पाठक की पसंद





लोकप्रिय लेख
कंप्यूटर की मेमोरी में सूचनाओं के संपीडन को उसका परिवर्तन कहा जाता है, जिसके कारण कोडित सामग्री को बनाए रखते हुए मेमोरी की मात्रा घट जाती है। विभिन्न डेटा प्रकारों के लिए अलग-अलग संपीड़न विधियाँ हैं। केवल के लिए ग्राफिक जानकारी का संपीड़न लगभग एक दर्जन विभिन्न तरीकों से किया जाता है। यहां हम पाठ्य सूचना को संपीड़ित करने के तरीकों में से एक को देखते हैं।
एक निरंतर वह है जो कार्यक्रम के निष्पादन के दौरान अपने मूल्य को नहीं बदलता है। यह प्रत्येक श्रेणी के लिए वर्णित तरीके से प्रस्तुत किया गया है। चर वे हैं जो प्रोग्राम निष्पादन के दौरान अपने मूल्य को बदल सकते हैं। उनका प्रतिनिधित्व आमतौर पर संख्यात्मक अक्षरों और प्रतीकों के संदर्भ में दिया जाता है, जिसके लिए एक मान असाइन किया गया है।
यदि विवरण मॉड्यूल के "घोषणाओं" खंड में दिखाई देता है, तो चर का उपयोग केवल इस प्रक्रिया में किया जा सकता है। इस चर के लिए सभी परियोजना प्रक्रियाओं के लिए उपलब्ध होने के लिए, एक सार्वजनिक निर्देश पहले खोला जाना चाहिए, जैसा कि निम्नलिखित उदाहरण में दिखाया गया है। आप एक निर्देश में कई चर घोषित कर सकते हैं। डेटा प्रकार निर्दिष्ट करने के लिए, आपको प्रत्येक चर के लिए डेटा प्रकार निर्दिष्ट करना होगा।
आठ-अंकीय वर्ण एन्कोडिंग तालिका (उदाहरण के लिए, ASCII) में, प्रत्येक वर्ण आठ बिट्स के साथ एन्कोडेड है और इसलिए, स्मृति में 1 बाइट लेता है। हमारी पाठ्यपुस्तक की धारा 1.3 ने बताया कि पाठ में विभिन्न अक्षरों (संकेतों) की घटना की आवृत्ति अलग-अलग होती है। यह भी दिखाया गया था कि प्रतीकों का सूचना भार अधिक होता है, घटना की आवृत्ति जितनी छोटी होती है। कंप्यूटर मेमोरी में पाठ को संपीड़ित करने का विचार इस परिस्थिति से जुड़ा है: सभी पात्रों को एक ही लंबाई के कोड के साथ एनकोड करने से इनकार करना। कम सूचना भार वाले वर्ण, अर्थात अक्सर सामना करना पड़ा, कम आम पात्रों की तुलना में छोटे कोड के साथ सांकेतिक शब्दों में बदलना। इस दृष्टिकोण के साथ, आप सामान्य पाठ कोड की मात्रा को काफी कम कर सकते हैं और, तदनुसार, कंप्यूटर की मेमोरी में इसके द्वारा कब्जा कर लिया गया स्थान।
आपको घोषणा में चर के डेटा प्रकार को निर्दिष्ट करने की आवश्यकता नहीं है। आप सार्वजनिक मॉड्यूल के स्तर पर चर घोषित करने के लिए एक सार्वजनिक ऑपरेटर का उपयोग कर सकते हैं। सार्वजनिक चर परियोजना में किसी भी प्रक्रिया का उपयोग कर सकते हैं। यदि सार्वजनिक चर को मानक मॉड्यूल या वर्ग मॉड्यूल में घोषित किया जाता है, तो इसका उपयोग किसी भी परियोजना में भी किया जा सकता है जो एक परियोजना को संदर्भित करता है जिसमें सार्वजनिक चर घोषित किया जाता है।
आप निजी मॉड्यूल के स्तर पर चर घोषित करने के लिए एक निजी ऑपरेटर का उपयोग कर सकते हैं। कोड को पढ़ने और व्याख्या करने में आसान बनाने के लिए आप एक निजी ऑपरेटर का उपयोग कर सकते हैं। चर में अधिकांश चर की तुलना में अधिक स्मृति संसाधनों की आवश्यकता होती है।
यह दृष्टिकोण लंबे समय से ज्ञात है। यह प्रसिद्ध मोर्स कोड में उपयोग किया जाता है, जिनमें से कई कोड तालिका में सूचीबद्ध हैं। 3.1, जहां "बिंदु" शून्य से एन्कोड किया गया है, और "डैश" - इकाई।
