вибір читачів




Популярні статті
Поняття про кодування
реферат
Зміст
1. кодування інформації
2.
3. Кодування символів клавіатури
4. Кодування кольору
5. Кодування графічної інформації
6. Кодування цілих і дійсних чисел
7. Кодування звукової інформації
8. Поняття файлу
9. Одиниці виміру довжини двійкового коду повідомлень
Точно так же цифра з найважчим вагою - це той, який більше написаний зліва. Число, що позначається номером, слід. . Значення числа виходить шляхом додавання кожної з цифр, помноженої на коефіцієнт, що представляє його вага. Таким чином, справа наліво перша цифра називається одиницями, другими десятками, третинами сотень і так далі. У базі 10 значення числа виходить множенням числа одиниць на одиницю, десятки на 10, сотні на 100 і т.д. як видно з номера.
Число як сума ступенів 10. Факторами, за якими множиться кожна цифра, є послідовні повноваження використовуваної бази. В цьому випадку однакове число може бути переписано наступним чином. Тобто число виходить шляхом множення кожної цифри на підняте підставу на показник, що дорівнює займаної ним позиції, починаючи з одиниці меншої ваги, положення якої дорівнює нулю.
10.Представленіе соізмерності одиниць виміру інформації
кодування інформації - це подання повідомлень в конкретному виді за допомогоюдеякої послідовності знаків.
Правило відображення одного набору знаків в інший називається кодом. Спосіб представлення інформації за допомогою двох символів - 0 і 1 називають двійкового коду.
Формула узагальненість для будь-якого базису. Число в базі 7 не має цифри більше 6, так як база використовує тільки цифри від 0 до. При написанні чисел на різних підставах виникає проблема двозначності. Щоб уникнути плутанини, як показано в наведеному вище рівнянні, при маніпулюванні числами в різних основах включає базу, на якій написано справа і як індекс.
Фактор містить решту цифр і при застосуванні послідовних поділів ми отримуємо в якості залишку цифри числа у порядку зростання. Для отримання його уявлення в базі 7 реалізовано перший розподіл, інше - 2, і, отже, його розряд меншої ваги. Якщо ця операція повторюється послідовно, вийшло значення буде в кінцевому підсумку дорівнює 0, а наступні залишки відповідають поданням числа в базі 7, як показано на.
біт - це одна двійкова цифра 0 або 1 . Одним бітом можна закодувати два значення: 1 або 0 .
двома бітами можна закодувати вже чотири значення: 00, 01, 10, 11 .
трьома бітами кодуються 8 різних значень. Додавання одного біта подвоює кількість значень, яке можна закодувати.
Отримання цифр в базі 7. Послідовне застосування поділів базою гарантує, що коефіцієнт завжди досягає значення, меншого, ніж значення бази. Як тільки це відбудеться, подальший поділ не потрібно. Процес зупиняється, коли кінцевий коефіцієнт менше бази. Два методу були описані для перекладу числа, представленого в будь-якій базі дощенту 10, і навпаки. Об'єднання обох процедур може переводити числа, представлені на будь-якій основі.
Найпростіший набір даних для двійкового кодування для процесора, який повинен обробляти, - це число натуральних чисел. Подання відповідає номерам в базі. Тільки дві цифри цієї бази збігаються з двома значеннями, які можуть маніпулювати цифровими схемами.
Кодування символів клавіатури
Д ля кодування одного символу клавіатури використовують8 біт - один байт.
байт - це найменша одиниця обробки інформації. За допомогою одного байта можна закодувати 2 8 =256 символів.
Існує таблиця кодів клавіатури. Перші коди з 32 по 127 є стандартними і обов'язковими для всіх країн і всіх комп'ютерів, а в другій половині ( 128 -255 ) Кожна країна може створювати свій стандарт - національний.
Але оскільки цифри, які можуть відображатися в довічним числі, рівні 0 або 1, наведену вище формулу можна інтерпретувати спрощеним способом. З огляду на число, представлене в базі 2, його десятковий еквівалент виходить додаванням тих ступенів 2, показниками яких відповідає місце, де цифра.
