну інформацією недоступні (наприклад, в тюрмах).
Цікавий факт пов'язаний з винахідником першої лампочки Томасом Альвою Едісоном (1847-1931 рр.). Він погано чув і спілкувався зі своєю дружиною, Мері Стіуелл, за допомогою азбуки Морзе. Під час залицяння Едісон зробив пропозицію, відстукати слова рукою, і вона відповіла тим же способом. Телеграфний код став звичайним засобом спілкування для подружжя. Навіть коли вони ходили в театр, Едісон клав руку Мері собі на коліно, щоб вона могла «телеграфувати» йому діалоги акторів.
код Бодо - цифровий 5-бітний код. Був розроблений Емілем Бодо в 1870 р для свого телеграфу. Код вводився прямо клавіатурою, що складається з п'яти клавіш, натискання або ненажатом клавіші відповідало передачі або непередачі одного біта в пятібітном коді. Існує кілька різновидів (стандартів) даного коду (CCITT-1, CCITT-2, МТК-2 та ін.) Зокрема МТК-2 є модифікацією міжнародного стандарту CCITT-2 з додавання букв кирилиці.
| керуючі символи | ||||
| двійковий код |
десятковий код |
призначення | ||
| 01000 | 8 | повернення каретки | ||
| 00010 | 2 | Переклад рядка | ||
| 11111 | 31 | букви латинські | ||
| 11011 | 27 | цифри | ||
| 00100 | 4 | пропуск | ||
| 00000 | 0 | букви російські | ||
| двійковий код |
десятковий код |
Латинська літера |
Російська літера |
цифри і інші символи |
| 00011 | 3 | A | А | - |
| 11001 | 25 | B | Б | ? |
| 01110 | 14 | C | Ц | : |
| 01001 | 9 | D | Д | Хто там? |
| 00001 | 1 | E | Е | З |
| 01101 | 13 | F | Ф | Е |
| 11010 | 26 | G | Г | Ш |
| 10100 | 20 | H | Х | Щ |
| 00110 | 6 | I | І | 8 |
| 01011 | 11 | J | Й | Ю |
| 01111 | 15 | K | До | ( |
| 10010 | 18 | L | Л | ) |
| 11100 | 28 | M | М | . |
| 01100 | 12 | N | Н | , |
| 11000 | 24 | O | Про | 9 |
| 10110 | 22 | P | П | 0 |
| 10111 | 23 | Q | Я | 1 |
| 01010 | 10 | R | Р | 4 |
| 00101 | 5 | S | З | " |
| 10000 | 16 | T | Т | 5 |
| 00111 | 7 | U | У | 7 |
| 11110 | 30 | V | Ж | = |
| 10011 | 19 | W | В | 2 |
| 11101 | 29 | X | Ь | / |
| 10101 | 21 | Y | И | 6 |
| 10001 | 17 | Z | З | + |
Ріс.22.2. Стандарт коду Бодо МТК-2
На наступному малюнку показана телетайпна перфолента з повідомленням, переданим за допомогою коду Бодо.
Мал. 22.3. Перфолента з кодом Бодо
Слід зазначити два цікаві факти, пов'язані з кодом Бодо.
1. Співробітники телеграфної компанії AT & T Гільберта Вернам і Мейджор Джозеф Моборн в 1917 р запропонували ідею автоматичного шифрування телеграфних повідомлень на основі коду Бодо. Шифрування виконувалося.
2. Відповідність між англійською та російською алфавітами, прийняте в МТК-2, було використано при створенні комп'ютерних кодувань КОИ-7 і КОИ-8.
ASCII і Unicode.
ASCII (англ. American Standard Code for Information Interchange) - американська стандартна кодировочная таблиця для друкованих та керуючих символів. Спочатку була розроблена як 7-бітна для подання 128 символів, при використанні в комп'ютерах на символ виділялося 8 біт (1 байт), де 8-ий біт служив для контролю цілісності (біт парності). Пізніше, із задіянням 8 біта для подання додаткових символів (всього 256 символів), наприклад букв національних алфавітів, стала сприйматися як половина 8-бітної. Зокрема на основі ASCII були розроблені кодування, що містять букви російського алфавіту: для операційної системи MS-DOS - cp866 (англ. Code page - кодова сторінка), для операційної системи MS Windows - Windows 1251, для різних операційних систем - ЯКІ-8 ( код обміну інформацією, 8 бітів), ISO 8859-5 та інші.
| Кодування ASCII | додаткові символи | ||||||||||
| двійковий код |
десятковий код |
символ | двійковий код |
десятковий код |
символ | двійковий код |
десятковий код |
символ | двійковий код |
десятковий код |
символ |
| 00000000 | 0 | NUL | 01000000 | 64 | @ | 10000000 | 128 | Ђ | 11000000 | 192 | А |
| 00000001 | 1 | SOH | 01000001 | 65 | A | 10000001 | 129 | Ѓ | 11000001 | 193 | Б |
| 00000010 | 2 | STX | 01000010 | 66 | B | 10000010 | 130 | ‚ | 11000010 | 194 | В |
| 00000011 | 3 | ETX | 01000011 | 67 | C | 10000011 | 131 | ѓ | 11000011 | 195 | Г |
| 00000100 | 4 | EOT | 01000100 | 68 | D | 10000100 | 132 | „ | 11000100 | 196 | Д |
| 00000101 | 5 | ENQ | 01000101 | 69 | E | 10000101 | 133 | … | 11000101 | 197 | Е |
| 00000110 | 6 | ACK | 01000110 | 70 | F | 10000110 | 134 | † | 11000110 | 198 | Ж |
| 00000111 | 7 | BEL | 01000111 | 71 | G | 10000111 | 135 | ‡ | 11000111 | 199 | З |
| 00001000 | 8 | BS | 01001000 | 72 | H | 10001000 | 136 | € | 11001000 | 200 | І |
| 00001001 | 9 | HT | 01001001 | 73 | I | 10001001 | 137 | ‰ | 11001001 | 201 | Й |
| 00001010 | 10 | LF | 01001010 | 74 | J | 10001010 | 138 | Љ | 11001010 | 202 | До |
| 00001011 | 11 | VT | 01001011 | 75 | K | 10001011 | 139 | ‹ | 11001011 | 203 | Л |
| 00001100 | 12 | FF | 01001100 | 76 | L | 10001100 | 140 | Њ | 11001100 | 204 | М |
| 00001101 | 13 | CR | 01001101 | 77 | M | 10001101 | 141 | Ќ | 11001101 | 205 | Н |
| 00001110 | 14 | SO | 01001110 | 78 | N | 10001110 | 142 | Ћ | 11001110 | 206 | Про |
| 00001111 | 15 | SI | 01001111 | 79 | O | 10001111 | 143 | Џ | 11001111 | 207 | П |
| 00010000 | 16 | DLE | 01010000 | 80 | P | 10010000 | 144 | ђ | 11010000 | 208 | Р |
| 00010001 | 17 | DC1 | 01010001 | 81 | Q | 10010001 | 145 | ‘ | 11010001 | 209 | З |
| 00010010 | 18 | DC2 | 01010010 | 82 | R | 10010010 | 146 | ’ | 11010010 | 210 | Т |
| 00010011 | 19 | DC3 | 01010011 | 83 | S | 10010011 | 147 | “ | 11010011 | 211 | У |