तालिका 3.1
|
पत्र | |||||||
जैसा कि इस उदाहरण और तालिका से देखा जा सकता है। 3.1, अधिक सामान्य अक्षरों में एक छोटा कोड होता है।
यदि यह स्पष्ट रूप से और एक विशिष्ट डेटा प्रकार के साथ चर घोषित करता है तो एक आवेदन अधिक कुशल होगा। सभी चरों की स्पष्ट घोषणा से आइटम त्रुटियों और वर्तनी त्रुटियों से जुड़ी त्रुटियों की आवृत्ति कम हो जाती है। इस निर्देश की आवश्यकता है कि आप स्पष्ट रूप से एक मॉड्यूल में सभी चर घोषित करते हैं। ध्यान रखें कि यह पैरामीटर आपके द्वारा लिखे गए मौजूदा कोड को संशोधित नहीं करता है। निश्चित सरणियों और गतिशील सरणियों को स्पष्ट रूप से घोषित किया जाना चाहिए। किसी अन्य एप्लिकेशन से ऑब्जेक्ट को प्रबंधित करने के लिए एप्लिकेशन का उपयोग करते समय, आपको किसी अन्य एप्लिकेशन के प्रकार लाइब्रेरी के लिए एक संदर्भ स्थापित करना होगा।
समान लंबाई के कोड के विपरीत, जो एएससीआईआई मानक में उपयोग किए जाते हैं, इस मामले में व्यक्तिगत अक्षरों के कोड के बीच अलगाव की समस्या है। मोर्स कोड में, इस समस्या को "ठहराव" (स्थान) की मदद से हल किया जाता है, जो वास्तव में, मोर्स वर्णमाला का तीसरा प्रतीक है, अर्थात्। मोर्स वर्णमाला दो और तीन-वर्ण नहीं है।
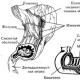
और कंप्यूटर कोडिंग के बारे में क्या है, जहां द्विआधारी वर्णमाला का उपयोग किया जाता है? विभिन्न विभाजनों के कोड बनाने के लिए सबसे सरल, लेकिन बहुत प्रभावी तरीके, जिनके लिए एक विशेष विभाजक की आवश्यकता नहीं है, वह है डी। हफ़मैन का एल्गोरिथ्म (डी.ए. हफ़मैन, 1952)। इस एल्गोरिथ्म का उपयोग करके, एक बाइनरी ट्री बनाया गया है, जो आपको विशिष्ट रूप से डिकोड करने की अनुमति देता है बाइनरी कोडविभिन्न लंबाई के वर्ण कोड से मिलकर। एक बाइनरी एक पेड़ है, जिसके प्रत्येक शीर्ष से दो शाखाएं विस्तारित होती हैं। पर अंजीर।3.2 अंग्रेजी भाषा की वर्णमाला के लिए निर्मित एक ऐसे पेड़ का उदाहरण दिखाता है, जो अपने पत्रों की घटना की आवृत्ति को ध्यान में रखता है। परिणामी कोड इस प्रकार सारणीबद्ध हो सकते हैं।
एक बार लिंक स्थापित हो जाने पर, ऑब्जेक्ट चर को उनके सबसे विशिष्ट प्रकार के अनुसार घोषित किया जा सकता है। चर घोषणा में टाइप लाइब्रेरी का नाम शामिल करें, जैसा कि निम्नलिखित उदाहरण में दिखाया गया है। आवेदन के लिए प्रलेखन। मूल्य प्रकारों का यह अपेक्षाकृत छोटा सेट आपको अपने अनुप्रयोगों के साथ उपयोगी कार्य करने की अनुमति देता है। पूर्णांकों और वास्तविक संख्याओं के बीच कोई स्पष्ट अंतर नहीं है।
जब किसी फ़ंक्शन के बाहर एक वैरिएबल घोषित किया जाता है, तो इसे ग्लोबल वैरिएबल कहा जाता है, क्योंकि यह वर्तमान दस्तावेज़ में किसी अन्य कोड के लिए उपलब्ध है। जब आप किसी फ़ंक्शन के अंदर एक चर घोषित करते हैं, तो इसे स्थानीय चर कहा जाता है, क्योंकि यह केवल उस फ़ंक्शन के भीतर उपलब्ध होता है।
तालिका 3.2
|
पत्र |
हफमैन कोड |
तालिका का उपयोग करना। 3.2 पाठ को एनकोड करना आसान है। उदाहरण के लिए, 29 वर्णों की एक स्ट्रिंग
