вибір читачів





Популярні статті
паралельне кодування - вид багатоаспектного кодування властивостей об'єктів, що виконується на основі попередньої фасетної класифікації (класифікація проводиться за окремим ознакою виділених об'єктів) властивостей в межах кожної ознаки.
реєстраційне кодування - однозначна ідентифікація об'єктів.
Для початку необхідно, щоб вся інформація оцифровувалася, наприклад, транскрипція глибинних інтерв'ю. Потім ми приступаємо до створення «герменевтичної одиниці», також відомої як проект або база даних, яка включає в себе первинні документи, такі як цитати, коди і замітки.
Різні варіанти кодування доступні досліднику як відкрите кодування, живе або за списком. Щоб кодувати кожну відповідь, дослідник використовував стратегію відкритого, аксіального і вибіркового кодування. Спочатку відкрите кодування застосовується для розгляду кожної крихітної деталі, в той час як ми розробляємо деякі попередні категорії, які розглядаються у відповідності з конкретними властивостями, а потім встановлюють підкатегорії. Інформація була закодована і класифікована шляхом ідентифікації одного або декількох фрагментів тексту з темою і посилання на код.
позиційне кодування - спосіб кодування реквізитів ознак, які застосовують фіксовану кількість значень, при якому довжина кодової комбінації встановлюється рівною кількістю можливих значень реквізиту.
побуквенное кодування - спосіб кодування реквізитів, що складається в послідовному кодуванні кожного символу і застосовуваний при передачі повідомлень по каналах зв'язку.
Всі коди були привласнені імена якомога ближче до опису, яке вони описують. На малюнку 3 показаний менеджер коду з деякими створеними кодами. Під час осьового кодування ми фокусуємося на встановленні взаємозв'язків між категоріями і підкатегоріями. Можливість навігації по безлічі первинних документів, пропонованих цією програмою, має вирішальне значення для визначення зв'язків між категоріями, підкатегоріями і кодами в міру їх появи. Одним з найбільш корисних інструментів цієї програми є менеджер кодових посилань, який дозволяє нам пов'язувати коди з іншими кодами, що дозволяє створювати мережі, які сприяли побудові відносин або зв'язків між концепціями або темами.
порядкове кодування - кодування реквізитів-ознак (нечислові дані - колір, марка, прізвище ...), при якому всі кодовані значення зведені в список і кодовою комбінацією кожного значення є його порядковий номер. Застосовується в разі, коли кількість об'єктів невелика.
послівний кодування - спосіб кодування реквізитів-ознак, що складається в послідовному кодуванні кожного слова (а не букви) вхідного документа. Вимагає семантичного аналізу і виконується вручну.
Створення мереж дозволило нам візуалізувати графічним способом структурування даних і тим. Згодом виборче кодування дозволило нам провести більш систематичне кодування щодо основних понять. Цей процес включав послідовне читання, кодування, перегляд і повторне кодування даних в категоріях або «сім'ях». Основна перевага «сім'ї» полягає в тому, що його можна використовувати як будь-який інший тип коду для розробки складних запитів у всьому наборі даних або використання їх в якості мережевих вузлів.
Всі розглянуті коди засновані на різних системах числення. Будь-аналогової або дискретної інформації можна приписати опредленія порядковий номер. При цьому передача, зберігання і обробка інформації зводиться до операцій з числами, які виражаються в тій чи іншій системі числення. В результаті отримуємо код, заснований на даній системі числення. Як правило, в ЕОМ інформація кодується в двійковій СС. Це питання буде детально розглянуто на наступній лекції.
Іншим сильним аспектом цієї програми є її служба пошуку, яка може виконуватися як для тексту, так і для об'єднання з кодами. Нарешті, програма дозволяє робити звіти про зустрічі з найбільш релевантними кодами, які експортуються в текстовому форматі. Крім того, частотні списки для всіх документів можуть бути створені одночасно, і дані можуть бути імпортовані і оброблені в електронній таблиці або іншої статистичної програмі для отримання відносних частот.
