вибір читачів




Популярні статті
Мінімальні одиниці виміру інформації - це біт і байт.
Один біт дозволяє закодувати 2 значення (0 або 1).
використовуючи два біта, можна закодувати 4 значення: 00, 01, 10, 11.
трьома битами кодуються 8 різних значень: 000, 001, 010, 011, 100, 101, 110, 111.
З наведених прикладів видно, що додавання одного біта збільшує в 2 рази кількість значень, яке можна закодувати:
1 біт кодує -\u003e 2 різних значення (2 1 = 2),
2 біта кодують -\u003e 4 різних значення (2 2 = 4),
3 біта кодують -\u003e 8 різних значень (2 3 = 8),
4 біта кодують -\u003e 16 різних значень (2 4 = 16),
5 біт кодують -\u003e 32 різних значення (2 5 = 32),
6 біт кодують -\u003e 64 різних значення (2 6 = 64),
7 біт кодують -\u003e 128 різних значення (2 7 = 128),
8 біт кодують -\u003e 256 різних значень (2 8 = 256),
9 біт кодують -\u003e 512 різних значень (2 9 = 512),
10 біт кодують -\u003e 1024 різних значень (2 10 = 1024).
Ми пам'ятаємо, що в одному байті не 9 і не 10 біт, а всього 8. Отже, за допомогою одного байта можна закодувати 256 різних символів. Як Ви думаєте, багато це чи мало? Давайте подивимося на прикладі кодування текстової інформації.
У російській мові 33 букви і, отже, для їх кодування треба 33 байта. Комп'ютер розрізняє великі (великі) і маленькі (рядкові) букви, тільки якщо вони кодуються різними кодами. Значить, щоб закодувати великі і маленькі літери російського алфавіту, буде потрібно 66 байт.
Для великих і маленьких букв англійського алфавіту буде потрібно ще 52 байта. У підсумку виходить 66 + 52 = 118 байт. Сюди треба ще додати цифри (від 0 до 9), символ «пропуск», все знаки пунктуації: крапку, кому, тире, знак і знак питання знаки, дужки: круглі, фігурні і квадратні, а також знаки математичних операцій: +, -, =, / (цей поділ), * (це множення). Додамо також спеціальні символи:%, $, &, @, #, № та ін. Все це разом узяте якраз і становить близько 256 різних символів.
А далі справа залишилася за малим. Треба зробити так, щоб всі люди на Землі домовилися між собою про те, які саме коди (з 0 до 255, тобто всього 256) привласнити символам. Припустимо, все люди домовилися, що код 33 означає знак оклику (!), А код 63 - знак питання (?). І так само - для всіх застосовуваних символів. Тоді це буде означати, що текст, набраний одним людиною на своєму комп'ютері, завжди можна буде прочитати і роздрукувати іншій людині на іншому комп'ютері.
Така загальна домовленість про однакове використання чого-небудь називається стандартом. У нашому випадку стандарт повинен представляти із себе таблицю, в якій зафіксовано відповідність кодів (з 0 до 255) і символів. Подібна таблиця називається таблицею кодування.
Але не все так просто. Адже символи, які гарні, наприклад, для Греції, не підійдуть для Туреччини тому, що там використовуються інші літери. Аналогічно то, що добре для США, не підійде для Росії, а то, що підійде для Росії, не годиться для Німеччини.
Тому прийняли рішення розділити таблицю кодів навпіл.
Перші 128 кодів (з 0 до 127) повинні бути стандартними і обов'язковими для всіх країн і для всіх комп'ютерів, це - міжнароднийстандарт.
А з другою половиною таблиці кодів (з 128 до 255) кожна країна може робити все, що завгодно, і створювати в цій половині свій стандарт - національний.
Першу (міжнародну) половину таблиці кодів називають таблицеюASCII, яку створили в США і прийняли в усьому світі. За другу половину кодової таблиці стандарт ASCII не відповідає. Різні країни створюють тут свої національні таблиці кодів. Може бути і так, що в межах однієї країни діють різні стандарти, призначені для різних комп'ютерних систем, але тільки в межах другої половини таблиці кодів.
0-31 - особливі символи, які не друкуються на екрані або на принтері, а служать для виконання спеціальних дій (наприклад, для «перекладу каретки» - переходу тексту на новий рядок, або для «табуляції» - установки курсору на спеціальні позиції в рядку тексту і т.п.).