एक स्थिर पहचानकर्ता का सिंटैक्स एक चर पहचानकर्ता के लिए समान है: इसे एक अक्षर या अंडरस्कोर से शुरू करना चाहिए और इसमें अल्फाबेटिक, न्यूमेरिक या अंडरस्कोर वर्ण शामिल होने चाहिए। स्क्रिप्ट चालू होने के दौरान एक स्थिरांक किसी मान को बदल नहीं सकता है या फिर से घोषित किया जा सकता है।
यदि कीवर्ड छोड़ा गया है, तो यह माना जाता है कि पहचानकर्ता एक चर है। आप एक ही क्षेत्र में एक फ़ंक्शन या चर के रूप में एक ही नाम के साथ एक निरंतर घोषित नहीं कर सकते। ये मान निश्चित हैं, चर नहीं जो आप अपनी स्क्रिप्ट में शाब्दिक रूप से प्रदान करते हैं।
WENEEDMOR ESNOWFORBE TTERSKIING को कोड में परिवर्तित किया गया है: 011101 100 1100 100 100 110110001111101010000 ITO 1100 1110 011101 01001 1110 1011/11100 100 001001 100 10110110 110100011 1010 1100 0001 1010 1100 00001, जिसे स्मृति में रखा गया है, जब इसे स्मृति में रखा गया है।
01110110 01100100 10011011 00011111 01011100 01101100 11100111 01010011 11010110 1110010000100110 01011011 01101000 11101010 10110000 001
इस प्रकार, Huffman एन्कोडिंग में 29 बाइट्स लेने वाला ASCII टेक्स्ट केवल 16 बाइट्स लेता है।
इस खंड में निम्नलिखित प्रकार के शाब्दिक वर्णन किए गए हैं। जब आप एक क्रमबद्ध शाब्दिक का उपयोग करके एक आदेश बनाते हैं, तो इसे इसके तत्वों के रूप में निर्दिष्ट मानों के साथ आरंभीकृत किया जाता है, और उनकी लंबाई निर्दिष्ट तर्कों की संख्या के बराबर होती है। निम्नलिखित उदाहरण तीन तत्वों और तीन की लंबाई के साथ एक कॉफी सॉर्टिंग क्रम बनाता है।
शाब्दिक छँटाई वस्तु आरंभीकरण का प्रकार है। अनुभाग "ऑब्जेक्ट इनिशियलाइज़र"। इसके अलावा, फंक्शन में इस्तेमाल होने वाले शाब्दिक को हर बार फ़ंक्शन कहा जाता है। साहित्यिक निर्देशांक भी सरणी की वस्तुएं हैं। ऐरे ऑब्जेक्ट सेक्शन में। आदेशित शाब्दिक के सभी तत्वों को निर्दिष्ट करना आवश्यक नहीं है। यदि दो कॉमा को एक स्तंभ में रखा जाता है, तो अनिर्दिष्ट वस्तुओं के लिए रिक्त स्थान के साथ एक प्रकार बनाया जाता है। निम्न उदाहरण मछली के आदेश को दर्शाता है।
उलटा समस्या - हफमैन कोड से अंग्रेजी वर्णमाला के अक्षरों में संक्रमण - एक द्विआधारी पेड़ (आंकड़ा देखें) का उपयोग करके किया जाता है। इस मामले में, ट्रांसकोडिंग पहले अंक से बाएं से दाएं पाठ को स्कैन करके होती है, जब तक कि हम पत्र के साथ अंतिम शीर्ष तक नहीं पहुंचते तब तक पेड़ के समान (बाइनरी कोड वाले) शाखाओं के साथ आगे बढ़ते हैं। कोड में पत्र का चयन करने के बाद, अगले पत्र को डिकोड करने की प्रक्रिया फिर से बाइनरी ट्री के ऊपर से शुरू होती है।
इस आदेश में दो तत्व हैं जिनमें मान और एक खाली तत्व है। यदि अंतिम अल्पविराम को आइटम की सूची के अंत में डाला जाता है, तो अल्पविराम को अनदेखा कर दिया जाता है। निम्नलिखित उदाहरण में, छंटाई की लंबाई तीन है। सूची में अन्य सभी अल्पविराम एक नए आइटम की ओर इशारा करते हैं।
केवल अंतिम अल्पविराम को अनदेखा किया जाता है। पूर्णांक दशमलव, षोडश आधारी और अष्टक में व्यक्त किया जा सकता है। एक शाब्दिक दशमलव पूर्णांक में एक अग्रणी शून्य के बिना संख्याओं का क्रम होता है। ऑक्टेल पूर्णांक में केवल 0 अंक शामिल हो सकते हैं। पूर्णांक के कुछ उदाहरण।