Демонстрація строгості з використанням тематичного аналізу: гібридний підхід індуктивного і дедуктивного кодування і розробки тем. Міжнародний журнал якісних методів, 5, 80. Ступінь в області комунікаційних наук з аспірантом в області комунікаційних наук і магістра в області «Освітні технології: електронні навчальні курси та управління знаннями». В даний час він є аспірантом в області освітніх технологій в Університеті Ровіра і Віргіл. У минулому році він брав участь у розробці та реалізації ряду дослідницьких проектів і пов'язаних з ними програм в області інформаційних і комунікаційних технологій, що застосовуються в сфері освіти, розробки навчальних матеріалів та розробки навчальних курсів викладацький склад.
Питання для самоконтролю і підготовки до семінарського заняття
1. Що розуміють під інформаційними процесами?
2. Перерахуйте можливі дії з інформацією.
3. Які типи інформаційних процесів присутні як складові в інших інформаційних процесах?
4. Які основні поняття пов'язані зі зберіганням інформації?
Реферат: фонологічна кодування в мовному виробництві. У третій частині наведені дані про фонологическом кодуванні, включно з помилками мови, феномен мови, дослідження часу реакції і нейропсихологічні дослідження. Нарешті, наводяться дані про роль складу як одиниці мовного виробництва.
Пропонується змішане уявлення складу, в якому злами є як шматками, так і схемами. Ключові слова: фонологическое кодування, мовне планування, склад. Мал. - Моделей в області виробництва зброї. Загальна модель мовного виробництва. Модель фонологічної кодування в мовному виробництві.
5. Що таке носій інформації? Які види носіїв інформації можна виділити? Наведіть приклади носіїв інформації.
6. Що таке сховище інформації? Наведіть приклади сховищ.
7. Які основні характеристики сховища інформації?
8. Що таке дані? Бази даних? Банки даних?
9. Яка загальна схема процесу обробки інформації?
Граматичний фон для обговорення. Рівні та особливості його гіпотези про екзотику. Першим кроком в фонологическом кодуванні є активація або витяг фонологічної форми обраного слова в ментальному лексиконі. Більшість теорій фонологічної кодування розрізняють два типи фонологічної інформації: сегментну інформацію і метричну інформацію слова. Сегментарна інформація відповідає фонетичній структурі слова, тобто композиції приголосних, груп приголосних, голосних і т.д. теорії відрізняються ступенем специфікації, починаючи від під-специфікації до повної фонематичної специфікації.
10. Що називається алгоритмом обробки інформації?
11. Які два типи обробки інформації можна виділити?
12. Наведіть приклади обробки інформації першого типу.
13. Чим характеризується другий тип обробки інформації? Наведіть приклади.
14. Що називається кодуванням інформації?
15. Для чого використовується структурування даних? Наведіть приклади.
У моделі сегменти просто представлені як приголосні і голосні. Фонологічні слова знаходяться в сфері сіллабіфікаціі. У фонологическом кодуванні повинен бути механізм, який буде створювати фонологические рамки для слів, що є фонологическим формуванням слів на малюнку. Наступним кроком в фонологическом кодуванні є асоціація сегментной інформації з метричної структурою відповідного фонологічної слова. Багато досліджень показують, що цей процес відбувається від «зліва направо».
Після того, як сегменти впорядковані, а асоціація виходить від «зліва направо», слоганом фонологічної слова виконується шляхом, і читач може легко перевірити, що сілогізація моря, яка стає наївною. Які реалізують склади фонологічної слова. Більшість складів, які ми використовуємо, відповідають часто використовуваним артикуляційних жестів. Більшість явищ аллофоніческой варіації, коартикуляция і асиміляції мають склад як область. Після цієї теорії сіллабарій є кінцеве безліч пар, що складається з фонологічної опису складу, з одного боку, і артикуляторного складового жесту - з іншого. запис адреси, артикуляторного жест відповідає виходу.
16. Як формулюється задача пошуку інформації?
17. Яка схема процесу передачі інформації?
18. У якій формі може бути представлена інформація в процесі передачі?
19. Що називається повідомленням?
20. Що таке канали зв'язку (інформаційні канали)? Наведіть приклади.
21. Опишіть схему процесу передачі інформації, запропоновану К. Шенноном. Поясніть роботу цієї схеми на прикладі.