32 - пробіл (роздільник між словами - це теж символ, що підлягає кодуванні, хоч він і відображається у вигляді «порожнього місця» між словами і символами),
33-47 - спеціальні символи (круглі дужки і ін.) І розділові знаки (крапка, кома та ін.),
48-57 - цифри від 0 до 9,
58-64 - математичні символи (плюс (+), мінус (-), помножити (*), розділити (/) і ін.) І розділові знаки (двокрапка, крапка з комою та ін.),
65-90 - заголовні (прописні) англійські букви,
91-96 - спеціальні символи (квадратні дужки і ін.),
97-122 - маленькі (рядкові) англійські букви,
123-127 - спеціальні символи (фігурні дужки і ін.).
За межами таблиці ASCII, починаючи з цифри 128 по 159, йдуть великі (прописні) російські літери, а з 160 по 170 і з 224 по 239 - маленькі (рядкові) російські літери.
Користуючись показаної кодуванням, ми можемо уявити собі, як комп'ютер кодує і потім відтворює, наприклад, слово МИР (великими літерами). Це слово представляється трьома кодами: букві М відповідає код 140 (за національною російської системі кодування), І - це код 136 і Р - це 144.
Але як уже говорилося раніше, комп'ютер сприймає інформацію тільки в двійковому вигляді, Тобто у вигляді послідовності нулів та одиниць. Кожен байт, відповідний кожній букві слова МИР, містить послідовність з восьми нулів і одиниць. Використовуючи правила перекладу десяткової інформації в двійкову, можна замінити десяткові значення кодів букв на їх виконавчі аналоги.
Десяткової цифрі 140 відповідає двійкове число 10001100. Це можна перевірити, якщо зробити наступні обчислення: 2 7 + 2 3 + 2 2 = 140. Ступінь, в яку зводиться кожна «двійка» - це номер позиції двійкового числа 10001100, в якій стоїть «1 », причому позиції нумеруються справа наліво, починаючи з нульового номера позиції: 0, 1, 2 і т.д.
Більш докладно про переведення чисел з однієї системи числення в іншу можна дізнатися, наприклад, з підручників з інформатики або через Інтернет.
Аналогічним чином можна переконатися, що цифрі 136 відповідає двійкове число 10001000 (перевірка: 2 7 +2 +3 = 136). А цифрі 144 відповідає двійкове число 10010000 (перевірка: 2 7 + 2 4 = 144).
Таким чином, в комп'ютері слово МИР буде зберігатися у вигляді такої послідовності нулів і одиниць (біт): 10001100 10001000 10010000.
Зрозуміло, що всі показані вище перетворення даних виробляються за допомогою комп'ютерних програм, і вони не видно користувачам. Вони лише спостерігають результати роботи цих програм, як при введенні інформації за допомогою клавіатури, так і при її виведенні на екран монітора або на принтер.
Слід зазначити, що на рівні вивчення комп'ютерної грамотності користувачам комп'ютерів не обов'язково знати двійкову систему числення. Досить мати уявлення про десяткових кодах символів. Тільки системні програмісти на практиці використовують двійкову, шестнадцатеричную, вісімкову і інші системи числення. Особливо це важливо для них, коли комп'ютери виводять повідомлення про помилки в програмному забезпеченні, в яких зазначаються помилкові значення без перетворення в десяткову систему.
Вправи з комп'ютерної грамотності, Що дозволяють самостійно побачити і відчути описані системи кодувань, наведені в статті
P.S. Стаття закінчилася, але можна ще прочитати:
P.P.S.щоб підписатися на отримання нових статей, Яких ще немає на блозі:
1) Введіть Ваш e-mail адресу в цю форму.
Всім відомо, що комп'ютери можуть виконувати обчислення з великими групами даних на величезній швидкості. Але не всі знають, що ці дії залежать від двох умов: є чи ні ток і яка напруга.
Яким же чином комп'ютер примудряється обробляти таку різноманітну інформацію?
Секрет полягає в двійковій системі числення. Всі дані надходять в комп'ютер, представлені у вигляді одиниць і нулів, кожному з яких відповідає один стан електропроводи: одиницям - висока напруга, нулях - низька або ж одиницям - наявність напруги, нулях - його відсутність. Перетворення даних в нулі і одиниці називається двійковій конверсією, а остаточне їх позначення - двійковим кодом.