यह अनुमान लगाना मुश्किल नहीं है कि दर्शाया गया पेड़ हफमैन कोड का छोटा संस्करण है। पूर्ण रूप से, इसे पाठ में पाए जाने वाले सभी संभावित पात्रों को ध्यान में रखना चाहिए: रिक्त स्थान, विराम चिह्न, कोष्ठक, आदि।
पाठ को संपीड़ित करने वाले कार्यक्रमों में - अभिलेखागार, वर्णों की घटना की आवृत्ति की एक तालिका प्रत्येक संसाधित पाठ के लिए बनाई गई है, और फिर हफ़मैन कोड के विभिन्न लंबाई के कोड बनाए जाते हैं। इस मामले में, पाठ संपीड़न और भी अधिक कुशल हो जाता है, क्योंकि एन्कोडिंग विशेष रूप से इस पाठ को ट्यून किया जाता है। और पाठ जितना बड़ा होगा, संपीड़न का प्रभाव उतना ही अधिक होगा।
फ़्लोटिंग पॉइंट शाब्दिक के निम्नलिखित भाग हो सकते हैं। दशमलव पूर्णांक जिसे हस्ताक्षरित किया जा सकता है, दशमलव बिंदु, अंश, मीट्रिक। एक शाब्दिक वस्तु शून्य या अधिक संपत्ति के नामों की एक सूची है और घुंघराले ब्रेस में संलग्न संबंधित वस्तु मूल्य हैं। आपको एक बयान की शुरुआत में एक वस्तु शाब्दिक का उपयोग नहीं करना चाहिए। इससे एक त्रुटि होगी या आप अपेक्षा के अनुरूप व्यवहार नहीं करेंगे, क्योंकि यह एक ब्लॉक की शुरुआत के रूप में व्याख्या की जाएगी।
नीचे एक शाब्दिक का एक उदाहरण है। इसके अलावा, आप किसी प्रॉपर्टी या किसी नेस्टेड ऑब्जेक्ट को दूसरे के नाम देने के लिए न्यूमेरिक या स्ट्रिंग शाब्दिक का उपयोग कर सकते हैं। निम्न उदाहरण इन मापदंडों का उपयोग करता है। एक शाब्दिक स्ट्रिंग दोहरे या एकल उद्धरणों में संलग्न शून्य या अधिक वर्ण है। स्ट्रिंग को उसी प्रकार के उद्धरण से अलग किया जाना चाहिए; वह है, या तो एकल उद्धरण या दो दोहरे उद्धरण। नीचे स्ट्रिंग शाब्दिक के उदाहरण हैं।
कमके बारे में मुख्य बात
सूचना के संपीडन को उसका परिवर्तन कहा जाता है, जिसके कारण कोडित सामग्री को बनाए रखने के दौरान कब्जे वाली मेमोरी की मात्रा में कमी होती है।
एक पाठ संपीड़न विधि का विचार: एक वर्ण कोड की लंबाई घट जाती है इसके सूचना वजन के साथ, अर्थात्। पाठ में घटना की आवृत्ति में वृद्धि के साथ।
नियमित पात्रों के अतिरिक्त, आप स्ट्रिंग्स में विशेष वर्ण भी शामिल कर सकते हैं, जैसा कि निम्नलिखित उदाहरण में दिखाया गया है। तालिका 1 में सूचीबद्ध वर्णों के लिए, पिछले बैकस्लैश को अनदेखा नहीं किया गया है, लेकिन यह उपयोग पुराना है और इसे टाला जाना चाहिए।
आप इसके बैकस्लैश को निर्दिष्ट करके एक स्ट्रिंग के अंदर एक उद्धरण चिह्न डाल सकते हैं। इसे उद्धरण के रूप में जाना जाता है। एक स्ट्रिंग के अंदर शाब्दिक बैकस्लैश शामिल करने के लिए, आपको बैकस्लैश वर्ण से बचना चाहिए। आप उनके बैकस्लैश को छोड़ कर लाइन ब्रेक से भी बच सकते हैं। बैकस्लैश और लाइन ब्रेक को स्ट्रिंग मान से हटा दिया जाता है।
हफ़मैन संपीड़न एल्गोरिथ्म को एक बाइनरी ट्री के रूप में दर्शाया गया है।
एक हफ़मैन एल्गोरिथ्म का उपयोग करने वाले तीरंदाजी उनके लिए बाइनरी कोडिंग ट्री का निर्माण करते हैं हर पाठ।
प्रश्न और कार्य
स्थिर और परिवर्तनीय लंबाई के कोड के बीच अंतर क्या है?
चर लंबाई कोड कैसे पाठ संपीड़ित करते हैं?