Розглянемо число в двійковому вигляді. Його десятковий еквівалент виходить наступної сумою. Переклад бази 10 на базову 2. Щоб дізнатися, чи є число парних або непарних, просто подивіться на біт меншої ваги. Якщо цей біт дорівнює одиниці, число непарне, якщо воно дорівнює нулю, число парне. Демонстрація цієї властивості тривіальна. Десятковий еквівалент числа в двійковому вираженні виходить підсумовують значеннями всіх цих ступенів, за винятком перших пар. Тому непарне число повинно мати один в своєму молодшому вазі.
Першу половину називають таблицею ASCII (Американський стандартний код для обміну інформацією).
Є й інші таблиці кодування KOI8-U, Wsndows-1251, Unicode. З перерахованих таблиць особливою є таблиця Unicode, Оскільки кожен символ цієї таблиці кодується двома байтами.
кодування кольору
Точно так же будь-яке парне число повинно мати нуль в молодшому бите ваги, оскільки воно може складатися тільки з ступенів 2 пари. Друге властивість застосовується не тільки до основи 2, але і до будь-якої базі. Операції множення і цілочисельного ділення виконуються шляхом додавання нуля в якості розряду меншої ваги або шляхом видалення молодшого розряду ваги відповідно.
Для базових 10 чисел операція множення на 10 виконується шляхом додавання нуля як молодша цифри ваги до зазначеного числа. Аналогічно, якщо десяткове число ми ділимо на десять, то коефіцієнт виходить шляхом ігнорування цифри меншої ваги, що в свою чергу відповідає решті частини ділення.
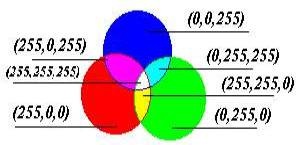
 Будь-який колір можна представити у вигляді комбінації трьох основних кольорів: червоного,
зеленого ісинього (Їх називають колірними складовими).
Будь-який колір можна представити у вигляді комбінації трьох основних кольорів: червоного,
зеленого ісинього (Їх називають колірними складовими).
Якщо закодувати колір точки за допомогою трьох байтів ( 24 біта), То перший байт буде нести інформацію про червоною складової, другий - зеленої, а третій - синьої. Чим більше значення байта колірної складової, тим яскравіше цей колір.
Повертаючись до двійкового поданням, в цьому випадку множення і цілочисельне ділення на 2 відповідають аналогічно операціям додавання нуля в якості розряду меншої ваги або видалення більш високою цифри ваги. Базове кодування 8, хоча, мабуть, не корисно в контексті цифрової логіки, виконує особливу властивість, яке робить його важливим. Застосування понять, представлених в числах, закодованих в цій базі, складається з цифр між 0 і Отже, після 7, наступне число дорівнює 10, а після 77 число в обчисленні.
Ставлячи будь-які значення (від 0 до 255) для кожного з трьох байтів, за допомогою яких кодується колір, можна закодувати будь-який з 16,5 мільйонів квітів.
Кодування графічної інформації
Щоб перевести вказану кількість в базі 10 на базову 8, та послідовно операція ділення між 8, з яких отримані відповідні цифри. В принципі, можна виконати переклад числа в двійковому вигляді на число в базі. Принаймні можна отримати уявлення в базі 10 двійкового числа, а потім виконати його переклад на базу. Але чи може цей переклад бути виконаний безпосередньо?
Виявлено аналіз операцій, необхідних для перекладу, це можна зробити негайно. Поділ між 8 в довічних числах відповідає поділу між потужністю бази, більш конкретно 2 3. Як описано вище, ця операція еквівалентна трьом розділах між 2, або що те ж саме, видаліть три біта меншої ваги з числа, яке в свою чергу є залишком ділення. Ці два результату - це ті, які необхідні для здійснення переказу.