Поки фонологические склади створюються один за іншим, в процесі асоціації кожен з цих складів активує свій відповідний артикуляторного жест в шарі. Цей артикуляторного жест буде являти собою вхід в артикуляторного систему, яка контролює моторне виконання складу. Першим кроком є відновлення фонологічної форми слова, тобто сказати його лексему. Другий етап відповідає відновленню артикуляторного складового жесту. Перший етап включає ментальний лексикон, другий - складову.
На думку цих авторів, ці два етапи були б послідовними і незалежними. Вивчення виробництва слів засноване на трьох основних підходах: другий підхід використовує вимірювання словесного часу виробництва: цей підхід відноситься до найменування креслень об'єктів. Нарешті, третій підхід - це нейропсихологічне дослідження.
22. Що розуміють під аналогової зв'язком? Дискретної зв'язком? Цифровий зв'язком?
23. Що розуміють під кодуванням інформації, що йде від джерела (схема К. Шеннона)? Наведіть приклад.
24. Що називається "шумом" в процесі передачі інформації? До чого призводять перешкоди? Які їх причини?
25. Як можна усунути перешкоди при передачі інформації?
Мовне виробництво, тобто дослідження пацієнтів, у яких після інсульту були розмовні мовні розлади. Помилки виробництва вже давно розглядаються як надання інформації про когнітивних процесах, пов'язаних з мовним виробництвом. Зокрема, помилки вказують, на якому рівні система винна, що дозволяє ізолювати рівні, відповідні етапам обробки. Ці рівні можна уявити як модульні або інтерактивні. Збір і аналіз таких помилок є відправною точкою для більшості досліджень в галузі мовного виробництва.
26. Які технічні засоби захисту каналів зв'язку від впливу шумів?
27. Які основні ідеї теорії кодування К. Шеннона, що дають методи боротьби з шумом?
28. Який спосіб боротьби з втратою інформації застосовується в сучасних системах цифрового зв'язку?
29. Що називається швидкістю передачі інформації? В яких одиницях вона вимірюється?
Досить мало хорошого слуху, олівця і паперу. Озброєний цим матеріалом, ми можемо почати вивчати значна кількість питань. Існують важливі колекції спостережень помилок виробництва, зроблених Фрокін і Катлер. Помилки виробництва - це кілька форм. Однак в цьому різноманітті була розроблена точна таксономія.
Незважаючи на значний інтерес до спостереження за виробничими помилками, існують численні недоліки щодо цього методу, зокрема рідкість помилок, неоднозначність класифікації помилок, а також зміщення в зборі цих помилок. Рідкість помилок досить дивна, враховуючи поширене враження, що мова сповнена помилок. Причиною цього враження не є помилки, а дисфункція. Блекмер і Міттон показали, що слухачі радіо переривають себе частіше, ніж раз на п'ять секунд, але тільки 3% переривань повинні були виправляти помилки виробництва, а решта - дисфункції. незважаючи на всі ці потенційні проблеми, існує хороша конвергенція між природними і лабораторними спостереженнями.
30. Що характеризує пропускна здатність інформаційних каналів?
Щоб куплена вами автосигналізація стала надійним захистом, необхідно правильно її підібрати. Одним з основних параметрів, що впливають на ефективність роботи систем сигналізації, є спосіб кодування сигналу. У цій статті ми постараємося доступно пояснити, що означає динамічне кодування сигналів і що означає діалоговий код в автосигналізація, який вид кодування краще, які у кожного є позитивні і негативні сторони.
Деякі дослідники розробили оригінальні методи індукції ковзання для вивчення помилок експериментального виробництва. Суб'єкти повинні мовчки читати послідовні пари слів, як в наступному прикладі. Під час цього списку випробуваним пропонується вимовити певну пару після її мовчання. Суб'єкти часто викликають помилки, такі як «рідкісний ринву» замість «автовокзалу». Таким чином, цей метод дозволяє індукувати експериментально помилок виробництва і вивчення факторів, відповідальних за ці помилки.
Інший дуже поширений метод, який використовується для вивчення мовного виробництва, - це іменування об'єктів, головним чином тому, що з цим методом спостерігаються кращі результати, і оскільки ми вимірюємо словесні часи виробництва, ми Ми можемо вивчати тимчасовий хід психічних процесів під час виробництва мови, що не дозволяє вивчати помилки виробництва.