इसमें अमेरिका, यूरोप, मध्य पूर्व, अफ्रीका, भारत, एशिया और प्रशांत भाषाओं के साथ-साथ ऐतिहासिक परिदृश्य और तकनीकी प्रतीकों को शामिल किया गया है। वह विभिन्न राष्ट्रीय चरित्र मानकों जैसे बहुभाषी कंप्यूटिंग के अंतर्राष्ट्रीयकरण की समस्याओं को हल करने की उम्मीद करता है। हालाँकि, वर्तमान में सभी आधुनिक या पुरातन लिपियों का समर्थन नहीं किया जाता है। यह प्रत्येक वर्ण के लिए एक संख्यात्मक मान और एक नाम का उपयोग करता है।
चरित्र एन्कोडिंग चरित्र के पहचानकर्ता और उसके संख्यात्मक मूल्य के साथ-साथ बिट्स में इस मूल्य के प्रतिनिधित्व को इंगित करता है। इस चर को किसी परियोजना में सभी प्रक्रियाओं के लिए उपलब्ध कराने के लिए, यह एक सार्वजनिक ऑपरेटर द्वारा पूर्ववर्ती है, जैसा कि इस उदाहरण में है। ऑपरेटर के बयान में आपको चर के प्रकार को निर्दिष्ट करने की आवश्यकता नहीं है।
ASCII और हफ़मैन कोड का उपयोग करके निम्नलिखित पाठ को एनकोड करें: HAPPYNEWYEAR। दोनों मामलों में स्मृति की आवश्यक मात्रा गिनें।
4. बाइनरी ट्री की मदद से डीकोड करें (आंकड़ा देखें) निम्न कोड:
11110111 10111100 00011100 00101100 10010011 01110100 11001111 11101101 001100
हफमैन कोडिंग के लिए उपयोग किए जाने वाले अंग्रेजी वर्णमाला के बाइनरी ट्री
आप मॉड्यूल स्तर पर सार्वजनिक चर घोषित करने के लिए एक सार्वजनिक ऑपरेटर का उपयोग कर सकते हैं। यदि सार्वजनिक चर को मानक मॉड्यूल या वर्ग मॉड्यूल में घोषित किया जाता है, तो इसका उपयोग उस परियोजना से संबंधित सभी परियोजनाओं में भी किया जा सकता है जिसमें चर घोषित किया जाता है। निजी चर का उपयोग केवल उसी मॉड्यूल में किया जा सकता है।
आप अपने कोड को पढ़ने और व्याख्या करने में आसान बनाने के लिए एक निजी ऑपरेटर का उपयोग कर सकते हैं। यदि आप स्पष्ट रूप से और एक विशिष्ट डेटा प्रकार के साथ चर घोषित करते हैं तो आपका आवेदन अधिक कुशल होगा। सभी चर की स्पष्ट घोषणा नामकरण और वर्तनी की त्रुटियों की घटना को कम करती है। इस कथन के लिए आवश्यक है कि आप स्पष्ट रूप से एक मॉड्यूल में सभी चर घोषित करें। कृपया ध्यान दें कि यह पैरामीटर पहले से लिखे गए कोड को नहीं बदलता है। आपको स्पष्ट रूप से स्थिर सरणियों और गतिशील सरणियों की घोषणा करनी चाहिए।
चर लंबाई के साथ कोड के निर्माण के लिए पहला नियम काफी स्पष्ट है। शॉर्ट कोड को अक्सर होने वाले पात्रों को सौंपा जाना चाहिए, और लंबे कोड दुर्लभ होने चाहिए। हालाँकि, एक और समस्या है। इन कोडों को सौंपा जाना चाहिए ताकि वे अस्पष्ट रूप से डिकोड किए जा सकें, और अस्पष्ट रूप से नहीं। एक छोटा सा उदाहरण इसे स्पष्ट करेगा।
चार वर्णों पर विचार करें और यदि वे समान संभाव्यता (प्रत्येक) के साथ डेटा अनुक्रम में दिखाई देते हैं, तो हम बस चार दो-बिट कोड 00, 01, 10 और 11 उन्हें असाइन करते हैं। सभी संभावनाएं समान हैं, और इसलिए चर-लंबाई कोड इस डेटा को संपीड़ित नहीं करेंगे। लघु कोड वाले प्रत्येक वर्ण के लिए, एक लंबे कोड वाला एक वर्ण होता है और प्रति वर्ण बिट्स की औसत संख्या कम से कम 2 होगी। परिवर्तनीय वर्णों के साथ डेटा अतिरेक शून्य है, और ऐसे वर्णों की स्ट्रिंग को चर लंबाई कोड (या किसी अन्य विधि द्वारा) का उपयोग करके संपीड़ित नहीं किया जा सकता है।
जब आप किसी अन्य एप्लिकेशन की वस्तुओं का प्रबंधन करने के लिए एक एप्लिकेशन का उपयोग करते हैं, तो आपको किसी अन्य एप्लिकेशन के प्रकार लाइब्रेरी का संदर्भ सेट करना होगा। लिंक को परिभाषित करने के बाद, आप सबसे विशिष्ट प्रकार के अनुसार ऑब्जेक्ट चर घोषित कर सकते हैं।