Закодувати колір однієї точки відомо як. На це необхідні один, два або три байта, в залежності від того, скільки кольорів треба передати. Для кодування малюнка необхідно малюнок розбити на точки. Чим більше буде точок, тим точніше буде передача малюнка. Потім починаючи з лівого верхнього кута і, рухаючись по рядках зліва направо, кодувати колір кожної точки.
Отже, для того, щоб перевести число безпосередньо з двійкового коду в базове 8, угруповання трьох-трьох біт починається з менших, і переклад кожної групи з 3 біт в цифру між 0 і трьома двійковими цифрами може бути щоб точно представляти числа від 0 до 7 , як показано на малюнку.
Відповідність між групами з 3 біт і цифрами в вісімковому. У разі, якщо в останній групі немає 3 біта, відсутні біти розглядаються з нульовим значенням. Він показує приклад того, як робиться цей переклад. З огляду на, наскільки легко перетворити двійкове число в вісімкове і навпаки, остання база використовується як більш компактне представлення двійкових чисел. Замість написання набору одиниць і нулів записується його восьмеричний еквівалент. Настільки звичайним є це подання, що для позначення того, що число записано в базі 8, замість додавання індексу після цифри меншої ваги, нуль додається вліво.



Кодування цілих і дійсних чисел
Цілі числа кодуються просто перекладом чисел з однієї системи числення в іншу.
для кодування дійсних чисел використовують 80-розрядне кодування. При цьому число перетворять в стандартний вид.
Цей дуже безпосередній процес перекладу виходить з властивості, що база 8 є міццю бази. Завдяки цій властивості наступні ділення і отримання залишку являють собою не що інше, як групувати біти, що починаються з меншої ваги. База 8 не єдина, у якій є ця властивість. Наступне підставу в порядку зростання, яке також є силою двох, є базою. Чи можна записати числа в цій базі? Дотримуючись концепціям, представленим в одному, вам потрібно стільки цифр, скільки база вказує, починаючи з нуля.
На додаток до використання десяти цифр від 0 до 9 і раніше потрібно ще шість цифр. Це кодування також відомо як шістнадцяткове кодування. Чи можна зробити прямий переклад двійкового числа в шістнадцяткове число? Операцією, необхідної для отримання цифр, є поділ між Але, будучи ступенем 2, операція полягає в відкиданні чотирьох біт меншої ваги двійкового числа, що в свою чергу відповідає решті частини ділення. Тому, щоб отримати шістнадцяткове число з двійкового числа, біти від чотирьох до чотирьох повинні бути згруповані разом, починаючи з найменш зважених бітів.
Кодування звукової інформації
Прийоми і методи кодування звуковою інформацією прийшли в обчислювальну техніку найбільш пізно. У підсумку методи кодування звукової інформації двійковим кодом далекі від стандартизації і дуже різноманітні.
М ожно виділити два основних напрямки кодування: метод FM (Розкладання складного звуку на гармонійні ряди) і метод таблично-хвильового синтезу (Зберігання в окремих таблицях пронумерованих зразків різних музичних звуків)
Кожен з них перетворюється в шістнадцяткову цифру. З 4 бітами, точно 16 цифр, використовуваних базою 16, кодуються, як показано. Відповідність між групами з 4 біт і цифрами в шістнадцятковому форматі. Як і у випадку з базою 8, шістнадцяткова база використовується як більш компактне представлення двійкових чисел. На ньому показані приклади відповідності між двійковим поданням і шістнадцятковим. Переклад довічного в шістнадцятковий.
Перетворення з шістнадцятирічного в основу 10 виконується однаково з іншою базою. У попередніх розділах ми бачили, як кодувати натуральні числа в двійковому форматі. Подання числа відповідає набору біт. Але скільки біт необхідно для подання натуральних чисел? Оскільки є нескінченні числа, відповідь - нескінченні біти. Але для того, щоб цифрова схема могла керувати цим типом чисел, його уявлення повинно мати кінцевий розмір.