| 00010100 | 20 | DC4 | 01010100 | 84 | T | 10010100 | 148 | ” | 11010100 | 212 | Ф |
| 00010101 | 21 | NAK | 01010101 | 85 | U | 10010101 | 149 | 11010101 | 213 | Х | |
| 00010110 | 22 | SYN | 01010110 | 86 | V | 10010110 | 150 | – | 11010110 | 214 | Ц |
| 00010111 | 23 | ETB | 01010111 | 87 | W | 10010111 | 151 | - | 11010111 | 215 | Ч |
| 00011000 | 24 | CAN | 01011000 | 88 | X | 10011000 | 152 | |
11011000 | 216 | Ш |
| 00011001 | 25 | EM | 01011001 | 89 | Y | 10011001 | 153 | ™ | 11011001 | 217 | Щ |
| 00011010 | 26 | SUB | 01011010 | 90 | Z | 10011010 | 154 | љ | 11011010 | 218 | ред |
| 00011011 | 27 | ESC | 01011011 | 91 | [ | 10011011 | 155 | › | 11011011 | 219 | И |
| 00011100 | 28 | FS | 01011100 | 92 | \ | 10011100 | 156 | њ | 11011100 | 220 | Ь |
| 00011101 | 29 | GS | 01011101 | 93 | ] | 10011101 | 157 | ќ | 11011101 | 221 | Е |
| 00011110 | 30 | RS | 01011110 | 94 | ^ | 10011110 | 158 | ћ | 11011110 | 222 | Ю |
| 00011111 | 31 | US | 01011111 | 95 | _ | 10011111 | 159 | џ | 11011111 | 223 | Я |
| 00100000 | 32 | 01100000 | 96 | ` | 10100000 | 160 | |
11100000 | 224 | а | |
| 00100001 | 33 | ! | 01100001 | 97 | a | 10100001 | 161 | Ў | 11100001 | 225 | б |
| 00100010 | 34 | " | 01100010 | 98 | b | 10100010 | 162 | ў | 11100010 | 226 | в |
| 00100011 | 35 | # | 01100011 | 99 | c | 10100011 | 163 | Ј | 11100011 | 227 | г |
| 00100100 | 36 | $ | 01100100 | 100 | d | 10100100 | 164 | ¤ | 11100100 | 228 | д |
| 00100101 | 37 | % | 01100101 | 101 | e | 10100101 | 165 | Ґ | 11100101 | 229 | е |
| 00100110 | 38 | & | 01100110 | 102 | f | 10100110 | 166 | ¦ | 11100110 | 230 | ж |
| 00100111 | 39 | " | 01100111 | 103 | g | 10100111 | 167 | § | 11100111 | 231 | з |
| 00101000 | 40 | ( | 01101000 | 104 | h | 10101000 | 168 | Е | 11101000 | 232 | і |
| 00101001 | 41 | ) | 01101001 | 105 | i | 10101001 | 169 | © | 11101001 | 233 | й |
| 00101010 | 42 | * | 01101010 | 106 | j | 10101010 | 170 | Є | 11101010 | 234 | до |
| 00101011 | 43 | + | 01101011 | 107 | k | 10101011 | 171 | « | 11101011 | 235 | л |
| 00101100 | 44 | , | 01101100 | 108 | l | 10101100 | 172 | ¬ | 11101100 | 236 | м |
| 00101101 | 45 | - | 01101101 | 109 | m | 10101101 | 173 | ¬ | 11101101 | 237 | н |
| 00101110 | 46 | . | 01101110 | 110 | n | 10101110 | 174 | ® | 11101110 | 238 | про |
| 00101111 | 47 | / | 01101111 | 111 | o | 10101111 | 175 | Ї | 11101111 | 239 | п |
| 00110000 | 48 | 0 | 01110000 | 112 | p | 10110000 | 176 | ° | 11110000 | 240 | р |
| 00110001 | 49 | 1 | 01110001 | 113 | q | 10110001 | 177 | ± | 11110001 | 241 | з |
| 00110010 | 50 | 2 | 01110010 | 114 | r | 10110010 | 178 | І | 11110010 | 242 | т |
| 00110011 | 51 | 3 | 01110011 | 115 | s | 10110011 | 179 | і | 11110011 | 243 | у |
| 00110100 | 52 | 4 | 01110100 | 116 | t | 10110100 | 180 | ґ | 11110100 | 244 | ф |
| 00110101 | 53 | 5 | 01110101 | 117 | u | 10110101 | 181 | µ | 11110101 | 245 | х |
| 00110110 | 54 | 6 | 01110110 | 118 | v | 10110110 | 182 | ¶ | 11110110 | 246 | ц |
| 00110111 | 55 | 7 | 01110111 | 119 | w | 10110111 | 183 | · | 11110111 | 247 | ч |
| 00111000 | 56 | 8 | 01111000 | 120 | x | 10111000 | 184 | е | 11111000 | 248 | ш |
| 00111001 | 57 | 9 | 01111001 | 121 | y | 10111001 | 185 | № | 11111001 | 249 | щ |
| 00111010 | 58 | : | 01111010 | 122 | z | 10111010 | 186 | є | 11111010 | 250 | ь |
| 00111011 | 59 | ; | 01111011 | 123 | { | 10111011 | 187 | » | 11111011 | 251 | и |
| 00111100 | 60 | < | 01111100 | 124 | | | 10111100 | 188 | ј | 11111100 | 252 | ь |
| 00111101 | 61 | = | 01111101 | 125 | } | 10111101 | 189 | Ѕ | 11111101 | 253 | е |
| 00111110 | 62 | > | 01111110 | 126 | ~ | 10111110 | 190 | ѕ | 11111110 | 254 | ю |
| 00111111 | 63 | ? | 01111111 | 127 | DEL | 10111111 | 191 | ї | 11111111 | 255 | я |
Мал. 22.4. Кодова сторінка Windows-1251
Unicode - стандарт кодування символів, що дозволяє представити знаки майже всіх письмових мов. Стандарт був запропонований в 1991 р некомерційною організацією «Консорціум Юнікоду» (англ. Unicode Consortium, Unicode Inc.). Застосування цього стандарту дозволяє закодувати більше число символів (чим в ASCII і інших кодуваннях) за рахунок двухбайтового кодування символів (всього 65536 символів). У документах Unicode можуть сусідити китайські ієрогліфи, математичні символи, букви грецького алфавіту, латиниці і кирилиці.
Коди в стандарті Unicode розділені на кілька розділів. Перші 128 кодів відповідають кодуванні ASCII. Далі розташовані розділи букв різних писемностей, знаки пунктуації та технічні символи. Зокрема прописних і рядкових букв російського алфавіту відповідають коди 1025 (Е), 1040-1103 (А-я) і 1105 (е).
шрифт Брайля - рельєфно-крапковий тактильний шрифт, призначений для письма і читання незрячими людьми. Був розроблений в 1824 р французом Луї Брайлем (Louis Braille), сином шевця. Луї у віці трьох років втратив зір, в результаті запалення очей, що почався від того, що хлопчик поранився шорний ножем (подобу шила) в майстерні батька. У віці 15 років він створив свій рельєфно-крапковий шрифт, надихнувшись простотою «нічного шрифту» капітана артилерії Шарля Барб'є (Charles Barbier), який використовувався військовими того часу для читання повідомлень у темряві.
Для зображення символів (в основному букв і цифр) в шрифті Брайля використовуються 6 точок, розташованих у два стовпці, по 3 в кожному.