वेरिएबल डिक्लेरेशन में टाइप लाइब्रेरी का नाम इस उदाहरण में शामिल करें। आवेदन के लिए प्रलेखन। एक नाम एक शब्द है जिसका उपयोग किसी चर में निहित मूल्य को इंगित करने के लिए किया जाता है। प्रकार इंगित करता है कि कौन सा डेटा एक चर द्वारा संग्रहीत किया जा सकता है: - सीमा मूल्यों का एक सेट; - ऑपरेटर्स और बिल्ट-इन फ़ंक्शन जिन्हें मूल्य सेट के तत्वों पर लागू किया जा सकता है। चरों के लिए, हम एक अज्ञात मूल्य को संग्रहीत करने के लिए उपयोग किए जाने वाले मेमोरी क्षेत्र के रूप में सोच सकते हैं। इसके अलावा, डेवलपर को डेटा के स्थान को स्पष्ट रूप से इंगित नहीं करना चाहिए। यह केवल इस मेमोरी क्षेत्र से जुड़े नाम को इंगित करता है। इस जगह के लिए पता तथाकथित नाम से निर्धारित होता है। उदाहरण के लिए, आइए उत्पाद बेचने के लिए एक ट्रैकिंग प्रोग्राम बनाएं। प्रति दिन कीमत भिन्न हो सकती है, क्योंकि यह बाजार की स्थितियों से निर्धारित होता है। बेचे गए माल की मात्रा भी भिन्न हो सकती है। दूसरे शब्दों में, मूल्य और मात्रा भविष्य में अज्ञात हैं। इसलिए, उनका प्रतिनिधित्व करने के लिए चर का उपयोग किया जाएगा। जब भी कोई प्रोग्राम लॉन्च किया जाता है, तो उपयोगकर्ता इन चरों के लिए मान प्रदान करता है। चर आपको अग्रिम में वास्तविक मूल्यों को जाने बिना गणना करने की अनुमति देते हैं। परिवर्तनीय नामकरण नियम नामकरण नियम काफी स्वतंत्र हैं। आप एक अक्षर का उपयोग कर सकते हैं, और नाम लंबा और वर्णनात्मक हो सकता है। हालांकि, कुछ सीमाएं हैं: there एक पत्र के साथ शुरू; अधिकतम 255 वर्ण हैं; केवल अक्षर, संख्याएँ और अंडरस्कोर शामिल करें the देखने के क्षेत्र के भीतर अद्वितीय हैं - एक फॉर्म या मॉड्यूल की प्रक्रिया; Reserved आरक्षित शब्दों का प्रयोग न करें। अंतिम प्रविष्टि से मिलान करने के लिए स्वचालित रूप से लोअरकेस और अपरकेस अक्षरों को नामों में परिवर्तित करता है। अतिरिक्त सलाह के रूप में, आप निम्नलिखित बातों को ध्यान में रख सकते हैं: पर्याप्त वर्णनात्मक नामों का उपयोग करें, लेकिन साथ ही साथ कोड के लेखन और पढ़ने में तेजी लाने के लिए जितना संभव हो उतना कम। हालांकि सिरिलिक वर्णों का समर्थन किया जाता है, लेकिन कुछ पर स्विचिंग प्रोग्राम के साथ समस्याओं की संभावना के कारण चर नामों का उपयोग नहीं करना बेहतर होता है कंप्यूटर सिस्टम । एक चर एक संख्या, एक पाठ स्ट्रिंग, ऑब्जेक्ट की एक प्रति संग्रहीत कर सकता है। उत्पन्न कोड को अनुकूलित करने के लिए मेमोरी आवश्यकताएं महत्वपूर्ण हैं। सिस्टम संसाधनों को बचाने के लिए, हमें अधिक कॉम्पैक्ट चर का उपयोग करने की आवश्यकता है। इसके अलावा निहित घोषणा में उपयोग किए गए घोषणा के प्रत्ययों को संदर्भित किया जाता है। विकल्प के प्रकार में कोई भी जानकारी हो सकती है। इसलिए, यह उन परिस्थितियों के लिए उपयुक्त है जहां एक चर को दूसरे प्रकार के मूल्यों पर लेना चाहिए। यह भी सुविधाजनक है कि जब कोई एप्लिकेशन या प्रोटोटाइप जल्दी से विकसित होता है तो चर घोषित नहीं करते हैं। इसलिए, एक अच्छी प्रोग्रामिंग शैली का उपयोग करने से पहले चर घोषित करना है। आप देख सकते हैं कि अल्पविराम द्वारा अलग किए गए कई चर एक ऑपरेटर द्वारा घोषित किए जा सकते हैं। चर प्रकार की आवश्यकता नहीं है। यदि निर्दिष्ट नहीं है, तो डिफ़ॉल्ट भिन्नता प्रकार माना जाता है। ध्यान दें कि एक पंक्ति में कई चर घोषित करते समय, प्रत्येक को प्रकार का संकेत देना चाहिए। स्थिर-लंबाई के तारों में एक स्थिर आकार होता है, जो संग्रहीत जानकारी से स्वतंत्र होता है। यदि इस तरह की स्ट्रिंग के लिए एक छोटा मान असाइन किया गया है, तो लापता वर्ण रिक्त स्थान से भरे हुए हैं। यदि लंबाई लंबी है, तो बेमानी वर्णों को छोड़ दिया जाता है। निहित चर घोषणाओं के मामले में, एक