 Протистояння розробників сигналізацій і викрадачів почалося ще з часів створення перших автосигналізацій. З появою нових більш досконалих охоронних систем удосконалювалися і засоби їх злому. Найперші сигналізації мали статичний код, який легко зламувався методом підбору. Відповіддю розробників стала блокування можливості добірка коду. Наступним кроком зломщиків стало створення граббер - пристроїв, які сканували сигнал з брелока і відтворювали його. Таким способом вони дублювали команди з брелока власника, знімаючи автомобіль з захисту в потрібний момент. Щоб захистити автосигналізації від злому граббером, почали використовувати динамічне кодування сигналу.
Протистояння розробників сигналізацій і викрадачів почалося ще з часів створення перших автосигналізацій. З появою нових більш досконалих охоронних систем удосконалювалися і засоби їх злому. Найперші сигналізації мали статичний код, який легко зламувався методом підбору. Відповіддю розробників стала блокування можливості добірка коду. Наступним кроком зломщиків стало створення граббер - пристроїв, які сканували сигнал з брелока і відтворювали його. Таким способом вони дублювали команди з брелока власника, знімаючи автомобіль з захисту в потрібний момент. Щоб захистити автосигналізації від злому граббером, почали використовувати динамічне кодування сигналу.
Нарешті, коли це можливо, ми представимо випадки пацієнтів, які підтвердять той чи інший експериментальний результат. Слід, однак, відзначити, що цей нейропсихологический підхід все ще перебуває в зародковому стані, особливо щодо зв'язування нейропсихологічних спостережень зі звичайними психолінгвістичного моделями.
Після отримання семантичної і синтаксичної інформації оратор повинен отримати фонологическую інформацію, пов'язану з цими словами. Спостереження за повсякденним життям говорять про те, що оратор отримує фонологическое уявлення, відмінне від того, що було зроблено насправді. Справді, ми можемо сформулювати одне і те ж слово з просодическим начерком, звуком і багатьма іншими різними факторами.
 Динамічний код в автосигналізація - постійно змінюється пакет даних, який передається з брелока на блок сигналізації через радіоканал. З кожною новою командою з брелока надсилається код, який раніше не використовувався. Цей код розраховується за певним алгоритмом, закладеному виробником. Найпоширенішим і надійним алгоритмом вважається Keelog.
Динамічний код в автосигналізація - постійно змінюється пакет даних, який передається з брелока на блок сигналізації через радіоканал. З кожною новою командою з брелока надсилається код, який раніше не використовувався. Цей код розраховується за певним алгоритмом, закладеному виробником. Найпоширенішим і надійним алгоритмом вважається Keelog.
Сигналізація працює за наступним принципом. Коли власник машини натискає на кнопку брелока, генерується сигнал. Він несе в собі інформацію про кількість натискань (це значення необхідно для синхронізації роботи брелока і блоку управління), серійний номер пристрою і секретному коді. Перед відправленням ці дані попередньо зашифровуються. Сам алгоритм шифрування знаходиться у вільному доступі, але щоб розшифрувати дані, необхідно знати секретний код, який закладається в брелок і блок управління на заводі.
Існують також оригінальні алгоритми, розроблені виробниками сигналізацій. Таке кодування практично виключило можливість підбору коду-команди, але з часом зловмисники обійшли і цей захист.
 У відповідь на впровадження динамічного кодування в автосигналізація, був створений динамічний граббер. Принцип його дії полягає в створенні перешкоди і перехопленні сигналу. Коли автовласник виходить з автомобіля і натискає на кнопку брелока, створюється сильна радіоперешкод. Сигнал з кодом не доходить до блоку управління сигналізації, але він перехоплюється і копіюється граббером. Здивований водій натискає повторно на кнопку, але процес повторюється, і другий код також перехоплюється. З другого разу автомобіль ставиться на захист, але команда надходить уже з пристрою злодія. Коли власник машини спокійно йде по своїх справах, викрадач посилає другий, раніше перехоплений код і знімає машину з захисту.