Мал. 22.5. нумерація точок
Кожному символу відповідає свій унікальний набір опуклих точок. Т.ч. шрифт Брайля являє собою систему для кодування 2 6 = 64 символів. Але присутність в шрифті керуючих символів (наприклад, перехід до букв або цифр) дозволяє збільшити кількість кодованих символів.
| керуючі символи | |||
| символ шрифту Брайля |
призначення | ||
| ⠠ | букви | ||
| ⠼ | цифри | ||
| Букви, цифри і інші символи | |||
| символ шрифту Брайля |
латинські літери |
Російські літери |
цифри |
| ⠁ | A | А | 1 |
| ⠃ | B | Б | 2 |
| ⠉ | C | Ц | 3 |
| ⠙ | D | Д | 4 |
| ⠑ | E | Е | 5 |
| ⠋ | F | Ф | 6 |
| ⠛ | G | Г | 7 |
| ⠓ | H | Х | 8 |
| ⠊ | I | І | 9 |
| ⠚ | J | Ж | 0 |
| ⠅ | K | До | |
| ⠇ | L | Л | |
| ⠍ | M | М | |
| ⠝ | N | Н | |
| ⠕ | O | Про | |
| ⠏ | P | П | |
| ⠟ | Q | Ч | |
| ⠗ | R | Р | |
| ⠎ | S | З | |
| ⠞ | T | Т | |
| ⠥ | U | У | |
| ⠧ | V | ||
| ⠺ | W | В | |
| ⠭ | X | Щ | |
| ⠽ | Y | ||
| ⠵ | Z | З | |
| ⠡ | Е | ||
| ⠯ | Й | ||
| ⠱ | Ш | ||
| ⠷ | ред | ||
| ⠮ | И | ||
| ⠾ | Ь | ||
| ⠪ | Е | ||
| ⠳ | Ю | ||
| ⠫ | Я | ||
| ⠲ | Крапка | ||
| ⠂ | кома | ||
| ⠢ | Знак питання | ||
| ⠆ | Крапка з комою | ||
| ⠤ | дефіс | ||
| пропуск | |||
Мал. 22.6. шрифт Брайля
Шрифт Брайля, останнім часом, став широко застосовуватися в суспільному житті і побуті в зв'язку з ростом уваги до людей з обмеженими можливостями.

Мал. 22.7. Напис "Sochi 2014" шрифтом Брайля на золоту медаль Паралімпійських ігор 2014.
Штрих код - графічна інформація, що наноситься на поверхню, маркування або упаковку виробів, що представляє собою послідовність чорних і білих смуг або інших геометричних фігур з метою її зчитування технічними засобами.
У 1948 р Бернард Сільвер (Bernard Silver), аспірант Інституту Технології Університету Дрекселя в Філадельфії, почув, як президент місцевої продовольчої мережі просив одного з деканів розробити систему, автоматично зчитує інформацію про продукт при його контролі. Сільвер розповів про це друзям - Норману Джозефу Вудланд (Norman Joseph Woodland) і Джордін Джохенсону (Jordin Johanson). Утрьох вони почали досліджувати різні системи маркування. Їх перша працююча система використовувала ультрафіолетові чорнило, але вони були досить дороги, а крім того, з часом вицвітають.
Переконаний в тому, що система реалізована, Вудланд покинув Філадельфію і перебрався до Флориди в квартиру свого батька для продовження роботи. 20 жовтня 1949 р Вудланд і Сільвер подали заявку на винахід, яка була задоволена 7 жовтня 1952 р Замість звичних нам ліній патент містив опис штрихкодового системи у вигляді концентричних кіл.

Мал. 22.8. Патент системи Вудланд і Сільвера з концентричними колами, попередниками сучасних штрихкодів
Вперше штрих-коди почали офіційно використовуватися в 1974 р в магазинах м Трой, штат Огайо. Системи штрихового кодування знайшли широке застосування в суспільному житті: торгівля, поштові відправлення, фінансові та судові повідомлення, облік одиниць зберігання, ідентифікація осіб, контактна інформація (веб-посилання, адреси електронної пошти, номери телефонів) і т.д.
Розрізняють лінійні (читаються в одному напрямку) і двовимірні штрих-коди. Кожна з різновидів різниться як розмірами графічного зображення, так і обсягами представленої інформації. У наступній таблиці наведено приклади деяких різновидів штрих-коду.
Таблиця 22.1. різновиди штрихкодів
| Найменування | Приклад штрих-коду | Примітки |
| лінійні | ||
| Universal Product Code, UPC (Універсальний код товару) |
 (UPC-A) |
Американський стандарт штрихкоду, призначений для кодування ідентифікатора товару і виробника. Є різновиди: - UPC-E - кодуються 8 цифр; - UPC-A - кодується 13 цифр. |
| European Article Number, EAN (Європейський номер товару) |
 (EAN-13) |
Європейський стандарт штрихкоду, призначений для кодування ідентифікатора товару і виробника. Є різновиди: - EAN-8 - кодуються 8 цифр; - EAN 13 - кодується 13 цифр; - EAN-128 - кодується будь-яку кількість букв і цифр, об'єднаних в регламентовані групи. ДСТУ ISO / IEC 15420-2001 «Автоматична ідентифікація. Кодування штрихове. Специфікація символіки EAN / UPC (ЄАН / ЮПіСі) ». |
| Code 128 (Код 128) |
 |
Включає в себе 107 символів. З яких 103 символу даних, 3 стартових, і 1 зупинний символ. Для кодування всіх 128-ми символів ASCII передбачено три комплекти символів - A, B і C, які можуть використовуватися всередині одного штрих-коду. EAN-128 кодує інформацію за алфавітом Code 128 ГОСТ 30743-2001 (ISO / IEC 15417-2000) «Автоматична ідентифікація. Кодування штрихове. Специфікація символіки Code 128 (Код 128) ». |
| двовимірні | ||
| DataMatrix (Матричні дані) |
 |
Максимальна кількість символів, які поміщаються в один код - 2048 байт. ДСТУ ISO / IEC 16022-2008 «Автоматична ідентифікація. Кодування штрихове. Специфікація символіки Data Matrix ». |
| QR-код (Англ. Quick response - швидкий відгук) |
 |
Квадрати в кутах зображення дозволяють нормалізувати розмір зображення і його орієнтацію, а також кут, під яким сенсор відноситься до поверхні зображення. Точки переводяться в двійкові числа з перевіркою контрольної суми. Максимальна кількість символів, які поміщаються в один QR-код: - цифри - 7089; - цифри і букви (латиниця) - 4296; - двійковий код - 2953 байт; - ієрогліфи - 1817. |
| MaxiCode (Максікод) |
 |
Розмір - дюйм на дюйм (1 дюйм = 2.54 см). Використовується для грузоотправітельних і вантажоприймальних систем. ГОСТ Р 51294.6-2000 «Автоматична ідентифікація. Кодування штрихове. Специфікація символіки MaxiCode (Максікод) ». |
| PDF147 (Англ. Portable Data File - стерпний файл даних) |
 |
Застосовується при ідентифікації особистості, обліку товарів, при здачі звітності до контролюючих органів та інших областях. Підтримує кодування до 2710 символів і може містити до 90 рядків. |
| Microsoft Tag (Мітка Microsoft) |
 |
Розроблено для розпізнавання за допомогою фотокамер, вбудованих в мобільні телефони. Може вмістити в себе стільки ж символів, що Code128. Призначений для швидкої ідентифікації та отримання на пристрій заздалегідь підготовленої інформації (веб-посилання, довільного тексту довжиною до 1000 символів, телефонного номера і т.п.), прив'язаною до коду і зберігається на сервері компанії Microsoft. Містить 13 байт плюс один додатковий біт для контролю парності. |
Подання чисел в двійковому вигляді (в комп'ютері). Як відомо, інформація, що зберігається і обробляється в комп'ютерах, представлена в двійковому вигляді. біт (Англ. binary digi t - двійкове число; також гра слів: англ. bit - шматочок, частка) - одиниця вимірювання кількості інформації, що дорівнює одному розряду в двійковій системі числення. За допомогою біта можна закодувати (уявити, розрізняти) два стани (0 або 1; так чи ні). Збільшуючи кількість бітів (розрядів), можна збільшити кількість кодованих станів. Наприклад, для байта (англ. Byte), що складається з 8 бітів, кількість кодованих станів становить 2 8 = 256.