поняття файлу
У комп'ютері будь-яка інформація (тексти, числа, малюнки, звуки) представлена у вигляді послідовності байтів. Для того, щоб комп'ютер розрізняв всі види інформації, вводиться таке поняття як формат.
Кожна група байтів, що представляє певну закодовану інформацію, називається файлом. файл повинен мати унікальне ім'я певного формату.
Це обмеження означає, що на додаток до визначення схеми, за допомогою якої необхідні елементи кодуються з використанням двійкового коду, розмір кодування також повинен бути встановлений і що відбувається, коли це кодування недостатня. Наприклад, прийнято представляти натуральні числа в двійковому форматі з розміром 10 біт. Тільки цифри в діапазоні можуть бути представлені.
Результат обчислюється, але його уявлення з 10 бітами неможливо. У цій ситуації ви отримуєте число, представлення якого неможливо, воно називається переповненням або «переповненням». Процесори виявляють і повідомляють про цю ситуацію, тому що це аномалія в кодуванні.
На ім'я файлу комп'ютер визначає, де файл знаходиться, яка інформація в ньому міститься, в якому форматі вона записана і якими програмами її можна обробити.
файл - найменша одиниця зберігання інформації. Файл може зберігати десятки, сотні байтів.
Одиниці виміру довжини двійкового коду повідомлень
Кількість біт, що використовуються для кодування природних, - це параметр, який залежить від використовуваного процесора. Чим більше цифр використовується, тим більше чисел може бути представлено, але в той же час більш складним є дизайн внутрішньої логіки, що відповідає за виконання операцій. Протягом всієї історії процесори використовували все більше і більше біт для представлення натуральних чисел, починаючи з 8 біт до 128 біт більш складних процесорів.
Проблема розміру кодування не є унікальною для подання натуральних чисел. Будь-який набір з нескінченним числом елементів для подання в довічним файлі має ту ж проблему. Залежно від розміру кодування буде відображатися тільки підмножина його елементів, і процесор повинен виявляти і повідомляти, коли потрібно кодувати елемент, представлення якого неможливо.
Для вимірювання закодованої інформації у вигляді двійкового коду використовують такі одиниці вимірювання (одиниці вимірювання ємності запам'ятовуючих пристроїв комп'ютера ) :
1 Кілобайтів = 2 10 байт = 1024 байт
1 Мегабайт = 2 10 Кбайт = 2 20 байт = 1048576 байт
1 Гігабайт = 2 10 Мбайт = 2 20 Кбайт = 2 30 байт
1 Терабайт = 2 10 Гбайт = 2 20 Мбайт = 2 30 Кбайт = 2 40 байт
Подання соізмерності одиниць виміру інформації:
Якщо на умовній шкалі зобразити1 біт1.25 міліметром,
те байт в цьому масштабі буде представлений 1 см,
Кбайт (Кілобайт) - 10 - метровим відрізком,
Мбайт (Мегабайт) - 10- кілометровим,
а Гбайт (Гігабайт) витягнеться в10 000 км, Що відповідає відстані від Москви до Владивостока,
Тбайт (Терабайт) - 10 000 000 км
Матеріал для самостійного вивчення по темі Лекції 2
Кодування ASCII
Кодировочная таблиця ASCII (ASCII - American Standard Code for Information Interchange - Американський стандартний код для обміну інформацією).
Всього за допомогою таблиці кодування ASCII (рисунок 1) можна закодувати 256 різних символів. Ця таблиця розділена на дві частини: основну (з кодами від OOh до 7Fh) і додаткову (від 80h до FFh, де буква h позначає приналежність коду до шестнадцатеричной системі числення).
Малюнок 1
Для кодування одного символу з таблиці відводиться 8 біт (1 байт). При обробці текстової інформації один байт може містити код деякого символу - літери, цифри, знака пунктуації, знака дії і т.д. Кожному символу відповідає свій код у вигляді цілого числа. При цьому всі коди збираються в спеціальні таблиці, звані кодіровочние. З їх допомогою виробляється перетворення коду символу в його видиме уявлення на екрані монітора. В результаті будь-який текст в пам'яті комп'ютера представляється як послідовність байтів з кодами символів.