У десятковому позначенні, заснованому на десятковій системі числення, яка використовується у повсякденному житті, числове значення представлено десятьма цифрами від 0 до 9, і кожне місце в числі має цінність в десять разів вище, ніж місце праворуч від нього. Щоб уявити число більше дев'яти в десятковій системі числення, на його місце ставиться нуль, а на наступне, більш цінне місце зліва - одиниця. Точно так же в двійковій системі, де використовуються тільки дві цифри - 0 і 1, кожне місце в два рази цінніше, ніж місце праворуч від нього. Таким чином, в двійковому коді тільки нуль і одиниця можуть бути зображені як одномісні числа, і будь-яке число, більше одиниці, вимагає вже два місця. Після нуля і одиниці наступні три довічних числа це 10 (читається один-нуль) і 11 (читається один-один) і 100 (читається один-нуль-нуль). 100 двійковій системи еквівалентно 4 десяткової. На верхній таблиці праворуч показані інші двійковій-десяткові еквіваленти.
Будь-яке число може бути виражене в двійковому коді, просто воно займе більше місця, ніж в десятковому позначенні. У двійковій системі можна записати і алфавіт, якщо за кожною буквою закріпити певний двійковечисло.
Дві цифри на чотири місця
16 комбінацій можна скласти, використовуючи темні і світлі кулі, комбінуючи їх в наборах з чотирьох штук Якщо темні кулі прийняти за нулі, а світлі за одиниці, то і 16 наборів виявляться 16-одиничним двійковим кодом, числова цінність якого становить від нуля до п'яти ( см. верхню таблицю на стор. 27). Навіть з двома видами куль в двійковій системі можна побудувати нескінченну кількість комбінацій, просто збільшуючи число кульок в кожній групі - або число місць в числах.
Найменша одиниця в комп'ютерній обробці, біт - це одиниця даних, яка може володіти одним з двох можливих умов. Наприклад, кожна з одиниць і нулів (праворуч) означає 1 біт. Біт можна представити і іншими способами: наявністю або відсутністю електричного струму, дірочкою і її відсутністю, напрямком намагнічування вправо або вліво. Вісім бітів складають байт. 256 можливих байтів можуть уявити 256 знаків і символів. Багато комп'ютерів обробляють байт даних одночасно.
Двійкова конверсія. Чотирицифровий двійкового коду може уявити десяткові числа від 0 до 15.
Коли двійковий код використовується для позначення букв алфавіту або пунктуаційних знаків, потрібні кодові таблиці, В яких зазначено, який код якому символу відповідає. Складено кілька таких кодів. Більшість ПК пристосоване під семіціфровой код, званий ASCII, або американський стандартний код для інформаційного обміну. На таблиці праворуч показані коди ASCII для англійського алфавіту. Інші коди призначаються для тисяч символів і алфавітів інших мов світу.

Частина таблиці коду ASCII
Комп'ютер обробляє велику кількість інформації. Аудіофайли, картинки, тексти - все це необхідно відтворити або вивести на екран. Чому двійкове кодування є універсальним методом програмування інформації будь-якого технічного обладнання?
Найчастіше люди ототожнюють поняття "кодування" та "шифрування", коли насправді вони мають різний зміст. Так, шифруванням називають процес перетворення інформації з метою її приховування. Розшифрувати часто може сама людина, який змінив текст, або спеціально навчені люди. Кодування ж застосовується для обробки інформації і спрощення роботи з нею. Зазвичай використовується загальна таблиця кодування, знайома всім. Вона ж вбудована в комп'ютер.
двійкове кодування грунтується на використанні всього лише двох символів - 0 і 1 - для обробки інформації, використовуваної різними пристроями. Ці знаки назвали двійковими цифрами, англійською - binary digit, або bit. Кожен з символів займає пам'ять комп'ютера в 1 біт. Чому двійкове кодування є універсальним методом обробки інформації? Справа в тому, що комп'ютеру легше обробляти меншу кількість символів. Від цього безпосередньо залежить і продуктивність роботи ПК: чим менше функціональних завдань потрібно виконати пристрою, тим вище швидкість і якість роботи. 
Принцип двійкового кодування зустрічається не тільки в програмуванні. За допомогою чергування глухих і дзвінких ударів барабана жителі Полінезії передавали інформацію одне одному. Подібний принцип застосовується і в де для передачі повідомлення використовуються довгі і короткі звуки. «Телеграфний абетка» використовується і сьогодні.
Двійкове в комп'ютері використовується повсюдно. Кожен файл, будь то музика або текст, повинен бути запрограмований, щоб в подальшому він міг бути легко оброблений і прочитаний. Система двійкового кодування корисна для роботи з символами і числами, аудіофайлами, графікою.