У відповідь на впровадження динамічного кодування в автосигналізація, був створений динамічний граббер. Принцип його дії полягає в створенні перешкоди і перехопленні сигналу. Коли автовласник виходить з автомобіля і натискає на кнопку брелока, створюється сильна радіоперешкод. Сигнал з кодом не доходить до блоку управління сигналізації, але він перехоплюється і копіюється граббером. Здивований водій натискає повторно на кнопку, але процес повторюється, і другий код також перехоплюється. З другого разу автомобіль ставиться на захист, але команда надходить уже з пристрою злодія. Коли власник машини спокійно йде по своїх справах, викрадач посилає другий, раніше перехоплений код і знімає машину з захисту.
 Виробники автосигналізації вирішили проблему злому досить - таки просто. Вони стали встановлювати на брелоках дві кнопки, одна з яких ставила машину на захист, а друга - деактивувала захист. Відповідно для установки і зняття захисту посилалися різні коди. Тому скільки б перешкод злодій ні поставив при установці машини на захист, він ніколи не отримає код, необхідний для деактивації сигналізації.
Виробники автосигналізації вирішили проблему злому досить - таки просто. Вони стали встановлювати на брелоках дві кнопки, одна з яких ставила машину на захист, а друга - деактивувала захист. Відповідно для установки і зняття захисту посилалися різні коди. Тому скільки б перешкод злодій ні поставив при установці машини на захист, він ніколи не отримає код, необхідний для деактивації сигналізації.
Якщо ви натиснули на кнопку «установка на захист», а машина не зреагувала, то, можливо, ви стали метою викрадача. В цьому випадку не потрібно бездумно натискати на всі кнопки брелока, в спробах якось виправити ситуацію. Досить ще раз натиснути на кнопку захисту. Якщо ви випадково натиснете на кнопку «зняти з захисту», то злодій отримає необхідний йому код, яким незабаром скористається і вкраде вашу машину.
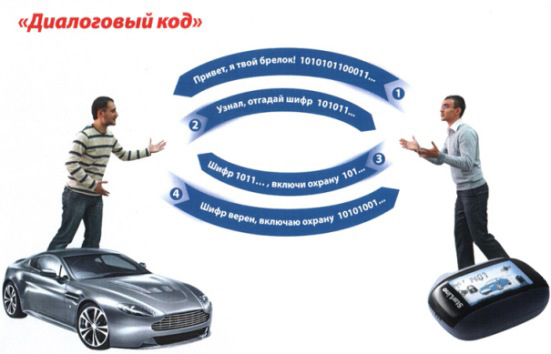
Сигналізації з динамічним кодуванням вже дещо застаріли, вони не забезпечують стовідсотковий захист автомобіля від угону. На їх зміну прийшли пристрої з діалоговим кодуванням. Якщо ви власник недорогої машини, то вам не потрібно турбуватися, оскільки дуже низька ймовірність того, що на ваше майно зазіхне оснащений найсучаснішим обладнанням злодій. Щоб убезпечити своє майно, використовуйте багаторівневий захист. Встановіть додатковий. Він забезпечить захист машини, в разі злому автосигналізації.
 Після появи динамічних граббер автосигналізації, що працюють на динамічному коді, стали дуже вразливими перед зловмисниками. Також велика кількість алгоритмів кодування були зламані. Щоб забезпечити захист автомобіля від злому такими пристроями, розробники сигналізацій стали використовувати діалогове кодування сигналу.
Після появи динамічних граббер автосигналізації, що працюють на динамічному коді, стали дуже вразливими перед зловмисниками. Також велика кількість алгоритмів кодування були зламані. Щоб забезпечити захист автомобіля від злому такими пристроями, розробники сигналізацій стали використовувати діалогове кодування сигналу.
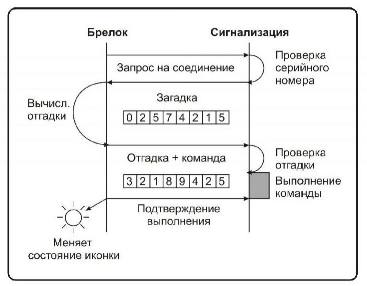 Як зрозуміло з назви, шифрування цього типу ведеться в режимі діалогу межу брелоком і блоком управління автосигналізацією, розташованому в автомобілі. Коли ви натискаєте на кнопку, з брелока подається запит на виконання команди. Щоб блок управління переконався, що команда надійшла саме з брелока власника, він посилає на брелок сигнал з випадковим числом. Це число обробляється за певним алгоритмом і відсилається назад на блок управління. В цей час блок управління обробляє то саме число і порівнює свій результат з результатом, надісланим брелоком. При збігу значень, блок управління виконує команду.