Наприклад, слово hello! буде закодовано наступним чином (таблиця 1).
Таблиця 1
|
код двійковий | ||||||
|
код десятковий |
На малюнку 1 представлені символи, що входять в стандартну (англійську) і розширену (російську) кодування ASCII.
Перша половина таблиці ASCII стандартизована. Вона містить керуючі коди (від 00h до 20h і 77h). Ці коди з таблиці вилучені, так як вони не відносяться до текстових елементів. Тут же розміщуються знаки пунктуації та математичні знаки: 2lh -!, 26h - &, 28h - (, 2Bh - +, ..., великі і малі латинські букви: 41h - A, 61h - а.
Друга половина таблиці містить національні шрифти, символи псевдографіки, з яких можуть бути побудовані таблиці, спеціальні математичні знаки. Нижню частину таблиці кодувань можна замінювати, використовуючи відповідні драйвери - керуючі допоміжні програми. Цей прийом дозволяє застосовувати кілька шрифтів і їх гарнітур.
Дисплей по кожному коду символу повинен вивести на екран зображення символу - не просто цифровий код, а відповідну йому картинку, так як кожен символ має свою форму. Опис форми кожного символу зберігається в спеціальній пам'яті дисплея - знакогенератор. Висвітлення символу на екрані дисплея IBМ PC, наприклад, здійснюється за допомогою точок, що утворюють символьне матрицю. Кожен піксель в такій матриці є елементом зображення і може бути яскравим або темним. Темна точка кодується цифрою 0, світла (яскрава) - 1. Якщо зображати в матричному полі знака темні пікселі точкою, а світлі - зірочкою, то можна графічно зобразити форму символу.
Люди в різних країнах використовують символи для запису слів їхніх рідних Зиков. У наші дні більшість додатків, включаючи системи електронної пошти і веб-браузери, є чисто 8-бітними, тобто вони можуть показувати і коректно сприймати лише 8-бітові символи, відповідно до стандарту ISO-8859-1.
Існує більше 256 символів в світі (якщо врахувати кирилицю, арабську, китайську, японську, корейську та тайський мови), а також з'являються все нові і нові символи. І це створює такі прогалини для багатьох користувачів:
Неможливо використовувати символи різних наборів кодувань в одному і тому ж документі. Так як кожен текстовий документ використовує свій власний набір кодувань, то виникають великі труднощі з автоматичним розпізнаванням тексту.
З'являються нові символи (наприклад: Євро), внаслідок чого ISO розробляє новий стандарт ISO-8859-15, який дуже схожий зі стандартом ISO-8859-1. Різниця полягає в наступному: з таблиці кодування старого стандарту ISO-8859-1 були прибрані символи позначення старих валют, які не використовуються в даний час, для того, щоб звільнити місце під знову з'явилися символи (такі, як Євро). В результаті у користувачів на дисках можуть лежати одні і ті ж документи, але в різних кодуваннях. Рішенням цих проблем є прийняття єдиного міжнародного набору кодувань, який називається універсальним кодуванням або Unicode.
Кодування Unicode
Стандарт запропонований в 1991 році некомерційною організацією «Консорціум Юнікоду» (англ. Unicode Consortium, Unicode Inc.). Застосування цього стандарту дозволяє закодувати дуже велике число символів з різних писемностей: у документах Unicode можуть сусідити китайські ієрогліфи, математичні символи, букви грецького алфавіту, латиниці і кирилиці, при цьому стає непотрібним переключення кодових сторінок.
Стандарт складається з двох основних розділів: універсальний набір символів (англ. UCS, universal character set) і сімейство кодувань (англ. UTF, Unicode transformation format). Універсальний набір символів задає однозначну відповідність символів кодам - елементам кодового простору, що представляє невід'ємні цілі числа. Сімейство кодувань визначає машинне представлення послідовності кодів UCS.