Числа кодуються в т.зв. форматах з фіксованою і плаваючою комою.
1. Формат з фіксованою комою, В основному, застосовується для цілих чисел, але може застосовуватися і для дійсних чисел, у яких фіксоване кількість десяткових знаків після коми. Для цілих чисел мається на увазі, що «кома» знаходиться праворуч після молодшого біта (розряду), тобто поза розрядної сітки. В даному форматі існують два подання: беззнаковое (для невід'ємних чисел) і зі знаком.
для беззнакового уявлення все розряди відводяться під уявлення самого числа. Наприклад, за допомогою байта можна уявити беззнакові цілі числа від 0 10 до 255 10 (00000000 2 - 11111111 2) або речові числа з одним десятковим знаком від 0.0 10 до 25.5 10 (00000000 2 - 11111111 2). для знакового уявлення, тобто позитивних і негативних чисел, старший розряд відводиться під знак (0 - позитивне число, 1 - негативне).
Розрізняють прямий, зворотний і додатковий коди записи знакових чисел.
В прямому коді запис позитивного і негативного числа виконується так само, як і в беззнакову уявлення (за виключення того, що старший розряд відводиться під знак). Таким чином, числа 5 10 і -5 10 записуються, як 00000101 2 і 10000101 2. У прямому коді є два коду числа 0: «позитивний нуль» 00000000 2 і «негативний нуль» 10000000 2.
При використанні зворотного коду негативне число записується у вигляді інвертованого позитивного числа (0 змінюються на 1 і навпаки). Наприклад, числа 5 10 і -5 10 записуються, як 00000101 2 і 11111010 2. Слід зазначити, що в зворотному коді, як і в прямому, є «позитивний нуль» 00000000 2 і «негативний нуль» 11111111 2. Застосування зворотного коду дозволяє відняти одне число з іншого, використовуючи операцію складання, тобто віднімання двох чисел X - Y замінюється їх сумою X + (-Y). При цьому використовуються два додаткових правила:
Від'ємник число інвертується (подається у вигляді зворотного коду);
Якщо кількість розрядів результату виходить більше, ніж відведено на уявлення чисел, то крайній лівий розряд (старший) відкидається, а до результату додається 1 2.
У наступній таблиці наведено приклади вирахування.
Таблиця 22.2. Приклади віднімання двох чисел з використанням зворотного коду
| X - Y | 5 – 5 | 6 – 5 | 5 – 6 | 5 – (-6) |
| X 2 | 00000101 | 00000110 | 00000101 | 00000101 |
| Y 2 | 00000101 | 00000101 | 00000110 | 11111001 |
| заміна складанням | 5 + (-5) | 6 + (-5) | 5 + (-6) | 5 + 6 |
| Зворотний код для від'ємника (-Y 2) | 11111010 | 11111010 | 11111001 | 00000110 |
| додавання | 00000101 + 11111010 11111111 |
00000110 + 11111010 100000000 |
00000101 + 11111001 11111110 |
00000101 + 00000110 00001011 |
| не вимагається | 00000000 + 00000001 00000001 |
не вимагається | не вимагається | |
| результат | -0 | 1 | -1 | 11 |
Незважаючи на те, що зворотний код значно спрощує обчислювальні процедури, а відповідно і швидкодію комп'ютерів, наявність двох «нулів» та інші умовності привели до появи додаткового коду. При поданні негативного числа його модуль спочатку інвертується, як в зворотному коді, а потім до інверсії відразу додається 1 2.
У наступній таблиці наведено деякі числа в різному кодовому поданні.
Таблиця 22.3. Подання чисел в різних кодах
| десяткове уявлення |
Код двійкового представлення (8 біт) | ||
| прямий | зворотний | додатковий | |
| 127 | 01111111 | 01111111 | 01111111 |
| 6 | 00000110 | 00000110 | 00000110 |
| 5 | 00000101 | 00000101 | 00000101 |
| 1 | 00000001 | 00000001 | 00000001 |
| 0 | 00000000 | 00000000 | 00000000 |
| -0 | 10000000 | 11111111 | --- |
| -1 | 10000001 | 11111110 | 11111111 |
| -5 | 10000101 | 11111010 | 11111011 |
| -6 | 10000110 | 11111001 | 11111010 |
| -127 | 11111111 | 10000000 | 10000001 |
| -128 | --- | --- | 10000000 |
При поданні негативних чисел в додаткових кодах друге правило дещо спрощується - якщо кількість розрядів результату виходить більше, ніж відведено на уявлення чисел, то тільки відкидається крайній лівий розряд (старший).
Таблиця 22.4. Приклади віднімання двох чисел з використанням додаткового коду
| X - Y | 5 – 5 | 6 – 5 | 5 – 6 | 5 – (-6) |
| X 2 | 00000101 | 00000110 | 00000101 | 00000101 |
| Y 2 | 00000101 | 00000101 | 00000110 | 11111010 |
| заміна складанням | 5 + (-5) | 6 + (-5) | 5 + (-6) | 5 + 6 |
| Додатковий код для від'ємника (-Y 2) | 11111011 | 11111011 | 11111010 | 00000110 |
| додавання | 00000101 + 11111011 00000000 |
00000110 + 11111011 100000001 |
00000101 + 11111010 11111111 |
00000101 + 00000110 00001011 |
| Відкидання старшого розряду і додавання 1 2 | не вимагається | 00000001 | не вимагається | не вимагається |
| результат | -0 | 1 | -1 | 11 |
Можна заперечити, що уявлення чисел в додаткових кодах вимагає на одну операцію більше (після інверсії завжди потрібно складання з 1 2), що може і не знадобитися в подальшому, як в прикладах із зворотними кодами. В даному випадку спрацьовує відомий «принцип чайника». Краще зробити процедуру лінійної, ніж застосовувати в ній правила «Якщо A то B» (навіть якщо воно одне). Те, що з людської точки зору здається збільшенням трудовитрат (обчислювальної та тимчасової складності), з точки зору програмно-технічної реалізації може виявитися ефективніше.
Ще одна з переваг додаткового коду перед зворотним полягає в можливості подання до одиниці інформації на одне число (стан) більше, за рахунок виключення «негативного нуля». Тому, як правило, діапазон представлення (зберігання) для знакових цілих чисел довжиною один байт становить від +127 до -128.
2. Формат з плаваючою комою, В основному, використовується для дійсних чисел. Число в даному форматі представляється в експоненційному вигляді
X = e n * m, (22.1)
де e - підстава показовою функції;
n - порядок заснування;
e n - характеристика числа;
m - мантиса (лат. mantissa - надбавка) - множник, на який треба помножити характеристику числа, щоб отримати саме число.
Наприклад, число десяткове число 350 може бути записано, як 3.5 * 10 2, 35 * 10 1, 350 * 10 0 і т.д. В нормализованной наукової записи, порядок n вибирається такий, щоб абсолютна величина m залишалася менше одиниці, але строго менше десяти (1? | m |< 10). Таким образом, в нормализованной научной записи число 350 выглядит, как 3.5 * 10 2 . При отображении чисел в программах, учитывая, что основание равно 10, их записывают в виде m E ± n, Де Е означає «* 10 ^» ( «... помножити на десять в ступені ...»). Наприклад, число 350 - 3.5Е + 2, а число 0.035 - 3.5Е-2.