Як зрозуміло з назви, шифрування цього типу ведеться в режимі діалогу межу брелоком і блоком управління автосигналізацією, розташованому в автомобілі. Коли ви натискаєте на кнопку, з брелока подається запит на виконання команди. Щоб блок управління переконався, що команда надійшла саме з брелока власника, він посилає на брелок сигнал з випадковим числом. Це число обробляється за певним алгоритмом і відсилається назад на блок управління. В цей час блок управління обробляє то саме число і порівнює свій результат з результатом, надісланим брелоком. При збігу значень, блок управління виконує команду.
Алгоритм, за яким виконуються розрахунки на брелоку і блоці управління, індивідуальний для кожної автосигналізації та закладається в неї на ще заводі. Давайте для розуміння розглянемо найпростіший алгоритм:
X ∙ T 3 - X ∙ S 2 + X ∙ U - H = Y
T, S, U і H - це числа, які закладаються в сигналізацію на заводі.
X - випадкове число, яке відправляється з блоку управління на брелок для перевірки.
Y - число, яке розраховується блоком управління і брелоком за заданим алгоритмом.
Давайте розглянемо ситуацію, коли власник сигналізації натиснув на кнопку і з брелока на БО передався запит на зняття машини з охорони. У відповідь блок управління згенерував випадкове число (для прикладу візьмемо число 846) і відправив його на брелок. Після цього БО і брелок виконують розрахунок числа 846 за алгоритмом (для прикладу розрахуємо за наведеним вище найпростішого алгоритму).
Для розрахунків приймемо:
T = 29, S = 43, U = 91, H = 38.
У нас вийде:
846∙24389 - 846∙1849 + 846∙91- 38 = 19145788
Число (19145788) брелок відправить блоку управління. Одночасно з цим блок управління виконає такий же розрахунок. Числа співпадуть, блок управління підтвердить команду брелока, і машина зніметься з охорони.
 Навіть для розшифровки елементарного алгоритму, наведеного вище, знадобиться чотири рази (в нашому випадку в рівнянні чотири невідомих) перехопити пакети даних.
Навіть для розшифровки елементарного алгоритму, наведеного вище, знадобиться чотири рази (в нашому випадку в рівнянні чотири невідомих) перехопити пакети даних.
Перехопити і розшифрувати пакет даних діалогової автосигналізації практично неможливо. Для кодування сигналу використовуються так звані хеш-функції - алгоритми, які перетворюють рядки довільної довжини. Результат такого шифрування може містити до 32 букв і цифр.
Нижче наведені результати шифрування чисел з найпопулярнішого алгоритму шифрування MD5. Для прикладу було взято число 846 і його модифікації.
MD5 (846) =;
MD5 (841) =;
MD5 (146) =.
Як бачите, результати кодування чисел, що відрізняються тільки однією цифрою, абсолютно не схожі один на одного.
Схожі алгоритми використовуються в сучасних діалогових автосигналізація. Доведено, що для зворотного декодування і отримання алгоритму, сучасних комп'ютерів знадобиться більше століття. А без цього алгоритму буде неможливо генерувати перевірочні коди для підтвердження команди. Тому зараз і в найближчому майбутньому злом діалогового коду неможливий.
Сигналізації, що працюють на діалоговому коді виявляються більш безпечні, вони не піддаються електронного злому, але це не означає, що ваш автомобіль буде в цілковитій безпеці. Ви можете випадково загубити брелок або його у вас вкрадуть. Для підвищення рівня захисту, необхідно використовувати додаткові кошти, такі як і.
| Статті по темі: | |
|
Особистий кабінет платника податків: податки в один клік
Навіщо потрібен особистий кабінет платника податків? В особистому кабінеті ... Десять кращих домашніх закусок до пива швидкого приготування
Людям, які звикли пити пиво вдома, корисно знати рецепти страв, добре ... Скільки комбінацій можна закодувати 3 бітами
Поняття про кодування Реферат Зміст 1. Кодування ... | |