Зараз в комп'ютерах числа представлені в закодованому вигляді, незрозумілому для звичайної людини. Використання арабських цифр так, як ми собі уявляємо, для техніки нераціонально. Причиною тому є необхідність привласнювати кожному числу свою неповторний символ, що зробити часом неможливо.

Існують дві системи числення: позиційна і непозиційних. Непозиційних система заснована на використанні латинських букв і знайома нам у вигляді Такий спосіб запису досить складний для розуміння, тому від нього відмовилися.
Позиційна система числення використовується і сьогодні. Сюди входить двоичное, десяткове, вісімкове і навіть шестнадцатеричное кодування інформації.
Десяткової системою кодування ми користуємося в побуті. Це звичні для нас які зрозумілі кожній людині. Двійкове кодування чисел відрізняється використанням тільки нуля і одиниці.
Цілі числа переводяться в двійкову систему кодування шляхом ділення їх на 2. Отримані приватні також поетапно діляться на 2, поки не вийде в підсумку 0 або 1. Наприклад, число 123 10 в двійковій системі може бути представлено у вигляді 1111011 2. А числа 20 10 буде виглядати як 10100 2.
Індекси 10 і 2 позначаються, відповідно, десяткову і двійкову систему кодування чисел. Символ двійкового кодування використовується для спрощення роботи зі значеннями, представленими в різних системах числення.
Методи програмування десяткових чисел засновані на "плаваючою комою". Для того щоб правильно перевести значення з десяткової в двійкову систему кодування, використовують формулу N = M х qp. М - це мантиса (вираз числа без будь-якого порядку), p - це порядок значення N, а q - основа системи кодування (в нашому випадку 2).
Не всі числа є позитивними. Для того щоб розрізнити позитивні і негативні числа, комп'ютер залишає місце в 1 біт для кодування знака. Тут нуль представляє знак плюс, а одиниця - мінус.
Використання такої системи числення спрощує для комп'ютера роботу з числами. Ось чому двійкове кодування є універсальним при обчислювальних процесах.

Кожен символ алфавіту кодується своїм набором нулів та одиниць. Текст складається з різних символів: букв (великих і малих), арифметичних знаків і інших різних значень. Кодування текстової інформації вимагає використання 8 послідовних довічних значень від 00000000 до 11111111. Таким чином можна перетворити 256 різних символів.
Щоб не було плутанини в кодуванні тексту, використовуються спеціальні таблиці значень для кожного символу. У них присутня латинський алфавіт, арифметичні знаки і знаки особливого призначення (наприклад, €, ¥, і інші). Символи проміжку 128-255 кодують національний алфавіт країни.
Для кодування 1 символу потрібно 8 біт пам'яті. Для спрощення подстчетов 8 біт прирівнюються до 1 байту, тому загальне місце на диску для текстової інформації вимірюється в байтах.

Більшість персональних комп'ютерів оснащені стандартною таблицею кодування ASCII (American Standard Code for Information Interchange). Також використовуються інші таблиці, в яких система кодування текстової інформації відрізняється. Наприклад, перша відома кодування символів називається ЯКІ-8 (код обміну інформацією 8-бітний), і працює вона на комп'ютерах з операційною системою UNIX. Також широко зустрічається таблиця кодів СР1251, яка була створена для операційної системи Windows.
Ще одна причина, чому двійкове кодування є універсальним методом програмування інформації, - це його простота при роботі з аудіофайлами. Будь-яка музика є звукові хвилі різної амплітуди і частоти коливання. Від цих параметрів залежить гучність звуку і його висота тону.
Щоб запрограмувати звукову хвилю, комп'ютер ділить її умовно на кілька частин, або «вибірок». Число таких вибірок може бути великим, тому існує 65536 різних комбінацій нулів і одиниць. Відповідно, сучасні комп'ютери оснащені 16-бітними звуковими картами, що означає використання 16 довічних цифр для кодування однієї вибірки звукової хвилі.
Щоб відтворити аудіофайл, комп'ютер обробляє запрограмовані послідовності двійкового коду і з'єднує їх в одну безперервну хвилю. 
Графічна інформація може бути представлена у вигляді малюнків, схем, зображень або слайдів в PowerPoint. Будь-яка картинка складається з дрібних точок - пікселів, які можуть бути пофарбовані в різний колір. Колір кожного пікселя кодується і зберігається, і в результаті ми отримуємо повноцінне зображення.