Так як числа зберігається і обробляється в комп'ютерах в двійковому вигляді, то для цих цілей приймається e = 2. Однією з можливих форм двійкового представлення чисел з плаваючою комою є наступна.
Мал. 22.9. Двійковий формат уявлення чисел з плаваючою комою
Біти bn ± і bm ±, які означають знак порядку та мантиси, кодуються аналогічно числах з фіксованою комою: для позитивних чисел «0», для негативних - «1». Значення порядку вибирається таким чином, щоб величина цілої частини мантиси в десятковому (і відповідно в довічним) поданні дорівнювала «1», що буде відповідати нормализованной записи для двійкових чисел. Наприклад, для числа 350 10 порядок n = 8 10 = 001000 2 (350 = 1.3671875 * 2 8), а для 576 10 - n = 9 10 = 001001 2 (576 = 1.125 * 2 9). Бітове представлення величини порядку може бути виконано в прямому, зворотному або додатковому коді (наприклад, для n = 8 10 бінарний вигляд 001000 2). Величина мантиси відображає дробову частину. Для її перетворення в двійковий вигляд, вона послідовно множиться на 2, поки не стане рівною 0. Наприклад,

Мал. 22.10. Приклад отримання дробової частини в бінарному вигляді
Цілі частини, одержувані в результаті послідовного множення, і являють собою двійковий вид дробової частини (0.3671875 10 = 0101111 2). Частина, що залишилася розрядів величини мантиси заповнюється 0. Таким чином, підсумковий вид числа 350 в форматі з плаваючою комою з врахуванням думки мантиси в нормалізованої записи
Мал. 22.11. Двійковий вид числа 350
У програмно-апаратних реалізаціях арифметичних дій широко поширений стандарт представлення чисел з плаваючою точкою IEEE 2 754 (Остання редакція «754-2008 - IEEE Standard for Floating-Point Arithmetic»). Даний стандарт визначає формати з плаваючими комами для подання чисел одинарної (Англ. Single, float) і подвійний (Англ. Double) точності. Загальна структура форматів
Мал. 22.12. Загальний формат уявлення двійкових чисел в стандарті IEEE 754
Формати подання відрізняються кількістю біт (байт), що відводиться для представлення чисел, і, відповідно, точністю подання самих чисел.
Таблиця 22.5. Характеристики форматів представлення двійкових чисел в стандарті IEEE 754
| формат | single | double |
| Загальний розмір, біт (байт) | 32 (4) | 64 (8) |
| Число біт для порядку | 8 | 11 |
| Число біт для мантиси (Без урахування знакового біта) |
23 | 52 |
| величина порядку | 2 128 .. 2 -127 (± 3.4 * 10 38 .. 1.7 * 10 -38) |
2 1024 .. 2 -1023 (± 1.8 * 10 308 .. 9.0 * 10 -307) |
| зсув порядку | 127 | 1023 |
| Діапазон представлення чисел (Без урахування знака) |
± 1.4 * 10 -45 .. 3.4 * 10 38 | ± 4.9 * 10 -324 .. 1.8 * 10 308 |
| Кількість значущих цифр числа (не більше) |
8 | 16 |
Особливістю представлення чисел за стандартом IEEE є відсутність біта під знак порядку. Незважаючи на це, величина порядку може приймати як позитивні значення, так і негативні. Цей момент враховується т.зв. «Зміщенням порядку». Після перетворення двійкового виду порядку (записаного в прямому коді) в десятковий від отриманої величини віднімається «зсув порядку». В результаті виходить «справжнє» значення порядку числа. Наприклад, якщо для числа одинарної точності зазначений порядок 11111111 2 (= 25510), то величина порядку насправді 128 10 (= 255 10 - 127 10), а якщо 00000000 2 (= 0 10), то -127 10 (= 0 10 - 127 10).
Величина мантиси вказується, як і в попередньому випадку, в нормалізованому вигляді.
C урахуванням вищевикладеного, число 350 10 в форматі одинарної точності стандарту IEEE 754 записується в такий спосіб.
Мал. 22.13. Двійковий вид числа 350 за стандартом IEEE
До інших особливостей стандарту IEEE відноситься можливість подання спеціальних чисел. До них відносяться значення NaN (англ. Not a Number - не числом) і +/- INF (англ. Infinity - нескінченність), які утворюються в результаті операцій типу поділу на нуль. Також сюди потрапляють денормалізовані числа, у яких мантиса менше одиниці.
На закінчення по числах з плаваючою комою кілька слів про горезвісну « помилку округлення». Оскільки в двійковій формі уявлення числа зберігається тільки декілька значущих цифр, вона не може «покрити» все різноманіття дійсних чисел в заданому діапазоні. В результаті, якщо число неможливо точно уявити в двійковій формі, воно представляється найближчим можливим. Наприклад, якщо до числа типу double «0.0» послідовно додавати «1.7», то можна виявити наступну «картину» зміни значень.
0.0
1.7
3.4
5.1
6.8
8.5
10.2
11.899999999999999
13.599999999999998
15.299999999999997
16.999999999999996
18.699999999999996
20.399999999999995
22.099999999999994
23.799999999999994
25.499999999999993
27.199999999999992
28.89999999999999
30.59999999999999
32.29999999999999
33.99999999999999
35.699999999999996
37.4
39.1
40.800000000000004
42.50000000000001
44.20000000000001
45.90000000000001
47.600000000000016
…
Мал. 22.14. Результат послідовного додавання числа 1.7 (Java 7)
Інший нюанс виявляється при складанні двох чисел, у яких значно відрізняється порядок. Наприклад, результатом складання 10 10 + 10 -10 буде 10 10. Навіть якщо послідовно трильйон (10 12) раз додавати 10 -10 до 10 10, то результат залишиться тим самим 10 10. Якщо ж до 10 10 додати твір 10 -10 * 10 12, що з математичної точки зору одне і те ж, результат стане 10000000100 (1.0000000100 * 10 10).
генетичний код - властива всім живим організмам кодированная амінокислотна послідовність білків. Кодування виконується за допомогою нуклеотидів 3, що входять до складу ДНК (дезоксирибонуклеїнової кислоти). ДКН - макромолекула, що забезпечує зберігання, передачу з покоління в покоління і реалізацію генетичної програми розвитку і функціонування живих організмів. Мабуть, найголовніший код в історії людства.
У ДНК використовується чотири азотистих підстави - аденін (А), гуанін (G), цитозин (С), тимін (T), які в російськомовній літературі позначаються буквами А, Г, Ц і Т. Ці букви складають алфавіт генетичного коду. У молекулах ДНК нуклеотиди шикуються в ланцюжки і, таким чином, виходять послідовності генетичних букв.
Білки практично всіх живих організмів побудовані з амінокислот всього 20 видів. Ці амінокислоти називають канонічними. Кожен білок є ланцюжком або кілька ланцюжків амінокислот, з'єднаних в строго визначеної послідовності. Ця послідовність визначає будову білка, а, отже, все його біологічні властивості. Синтез білків (тобто реалізація генетичної інформації в живих клітинах) здійснюється на основі інформації, закладеної в ДНК. Для кодування кожної з 20 амінокислот, а також сигналу «стоп», що означає кінець білкової послідовності, достатньо трьох послідовних нуклеотидів (триплетів).

Мал. 22.15. фрагмент ДНК
2 IEEE (англ. Institute of Electrical and Electronics Engineers) - інститут інженерів з електротехніки та електроніки.
3 Містить азотистих основ, поєднане з цукром, і фосфорну кислоту.