मूल्य का असाइनमेंट किया जा सकता है या नहीं किया जा सकता है। असाइनमेंट प्रक्रिया से बाहर नहीं किया जा सकता है। उपरोक्त आवश्यकताओं के उल्लंघन के परिणामस्वरूप त्रुटि संदेश मिलता है। यह एक चर के उपयोग को रोकता है जिसे परिभाषित किया गया है, लेकिन इसका उपयोग करते समय गलती से गलत नाम है। चर की दृश्यता प्रत्येक चर और एक कार्यक्रम में नामित नाम का अपना क्षेत्र है। यह क्षेत्र प्रोग्राम कोड के विभिन्न भागों में एक चर या एक नामित स्थिरांक की दृश्यता को परिभाषित करता है। मॉड्यूल एक एक्सटेंशन वाली फाइलें हैं। मॉड्यूल मॉड्यूल मॉड्यूल वैश्विक मॉड्यूल वैश्विक चर परियोजना के दौरान रूपों और मॉड्यूल में सभी प्रक्रियाओं के लिए दिखाई देते हैं। इस स्थिति में, "शेडिंग" शब्द का उपयोग किया जाता है। यह कहा जाता है कि वैश्विक चर एक ही नाम के स्थानीय नामों से बादल जाते हैं। यदि प्रक्रिया को किसी अन्य रूप या मॉड्यूल से निष्पादित किया जाता है, तो एक वैश्विक चर का उपयोग किया जाएगा। चरों की अवधि। एक चर के अस्तित्व की लंबाई निर्धारित करती है कि यह चर कितनी देर तक स्मृति को धारण करेगा। जब कोई प्रक्रिया पूरी हो जाती है, तो इसके सभी स्थानीय चर स्मृति से हटा दिए जाते हैं, निम्नलिखित प्रक्रिया में स्थानीय चर के लिए जगह छोड़ते हैं। अगली बार उसी प्रक्रिया को अंजाम देने के बाद, इसके स्थानीय चरों को फिर से बनाया जाएगा, और उनके मानों को 0 या एक खाली स्ट्रिंग से आरंभ किया जाएगा। कई मामलों में यह स्थानीय चर को आरंभ करने के लिए उपयोगी और यहां तक कि वांछनीय होता है जब भी प्रक्रिया निष्पादित होती है। कभी-कभी, हालांकि, एक ही प्रक्रिया के अगले निष्पादन पर उपयोग के लिए प्रक्रिया पूरी होने के बाद भी इन चर के मूल्यों को संरक्षित करना आवश्यक है। यह तब किया जा सकता है जब चर को स्थिर घोषित किया जाता है। प्रक्रिया से बाहर निकलने और अगले रन में इसे बहाल करने पर स्टेटिक वैरिएबल अपने मूल्यों को बनाए रखते हैं। भंडारण मॉड्यूल के स्तर पर स्थानीय चर घोषित करें: कंपनी का नाम और पता, उसमें कर्मचारियों की संख्या, इसके निर्माण की तिथि, प्रति वर्ष बेचे गए उत्पाद का वजन, इसका वार्षिक लाभ, चाहे वह कंपनियों के संघ का सदस्य हो, चाहे इसकी बोर्ड के कितने सदस्य हों। उपयुक्त प्रकारों का उपयोग करें जिन्हें न्यूनतम मात्रा में मेमोरी की आवश्यकता होती है। स्थानीय और वैश्विक चर और छायांकन के साथ काम करने का प्रदर्शन। यदि यह प्रक्रिया नहीं चल रही है, तो डिफ़ॉल्ट मान का उपयोग किया जाता है। यह प्रक्रिया एक वैश्विक चर के उपयोग को प्रदर्शित करती है यदि यह स्थानीय चर, 6 के 6 से अस्पष्ट नहीं है।
मान लीजिए कि अब ये चार वर्ण तालिका में सूचीबद्ध विभिन्न संभावनाओं के साथ दिखाई देते हैं। 1.2, अर्थात्, यह लगभग आधे मामलों में औसतन डेटा लाइन में दिखाई देता है, और इसकी समान संभावनाएं हैं, और यह बहुत कम ही होता है। इस मामले में, अतिरेक है जिसे चर कोड का उपयोग करके हटाया जा सकता है और डेटा को संपीड़ित किया जा सकता है ताकि प्रति प्रतीक 2 बिट से कम की आवश्यकता हो। वास्तव में, सूचना सिद्धांत हमें बताता है कि प्रति चरित्र में आवश्यक बिट्स की सबसे छोटी संख्या औसतन 1.57 है, अर्थात्, वर्णों के इस सेट का एन्ट्रापी।
|
संभावना |
|||
टेबल। 1.2। चर लंबाई कोड।
टैब में। 1.2 प्रस्तावित कोड कोड 1, जो सबसे अक्सर सामना किए जाने वाले प्रतीक के लिए सबसे छोटा कोड प्रदान करता है। यदि आप इसे कोड 1 के साथ एनकोड करते हैं, तो प्रति चरित्र बिट्स की औसत संख्या होगी। यह संख्या सैद्धांतिक न्यूनतम के बहुत करीब है। 20 वर्णों के अनुक्रम पर विचार करें।