Якщо картинка чорно-біла, код кожного пікселя може бути або одиницею, або нулем. Якщо використовується 4 кольори, то код кожного з них складається з двох цифр: 00, 01, 10 або 11. За цим принципом розрізняють якість обробки будь-якого зображення. Збільшення або зменшення яскравості також впливає на кількість використовуваних квітів. У кращому випадку комп'ютер розрізняє близько 16 777 216 відтінків.

Існують різні методи програмування інформації, серед яких двійкове кодування є найбільш ефективним. Всього лише за допомогою двох символів - 1 і 0 - комп'ютер легко прочитує більшість файлів. При цьому швидкість обробки набагато вище, ніж використовувалася б, наприклад, десяткова система програмування. Простота цього методу робить його незамінним для будь-якої техніки. Ось чому двійкове кодування є універсальним серед своїх аналогів.
Давайте розберемося як же все таки перекладати тексти в цифровий код? До речі, на нашому сайті ви можете перевести будь-який текст в десятковий, шістнадцятковий, двійковий код скориставшись Калькулятором кодів онлайн.
За теорією ЕОМ будь-який текст складається з окремих символів. До цих символів відносяться: літери, цифри, рядкові знаки пунктуації, спеціальні символи ( «», №, (), і т.д.), до них, так само, відносяться прогалини між словами.
Необхідний багаж знань. Безліч символів, за допомогою яких записую текст, називається алфавітом.
Число взятих в алфавіті символів, представляє його потужність.
Кількість інформації можна визначити за формулою: N = 2b
Алфавіт, в якому буде 256 може вмістити в себе практично всі потрібні символи. Такі алфавіти називають досить.
Якщо взяти алфавіт потужністю 256, і мати на увазі що 256 = 28
Якщо перевести кожен символ в двійковий код, то цей код комп'ютерного тексту буде займати 1 байт.
Будь-який текст набирають на клавіатурі, на клавішах клавіатури, ми бачимо звичні для нас знаки (цифри, букви і т.д.). В оперативну пам'ять комп'ютера вони потрапляють тільки у вигляді двійкового коду. Двійковий код кожного символу, виглядає восьмизначним числом, наприклад 00111111.
Оскільки, байт - це найменша адресується частка пам'яті, і пам'ять звернена до кожного символу окремо - зручність такого кодування очевидно. Однак, 256 символів - це дуже зручне кількість для будь-якої символьної інформації.
Природно, постало питання: Який конкретно восьми розрядний код належить кожному символу? І як здійснити переклад тексту в цифровий код?
Цей процес умовний, і ми маємо право придумати різні способи для кодування символів. Кожен символ алфавіту має свій номер від 0 до 255. І кожному номеру присвоєно код від 00000000 до 11111111.
Таблиця для кодування - це «шпаргалка», в якій вказані символи алфавіту відповідно порядковому номеру. Для різних типів ЕОМ використовують різні таблиці для кодування.
ASCII (або Аски), стала міжнародним стандартом для персональних комп'ютерів. Таблиця має дві частини.
Перша половина для таблиці ASCII. (Саме перша половина, стала стандартом.)
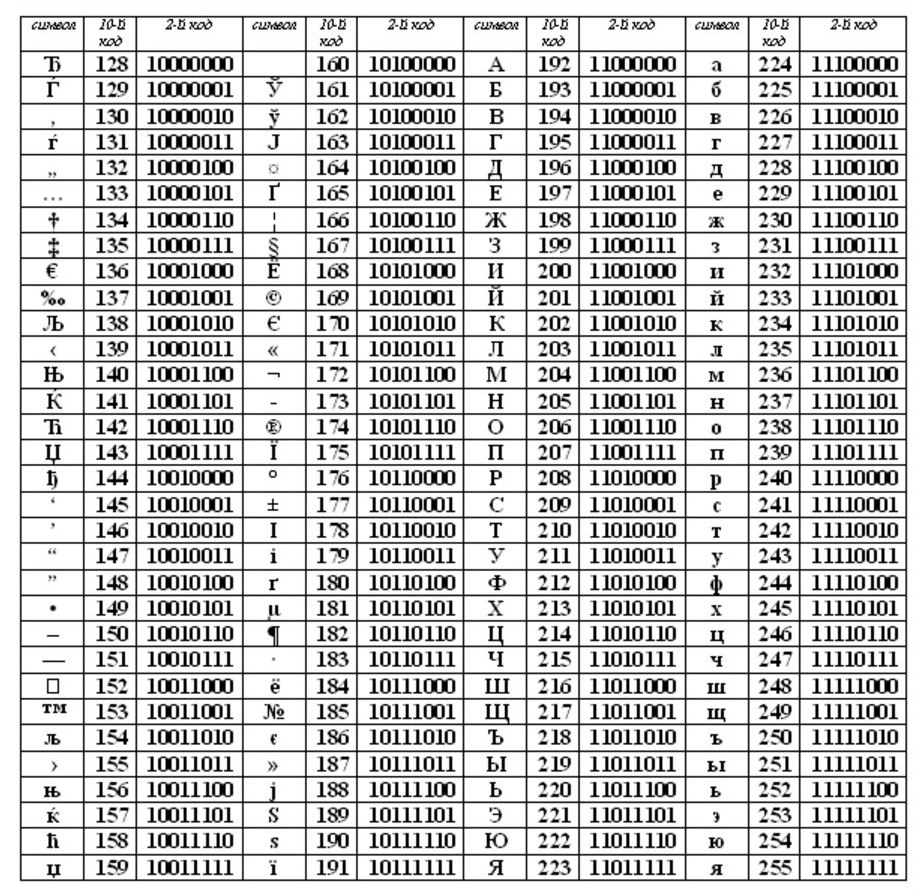