22.3. Секретні кодові системи
Секретні коди, як і шифри, призначені для забезпечення конфіденційності інформації. Спочатку секретні кодові системи представляли собою систему, в основі якої лежало подобу жаргонного коду. Вони виникли з метою приховування імен реальних людей, згадуваних в листуванні. Це були невеликі списки, в яких в були записані приховувані імена, а навпроти них - кодові заміни (підстановки). Офіційні коди для приховування змісту повідомлень, якими користувалися папські емісари і посли середземноморських міст-держав, знайдені в ранніх архівах Ватикану, датуються XIV в. У міру зростання потреби в безпеці листування, у представників міст-держав з'явилися більш великі переліки, які включали в себе не тільки кодові заміни імен людей, а й країн, міст, видів зброї, провіанту і т.д. З метою підвищення захищеності інформації до переліків були додані шіфралфавіти для кодування слів, що не увійшли до переліку, а також правила їх використання, що базуються на різних стеганографічних та криптографічних методах. Такі збірники отримали назву « номенклатора». З XV і до середини XIX ст. вони були основною формою забезпечення конфіденційності інформації.
Аж до XVII століття в номенклатора слова відкритого тексту і їх кодові заміни йшли в алфавітному порядку, поки французький криптолог Антуан Россиньоло не запропонував використовувати більш стійкі номенклатора, що складаються з двох частин. У них існувало два розділи: в одному перераховувалися в алфавітному порядку елементи відкритого тексту, а кодові елементи були перемішані. У другій частині в алфавітному порядку йшли переліки кодів, а перемішані були вже елементи відкритого тексту.
Винахід телеграфу і абетки Морзе, а також прокладка трансатлантичного кабелю в середині XIX в. значно розширило сфери застосування секретних кодів. Крім традиційних областей їх використання (в дипломатичному листуванні і в військових цілях) вони стали широко використовуватися в комерції і на транспорті. Секретні кодові системи того часу в своїй назві містили слово « код»(« Код Держдепартаменту (1867 г.) »,« Американський код для окопів »,« Річкові коди: Потомак »,« Чорний код ») або« шифр»(« Шифр Держдепартаменту (1876 г.) »,« Зелений шифр »). Слід зазначити, що, незважаючи на наявність у назві слова «шифр», в основу цих систем було покладено кодування.
Розробники кодів, як і укладачі шифрів, нерідко додавали додаткові ступені захисту, щоб утруднити злом своїх кодів. Такий процес називається перешіфрованіем. В результаті секретні кодові системи поєднували в собі, як стеганографічні, так і криптографічні способи забезпечення конфіденційності інформації. Найбільш популярні з них наведені в таблиці нижче.
Таблиця 22.6. Способи забезпечення конфіденційності інформації в секретних кодових системах
| спосіб | Тип | Примітки | приклади (Кодуються слово - кодове позначення) |
| Заміна слова (словосполучення) іншим словом довільної довжини | стеганографічний | Аналог -. |
1. номенклатора міста Сієни (XV ст.): Cardinales (кардинал) - Florenus; Antonello da Furli (Антолло та Фурла) - Forte. 2. Шифр Держдепартаменту 1899 р .: Russia (Росія) - Promotes; Cabinet of Russia (Уряд Росії) - Promptings. 3. Код керівника служби зв'язку (1871 г.): 10:30 - Anna, Ida; 13th (тринадцятий) - Charles, Mason. |
| Заміна слова (словосполучення) символьним рядком фіксованої довжини | стеганографічний | Аналог -. | 1. Американський код для окопів (1918 р): Patrol (патруль) - RAL; Attack (атака) - DIT. 2. Код Держдепартаменту А-1 (1919 р): Diplomat (дипломат) - BUJOH; Diplomatic corps (дипломатичний корпус) - BEDAC. |
| Заміна слова (словосполучення) числом | стеганографічний | Аналог -. Для одного кодованого слова могли використовуватися кілька кодових позначень. |
1. номенклатора Бенджаміна Толмадж (1779 г.): Defense (оборона) - 143; Attack (атака) - 38. 2. Код мовлення для торгових суден союзників у Другій світовій війні (BAMS): острів - 36979; порт - 985. |
| Заміна слова (словосполучення) набором цифр фіксованої довжини | стеганографічний | Аналог -. | 1. Американський код для окопів (1918 р): Patrol (патруль) - 2307; Attack (атака) - 1447. 2. Американський службовий радіокод № 1 (1918 р): Oil (масло) - 001; Bad (поганий) - 642. |
| заміна букв | криптографічний | Аналоги - шифр,. Застосовувалася для слів, відсутніх у списку кодованих. |
1. номенклатора міста Сієни (XV ст.): Q -; s -. 2. номенклатора Джеймса Медісона (1781 г.): o - 527; p - 941. 3. Американський код для окопів (1918 р): a - 1 332 .. 2795 або CEW .. ZYR. Містив також 30 алфавітів шіфрозамен для перешіфрованія кодових позначень. |
| Заміна поєднання букв | криптографічний | Аналог -. Як кодового позначення могли використовуватися літери, числа, графічні позначення. |
1. номенклатора міста Сієни (XV ст.): Bb -; tt -. 2. номенклатора X-Y-Z (1737 г.): ce - 493; ab - 1 194. |
| Використання порожніх знаків | стеганографічний | Аналог -. Нічого котрі призначали (лат. Nihil importantes) символи використовувалися для заплутування криптоаналітиків. |
1. номенклатора міста Сієни (XV ст.):,. 2. Річкові коди: Потомак (1918 р): ASY. |
| Використання адитивних чисел | криптографічний | Аналог -. Аддитивное число, яке додається до числовому кодовому позначенню, служило в якості змінної частини коду (ключа). |
Шифр Держдепартаменту 1876 р .: правило «Horse» (кінь) на початку повідомлення означало, що при кодуванні наступних кодових позначень використовувалося аддитивное число 203; «Hawk» (яструб) - 100. |
| Перестановка букв (цифр) в кодових позначеннях | криптографічний | Аналог -. | Телеграфний код для забезпечення секретності при передачі телеграм (1870 г.): одне з правил наказувало перестановку останніх трьох цифр в цифровому кодовому позначенні, що складається з п'яти цифр. |
| Перестановка кодових позначень | криптографічний | Аналог -. | Шифр Держдепартаменту 1876 р .: правило «Tiger» (тигр) на початку повідомлення означало, що розкодувати повідомлення треба читати з останнього слова по перше (задом-наперед); «Tapir» (тапір) - міняючи місцями кожну пару слів (тобто перше і друге, третє і четверте і т.д.). |
Поєднання різних способів кодування і перешифровки в кодової системі було звичайною практикою у розробників кодів і стало застосовуватися практично з самого початку їх появи. Так, ще в номенклаторі, використовувався в м Сієна в XV в., Крім кодових замін слів, застосовувалися для заміни букв, їх і порожніх знаків. Найбільшого розквіту ця практика отримала в кінці XIX - початку XX ст. Зокрема в «шифр Держдепартаменту 1876 г.» (англ. Red Book - Червона книга), що складається з 1200 сторінок, і його додатку «не піддаються декодуванню код: додаток до шифру Держдепартаменту» застосовувалися:
Кодові позначення у вигляді слів і чисел;
10. Види кодування інформації.
Код - умовне позначення об'єкта знаком або групою знаків за певними правилами. Після присвоєння кодів створюється класифікатор - систематизований звід однорідних найменувань та їх кодових позначень. Класифікатори мають подвійне застосування. Перше - для ручного проставлення кодів в документах. У другому випадку застосування кодів передбачається зберігання всіх класифікаторів в пам'яті машини, на машинних носіях. Коди можуть бути цифровими, літерними, буквено-цифровими і складатися з одного або декількох знаків.