जिसमें चार वर्ण दिखाई देते हैं, लगभग, संकेतित आवृत्तियों के साथ। यह लाइन कोड 1 कोड की लंबाई 37 बिट्स के कोड लाइन के अनुरूप होगी
सुविधा के लिए जो डैश द्वारा विभाजित है। हमें 20 वर्णों को एन्कोड करने में 37 बिट्स लगे, यानी औसतन 1.85 बिट्स / वर्ण, जो कि ऊपर की गणना की गई औसत से बहुत दूर नहीं है। (पाठक को यह ध्यान रखना चाहिए कि यह रेखा बहुत छोटी है, और सैद्धांतिक एक के करीब परिणाम प्राप्त करने के लिए, आपको कई हजार वर्णों की इनपुट फ़ाइल लेने की आवश्यकता है)।
हालांकि, अगर हम अब इस बाइनरी अनुक्रम को डिकोड करने का प्रयास करते हैं, तो हम तुरंत पता लगा लेंगे कि कोड 1 पूरी तरह से अनफिट है। अनुक्रम का पहला बिट 1 है, इसलिए पहला वर्ण केवल इसलिए हो सकता है क्योंकि कोड 1 के लिए तालिका में कोई अन्य कोड 1 से शुरू नहीं होता है। अगला बिट 0 है, लेकिन सभी के लिए कोड 0 से शुरू होते हैं, इसलिए डिकोडर को अगले बिट को पढ़ना चाहिए। यह 1 के बराबर है, हालांकि, दोनों के लिए कोड 01 की शुरुआत में हैं। डिकोडर को पता नहीं है कि क्या करना है। या तो स्ट्रिंग को डिकोड करें, जैसे कि,, या, के रूप में, वह है। इसके अलावा, हम ध्यान दें कि अनुक्रम के आगे बिट्स स्थिति को सुधारने में मदद नहीं करेंगे। कोड 1 अस्पष्ट है। इसके विपरीत, तालिका से कोड 2 कोड। 1.2 डिकोडिंग के दौरान हमेशा एक अनूठा परिणाम देता है।
कोड 2 में एक महत्वपूर्ण संपत्ति है जो इसे कोड 1 से बेहतर बनाती है, जिसे उपसर्ग संपत्ति कहा जाता है। इस संपत्ति को निम्नानुसार तैयार किया जा सकता है: यदि बिट्स के एक निश्चित अनुक्रम को एक प्रतीक के कोड के रूप में चुना जाता है, तो दूसरे प्रतीक के किसी भी कोड में शुरुआत में यह अनुक्रम नहीं होना चाहिए (यह उपसर्ग नहीं हो सकता है, अर्थात, उपसर्ग)। एक बार जब स्ट्रिंग "1" को पहले से ही पूर्णांक कोड के रूप में चुना जाता है, कोई अन्य कोड 1 से शुरू नहीं हो सकता है (अर्थात, वे सभी 0 से शुरू होने चाहिए)। एक बार स्ट्रिंग "01" के लिए कोड है, तो अन्य कोड 01 से शुरू नहीं होने चाहिए। यही कारण है कि कोड के लिए और 00 से शुरू होना चाहिए। स्वाभाविक रूप से, वे "000" और "001" होंगे।
इसलिए, जब चर लंबाई कोड का एक सेट चुनते हैं, तो दो सिद्धांतों का पालन किया जाना चाहिए: (1) छोटे कोड को अधिक बार होने वाले वर्णों को सौंपा जाना चाहिए, और (2) कोड को उपसर्ग संपत्ति को संतुष्ट करना चाहिए। इन सिद्धांतों का पालन करते हुए, संक्षिप्त, विशिष्ट रूप से डिकोड किए गए कोड का निर्माण करना संभव है, लेकिन जरूरी नहीं कि सबसे अच्छा (सबसे छोटा) कोड हो। इन सिद्धांतों के अलावा, एक एल्गोरिथ्म की आवश्यकता होती है जो हमेशा सबसे छोटे कोड का एक सेट उत्पन्न करता है (जो, औसतन, सबसे कम लंबाई है)। इस एल्गोरिथ्म का प्रारंभिक डेटा वर्णमाला के पात्रों की आवृत्ति (या संभावना) होना चाहिए। सौभाग्य से, इस तरह के एक सरल एल्गोरिथ्म मौजूद है। यह डेविड हफमैन द्वारा गढ़ा गया था और उनके नाम पर रखा गया है। यह एल्गोरिथ्म। 1.4 में वर्णित किया जाएगा।
यह ध्यान दिया जाना चाहिए कि व्यक्तिगत चरित्रों को एन्कोडिंग करते समय न केवल सांख्यिकीय संपीड़न विधियाँ चर लंबाई कोड का उपयोग करती हैं। एक उल्लेखनीय उदाहरण अंकगणित कोड है, जिसकी चर्चा ar 1.7 में की जाएगी।
| संबंधित लेख: | |
|
करदाता का व्यक्तिगत खाता: एक क्लिक में कर
मुझे करदाता के व्यक्तिगत खाते की आवश्यकता क्यों है? आपके खाते में ... टेन बेस्ट होम-मेड बियर
लोग घर पर बीयर पीने के आदी हैं, यह व्यंजनों के व्यंजनों को जानना उपयोगी है, अच्छी तरह से ... कितने संयोजनों को 3 बिट्स एन्कोड किया जा सकता है
सामग्री की सार तालिका कोडिंग की अवधारणा 1. कोडिंग ... | |