Стандарт Unicode був розроблений з метою створення єдиної кодування символів всіх сучасних і багатьох давніх писемних мов. Кожен символ в цьому стандарті кодується 16 бітами, що дозволяє йому охопити незрівнянно більшу кількість символів, ніж прийняті раніше 8-бітові кодування. Ще однією важливою відмінністю Unicode від інших систем кодування є те, що він не тільки приписує кожному символу унікальний код, але і визначає різні характеристики цього символу, наприклад:
тип символу (прописна буква, мала літера, цифра, розділовий знак і т.д.);
атрибути символу (відображення зліва направо або справа наліво, пробіл, розрив рядка і т.д.);
відповідна прописна або рядкова буква (для малих і великих літер відповідно);
відповідне числове значення (для цифрових символів).
Весь діапазон кодів від 0 до FFFF розбитий на кілька стандартних підмножин, кожне з яких відповідає або алфавітом якоїсь мови, або групі спеціальних символів, подібних за своїми функціями. На наведеній нижче схемі міститься загальний перелік підмножин Unicode 3.0 (малюнок 2).
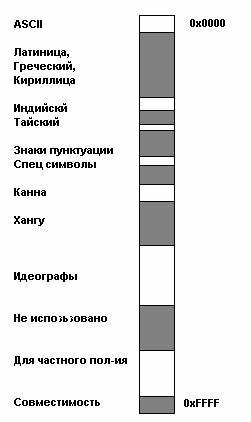
малюнок 2
Стандарт Unicode є основою для зберігання і тексту в багатьох сучасних комп'ютерних системах. Однак, він не сумісний з більшістю Інтернет-протоколів, оскільки його коди можуть містити будь-які байтові значення, а протоколи зазвичай використовують байти 00 - 1F і FE - FF в якості службових. Для досягнення сумісності були розроблені кілька форматів перетворення Unicode (UTFs, Unicode Transformation Formats), з яких на сьогодні найбільш поширеним є UTF-8. Цей формат визначає наступні правила перетворення кожного коду Unicode в набір байтів (від одного до трьох), придатних для транспортування Інтернет-протоколами.
Тут x, y, z позначають біти вихідного коду, які повинні вилучатися, починаючи з молодшого, і заноситися в байти результату справа наліво, поки не будуть заповнені всі зазначені позиції.
Подальший розвиток стандарту Unicode пов'язано з додаванням нових мовних площин, тобто символів в діапазонах 10000 - 1FFFF, 20000 - 2FFFF і т.д., куди передбачається включати кодування для письменностей мертвих мов, що не потрапили в таблицю, наведену вище. Для кодування цих додаткових символів був розроблений новий формат UTF-16.
Таким чином, існує 4 основних способи кодування байтами в форматі Unicode:
UTF-8: 128 символів кодуються одним байтом (формат ASCII), 1920 символів кодуються 2-мя байтами ((Roman, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic символи), 63488 символів кодуються 3-ма байтами (Китайська, японська та ін.) Решту 2 147 418 112 символи (ще не використані) можуть бути закодовані 4, 5 або 6-ю байтами.
UCS-2: Кожен символ представлений 2-ма байтами. Дана кодування включає лише перші 65 535 символів з формату Unicode.
UTF-16: Чи є розширенням UCS-2, налічує 1 114 112 символів формату Unicode. Перші 65 535 символів представлені 2-ма байтами, інші - 4-ма байтами.
USC-4: Кожен символ кодується 4-ма байтами.
| Статті по темі: | |
|
Скільки комбінацій можна закодувати 3 бітами
Поняття про кодування Реферат Зміст 1. Кодування ... Застосування препарату креон для лікування панкреатиту
Креон 10000 як приймати + застосування. Креон 10000 інструкція по ... Скласти нульову звітність ип
(Подають все організації, крім ІП) ССО Зразок нульовий декларації ССО ... | |