Дотримання лексикографічного порядку, тобто, в таблиці літери (Малі та великі) вказані в строгому алфавітному порядку, а цифри по зростанню, називають принципом последовального кодування алфавіту.
Для російського алфавіту теж дотримуються принцип послідовного кодування.
Зараз, в наш час використовують цілих п'ять систем кодувань російського алфавіту (КОІ8-Р, Windows. MS-DOS, Macintosh і ISO). Через кількості систем кодувань і відсутності одного стандарту, дуже часто виникають непорозуміння з перенесенням російського тексту в комп'ютерний його вид.
Одним з перших стандартів для кодування російського алфавіта на персональних комп'ютерах вважають КОІ8 ( "Код обміну інформацією, 8-бітний"). Дана кодування використовувалася в середині сімдесятих років на серії комп'ютерів ЄС ЕОМ, а з середини вісімдесятих, її починають використовувати в перших перекладених російською мовою операційних системах UNIX.
З початку дев'яностих років, так званого, часу, коли панувала операційна система MS DOS, з'являється система кодування CP866 ( "CP" означає "Code Page", "кодова сторінка").
Гігант комп'ютерних фірм APPLE, зі своєю інноваційною системою, під упраління якої вони і працювали (Mac OS), починають використовувати власну систему для кодування алфавіту МАС.
Міжнародна організація стандартизації (International Standards Organization, ISO) призначає стандартом для російської мови ще одну систему для кодування алфавіту, Яка називається ISO 8859-5.
А найпоширеніша, в наші дні, система для кодування алфавіту, придумана в Microsoft Windows, і називається CP1251.
З другої половини дев'яностих років, була вирішена проблема стандарту перекладу тексту в цифровий код для російської мови і не тільки, введенням в стандарт системи, під назвою Unicode. Вона представлена шестнадцатіразрядного кодуванням, це означає, що на кожен символ відводиться рівно по два байта оперативної пам'яті. Само собою, при такій кодуванні, витрати пам'яті збільшені в два рази. Однак, така кодова система дозволяє переводити в електронний код до 65536 символів.
Специфіка стандартної системи Unicode, є включенням в себе абсолютно будь-якого алфавіту, будь він існуючим, вимерлим, вигаданим. В кінцевому рахунку, абсолютно будь-який алфавіт, в добавок до цього, система Unicode, включає в себе безліч математичних, хімічних, музичних і загальних символів.
Давайте за допомогою таблиці ASCII подивимося, як може виглядати слово в пам'яті вашого комп'ютера.

Дуже часто трапляється так, що ваш текст, який написаний літерами з російського алфавіту, не читається, це зумовлено відмінностями систем кодування алфавіту на комп'ютерах. Це дуже поширена проблема, яка досить часто виявляється.
| Статті по темі: | |
|
Заборони та обмеження на електронні сигарети в різних країнах за останній рік
Отже, сьогодні ми продовжимо огляд списком країн, де можна і де не можна ... Механічний мод (Електронна сигарета) своїми руками
РОЗПРОДАЖ !!! iSmoka iJust 2 - оновлена версія вже знайомого багатьом ... Слина містить різні хімічні речовини
Слинні залози - залози, що відносяться до переднього відділу травного ... | |