кодування інформації - подання відомостей в стандартній формі. Одні і ті ж відомості можуть бути представлені в декількох різних формах, і навпаки, різні відомості можна уявити в схожій формі. Наприклад, можна використовувати словесний опис нової марки автомобіля, а можна уявити його вигляд в декількох детальних фотографіях. Інший приклад - медичні довідки однієї форми мають однаковий зовнішній вигляд, але описують різні хвороби, так як видані різним людям.
З появою комп'ютерів виникла необхідність кодування всіх видів інформації, з якою має справу і окрема людина і все людство в цілому. Але вирішувати завдання кодування інформації людство почало задовго до появи комп'ютерів: грандіозні досягнення людства - писемність і арифметика - не що інше, як системи кодування мови і числовий інформації.
кодування чисел
Щоб використовувати числа, потрібно їх якось називати і записувати, потрібна система нумерації. Різні системи рахунку і записи чисел тисячоліттями співіснували і змагалися між собою, але до кінця "докомпьютерной епохи" особливу роль при рахунку стало грати число "десять", а найпопулярнішою системою кодування виявилася позиційна десяткова система. У цій системі значення цифри в числі залежить від її місця (позиції) всередині числа. Десяткова система числення прийшла з Індії (не пізніше VI століття нашої ери). Алфавіт цієї системи: (0, 1, 2, 3, 4, 5, 6, 7, 8, 9) - всього 10 цифр, таким чином, підстава системи числення - 10. Число записується як комбінація одиниць, десятків, сотень, тисяч і так далі. Приклад: 1998 = 8 * 10 0 + 9 * 10 1 + 9 * 10 2 + 1 * 10 3.
У Вавилоні, наприклад, використовувалася 60-річної системі числення, алфавіт містив цифри від 1 до 59, числа 0 не було, таблиці множення були дуже громіздкими, тому дуже скоро вона була забута, але відгомони її колишньої поширеності можна спостерігати і зараз - розподіл години на 60 хвилин, розподіл кола на 360 градусів.
Двійкова система числення
Двійкова система числення була придумана математиками і філософами ще до появи комп'ютерів (XVII - XIX ст.). Пізніше двійкова система була забута, і тільки в 1936 - 1938 роках американський інженер і математик Клод Шеннон знайшов чудові застосування двійкової системи при конструюванні електронних схем.
Існують системи числення, споріднені двійковій. При роботі з комп'ютерами іноді доводиться мати справу з двійковими числами, так як двійкові числа закладені в конструкцію комп'ютера. Двійкова система зручна для комп'ютера, але незручна для людини - занадто довгі числа незручно записувати і запам'ятовувати. На допомогу приходять системи числення, споріднені двійковій - восьмерична і шістнадцяткова.
Наприклад, в шістнадцятковій системі для запису чисел призначені 10 арабських цифр і букви латинського алфавіту (А, В, С, D, Е, F). Щоб записати число в цій системі числення, зручно скористатися двійковим поданням числа. Візьмемо для прикладу той же число - 2000 або 11111010000 в двійковій системі. Розіб'ємо його на четвірки знаків, рухаючись справа наліво, в останній четвірці зліва пріпішем незначний 0, щоб кількість знаків в тріади було по чотири: 0111 тисячі сто один 0000. Почнемо переклад - числу 0111 в двійковій системі відповідає число 7 в десяткового (7 +10 = 1 * 2 0 + 1 * 2 1 + 1 * 2 2), в шістнадцятковій системі числення цифра 7 є; числу +1101 в двійковій системі відповідає число 13 в десяткового (13 = 1 * 2 0 + 0 * 2 1 + 1 * 2 2 + 1 * 2 3), в шістнадцятковій системі цього числа відповідає цифра D, і, нарешті, число 0000 - в будь-якій системі числення 0. Запишемо тепер результат:
11111010000 2 = 7D0 16.
кодування координат
Закодувати можна не тільки числа, а й іншу інформацію. Наприклад, інформацію про те, де знаходиться певний об'єкт. Величини, що визначають положення об'єкта в просторі, називаються координатами. В будь-який системі координат є початок відліку, одиниця виміру, масштаб, напрям відліку, або осі координат. Приклади систем координат - декартові координати, полярна система координат, шахи, географічні координати.
кодування тексту
Текст закодувати досить просто. Для цього достатньо як-небудь перенумерувати всі букви, цифри, знаки пунктуації та інші, які використовуються при листі символи. Для зберігання одного символу найчастіше використовується восьмирозрядна осередок - один байт, іноді два байта (ієрогліфи, наприклад). В байт можна записати 256 різних чисел, значить, це дозволить закодувати 256 різних символів. Відповідність символів та їх кодів задається в спеціальній таблиці. Коди записуються в шістнадцятковій системі, так як для запису числа з восьми розрядів потрібно всього дві шістнадцятирічних цифри.
кодування зображень
Цифрові персональні комп'ютери добре працюють з числами, але не вміють обробляти безперервні величини. Але людське око можна обдурити: зображення, складене з великого числа окремих дрібних деталей, сприймається як безперервне. Якщо розбити картинку вертикальними і горизонтальними лініями на маленькі мозаїчні квадратики, отримаємо так званий растр - двовимірний масив квадратиків. Самі квадратики - елементи растра або пікселі (Picture "s element) - елементи картинки. Колір кожного пікселя кодується числом.
Урок "Кодування інфомація".
Інформацію один одному ми передаємо в усній і письмовій формі, а також у формі жестів і знаків.
Знаки можуть мати різну фізичну природу . Наприклад, для представлення інформації з використанням мови в письмовій формі використовуються знаки, які є зображеннями на папері або інших носіях, в усному мовленні як знаки мови використовуються різні звуки (фонеми), а при обробці тексту на комп'ютері знаки представлені у формі послідовностей електричних імпульсів ( комп'ютерних кодів ).
види інформації
Інформація, як об'єкт класифікується за видами. Таких класифікацій кілька. Кожна наука вводить свою класифікацію. Для інформатики головним є те, яким чином інформація вводиться / виводиться, обробляється, зберігається, використовуючи засоби обчислювальної техніки. Тому в інформатиці прийнято таку класифікацію видів інформації:
|
Аналогова - безперервна (Сприймається людиною) |
Дискретна - стрибкоподібне (Сприймається ВТ) |
|
|
||
|
приклади: скрипка телевізор телефон картина в музеї графіки функцій |
приклади: фортепіано монітор музичний центр мобільний телефон |
Форми подання інформації
Так як аналогову інформацію людина сприймає за допомогою своїх органів почуттів, то він прагне зафіксувати її таким чином, щоб вона стала зрозуміла іншим. При цьому одна і та ж інформація може бути представлена в різних формах.
У будь-якому вигляді інформація для нас висловлює відомості про кого-то або про щось. Вона відображає те, що відбувається або те, що сталося в нашому світі, наприклад: що ми робили вчора або будемо робити завтра, як буде виглядати випускну сукню або місце майбутньої роботи. Але при цьому інформація обов'язково повинна отримати деяку форму, найбільш зручну для сприйняття:
· текстів, малюнків, фотографій, креслень;
· жестів і міміки;
· запахів і смакових відчуттів;
· Радіохвиль;
· електричних і нервових імпульсів;
· магнітних записів;
· хромосом
Отримання інформації - це, в кінцевому рахунку, отримання фактів, відомостей і даних про властивості, структуру або взаємодії об'єктів і явищ навколишнього нас світу.
Мова як знакова система
У процесі розвитку людського суспільства люди виробили велику кількість мов. Серед них мову жестів і міміки, мова малюнків і креслень, мова музики і мову математики, розмовна мова, алгоритмічний мову і т. Д.
Для обміну інформацією з іншими людьми людина використовує природні мови (Російська, англійська, китайська та ін.), Тобто інформація може надаватися за допомогою природних мов.
Приклади алфавітів: В основі російської мови лежить кирилиця, Що містить 33 знака, англійська мова використовує латиницю (26 знаків), китайську мову використовує алфавіт з десятків тисяч знаків ( ієрогліфів).
Послідовності символів алфавіту відповідно до правил граматики утворюють основні об'єкти мови - слова. Правила, за якими утворюються пропозиції з слів даної мови, називаються синтаксисом . Необхідно відзначити, що в природних мовах граматика і синтаксис мови формулюються за допомогою великої кількості правил, з яких існують винятки, так як такі правила складалися історично.
Схема передачі інформації через писемність
|
УСНЕ МОВЛЕННЯ |
Þ |
лист |
Þ |
ТЕКСТ |
Þ |
читання |
Þ |
УСНЕ МОВЛЕННЯ |
КОДИРОВАНИЕ ДЕКОДУВАННЯ
кодування інформації
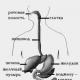
Загальна схема обміну інформацією
|
Джерело інформації |
Þ |
кодує пристрій |
Þ |
Передача інформації |
Þ |
декодер |
Þ |
одержувач інформації |
Кодування текстової інформації
|
Мови представлення інформації |
||||||||||||||
|
природні: Англійська, французька, ... |
формальні: Математики, програмування, ноти, ... |
|||||||||||||
|
кодування інформації |
||||||||||||||
|
цілі кодування |
||||||||||||||
|
засекречування інформації |
швидкий спосіб запису |
передача по технічних каналах зв'язку |
виконання математичних обчислень |
|||||||||||
|
шифрування |
стенографія |
телеграфний код |
системи числення |
|||||||||||
|
алгоритми криптографії |
Один знак - слово або поєднання букв |
код Морзе |
грец. στενός - вузький, тісний і γράφειν - писати) - спосіб письма за допомогою особливих знаків і цілого ряду скорочень, що дає можливість швидко записувати усне мовлення. Швидкість стенографічного листа перевершує швидкість звичайного в 4-7 разів. Так як вибір значків для стенографії в основному довільний, то з поєднань різних значків утворилося безліч стенографічних систем, кожна з яких має свої переваги і недоліки. Мистецтво стенографії існувало вже, як можна зробити висновок за деякими даними, у древніх єгиптян , Де умовним знаком записувалися мови фараонів ; від єгиптян це мистецтво перейшло до грекам і римлянам , У яких були скорописця. 5 грудня 63 р. До н.е. е. в Стародавньому Римі відбулося перше відоме в історії застосування стенографії. У деяких випадках виникає потреба засекречування документа або тексту. В цьому випадку текст шифрується. У давні часи зашифрований текст називався тайнописом. шифрування - спосіб перетворення відкритої інформації в закриту і назад. Застосовується для зберігання важливої інформації в ненадійних джерелах або передачі її по незахищеним каналам зв'язку. Шифрування - це теж кодування, але із засекреченим методом, відомим тільки адресату і джерела. Методами шифрування займається наука криптографія .
Домашнє завдання - придумайте або згадайте будь-яку інформацію і уявіть її в різних формах, створити схему: Створення нової мелодії
| |||||||||||
Одна і та ж інформація може бути представлена (закодована) в декількох формах. C появою комп'ютерів виникла необхідність кодування всіх видів інформації, з якими має справу і окрема людина, і людство в цілому. Але вирішувати завдання кодування інформації людство почало задовго до появи комп'ютерів. Грандіозні досягнення людства - писемність і арифметика - є не що інше, як система кодування мови і числовий інформації. Інформація ніколи не з'являється в чистому вигляді, вона завжди якось представлена, як-то закодована.
Двійкове кодування - один з найпоширеніших способів подання інформації. В обчислювальних машинах, в роботах і верстатах з числовим програмним управлінням, як правило, вся інформація, з якою має справу пристрій, кодується у вигляді слів двійкового алфавіту.
Кодування символьної (текстової) інформації.
Основна операція, вироблена над окремими символами тексту - порівняння символів.
При порівнянні символів найбільш важливими аспектами є унікальність коду для кожного символу і довжина цього коду, а сам вибір принципу кодування практично не має значення.
Для кодування текстів використовуються різні таблиці перекодування. Важливо, щоб при кодуванні і декодуванні одного і того ж тексту використовувалася одна і та ж таблиця.
Таблиця перекодування - таблиця, яка містить упорядкований певним чином перелік кодованих символів, відповідно до якої відбувається перетворення символу в його двійковий код і назад.
Найбільш популярні таблиці перекодування: ДКОИ-8, ASCII, CP1251, Unicode.
Історично склалося, що в якості довжини коду для кодування символів було обрано 8 біт або 1 байт. Тому найчастіше одному символу тексту, що зберігається в комп'ютері, відповідає один байт пам'яті.
Різних комбінацій з 0 і 1 при довжині коду 8 біт може бути 28 = 256, тому за допомогою однієї таблиці перекодування можна закодувати не більше 256 символів. При довжині коду в 2 байти (16 біт) можна закодувати 65536 символів.
Кодування числової інформації
Подібність в кодуванні числової і текстової інформації полягає в наступному: щоб можна було порівнювати дані цього типу, у різних чисел (як і у різних символів) повинен бути різний код. Основна відмінність числових даних від символьних полягає в тому, що над числами крім операції порівняння виробляються різноманітні математичні операції: додавання, множення, добування кореня, обчислення логарифма та ін. Правила виконання цих операцій в математиці детально розроблені для чисел, представлених в позиційній системі числення.
Для кодування одного символу клавіатури використовують 8 біт - один байт.
Байт - це найменша одиниця обробки інформації. За допомогою одного байта можна закодувати 2 8 = 256 символів.
Існує таблиця кодів клавіатури. Перші коди з 32 по 127 є стандартними і обов'язковими для всіх країн і всіх комп'ютерів, а в другій половині (128-255) кожна країна може створювати свій стандарт - національний. Першу половину називають таблицею ASCII (Американський стандартний код для обміну інформацією).
Є й інші таблиці кодування KOI8-U, Wsndows-1251, Unicode. З перерахованих таблиць особливою є таблиця Unicode, оскільки кожен символ цієї таблиці кодується двома байтами.
поняття файлу
У комп'ютері будь-яка інформація (тексти, числа, малюнки, звуки) представлена у вигляді послідовності байтів. Для того, щоб комп'ютер розрізняв всі види інформації, вводиться таке поняття як формат. Кожна група байтів, що представляє певну закодовану інформацію, називається файлом. Файл повинен мати унікальне ім'я певного формату. На ім'я файлу комп'ютер визначає, де файл знаходиться, яка інформація в ньому міститься, в якому форматі вона записана і якими програмами її можна обробити. Файл - найменша одиниця зберігання інформації. Файл може зберігати десятки, сотні байтів.
| Статті по темі: | |
|
Фактори що руйнують здоров'я
ДО УВАГИ ВСІХ ВЧИТЕЛІВ: згідно з Федеральним законом № 313-ФЗ все ... Протипоказання і наслідки кодування
Що таке кодування від алкоголізму? Це завершальна стадія лікування ... Як працює система ЕГАИС при торгівлі пивом
З 1 січня 2016 року для всіх підприємців змінилися правила обліку ... | |