вибір читачів




Популярні статті
Якщо кожному символу алфавіту зіставити певне ціле число (наприклад, порядковий номер), то за допомогою двійкового коду можна кодувати і текстову інформацію. Восьми двійкових розрядів достатньо для кодування 256 різних символів. Цього вистачить, щоб висловити різними комбінаціями восьми бітів все символи англійської та російської мов, як малі, так і великі, а також знаки пунктуації, символи основних арифметичних дій і деякі загальноприйняті спеціальні символи, наприклад символ «§».
Технічно це виглядає дуже просто, проте завжди існували досить вагомі організаційні складності. У перші роки розвитку обчислювальної техніки вони були пов'язані з відсутністю необхідних стандартів, а в даний час викликані, навпаки, достатком одночасно діючих і суперечливих стандартів. Для того щоб весь світ однаково кодували текстові дані, потрібні єдині таблиці кодування, а це поки неможливо через суперечності між символами національних алфавітів, а також протиріч корпоративного характеру.
Для англійської мови, який захопив де-факто нішу міжнародного засобу спілкування, протиріччя вже зняті. Інститут стандартизації США (ANSI - American National Standard Institute) ввів в дію систему кодування ASCII (American Standard Code for Information Interchange - стандартний код інформаційного обміну США). В системі ASCIIзакреплени дві таблиці кодування - базова і розширена. Базова таблиця закріплює значення кодів від 0 до 127, а розширена відноситься до символів з номерами від 128 до 255.
Перші 32 коду базової таблиці, починаючи з нульового, віддані виробникам апаратних засобів (в першу чергу виробникам комп'ютерів і друкуючих пристроїв). У цій області розміщуються так звані керуючі коди, яким не відповідають ніякі символи мов, і, відповідно, не отримали ці коди виводяться ні на екран, ні на пристрої друку, але ними можна керувати тим, як проводиться висновок інших даних.
Починаючи з коду 32 по код 127 розміщені коди символів англійського алфавіту, розділових знаків, цифр, арифметичних дій і деяких допоміжних символів. Базова таблиця кодування ASCII приведена в таблиці 1.1.
Аналогічні системи кодування текстових даних були розроблені і в інших країнах. Так, наприклад, в СРСР в цій області діяла система кодування КОІ7 (код обміну інформацією, семизначний). Однак підтримка виробників обладнання та програм вивела американський код ASCII на рівень міжнародного стандарту, і національним системам кодування довелося «відступити» в другу, розширену частину системи кодування, що визначає значення кодів з 128 по 255. Відсутність єдиного стандарту в цій галузі призвело до множинності одночасно діючих кодувань. Тільки в Росії можна вказати три діючих стандарту кодування і ще два застарілих.
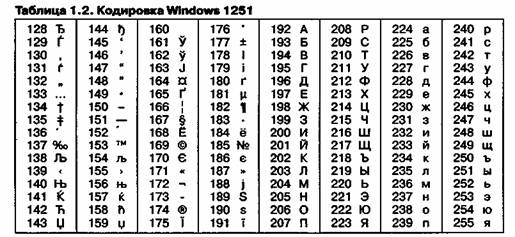
Так, наприклад, кодування символів російської мови, відома як кодування Windows 1251, була введена «ззовні» - компанією Microsoft, але, з огляду на широке поширення операційних систем і інших продуктів цієї компанії в Росії, вона глибоко закріпилася і знайшла широке поширення (таблиця 1.2) . Ця кодування використовується на більшості локальних комп'ютерів, що працюють на платформі Windows.
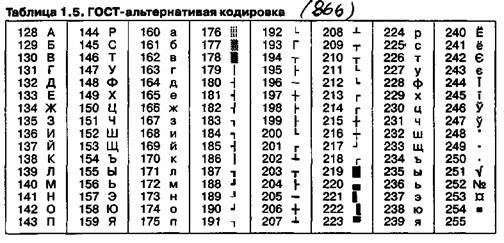
Інша поширена кодування носить назву КОІ8 (код обміну інформацією, восьмизначний) - її походження відноситься до часів дії Ради Економічної Взаємодопомоги держав Східної Європи (табліца1.3). Сьогодні кодування КОІ8 має широке поширення в комп'ютерних мережах на території Росії і в російському секторі Інтернету.
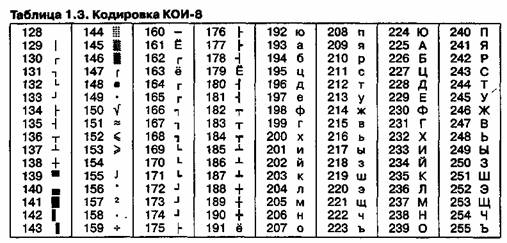
Міжнародний стандарт, в якому передбачена кодування символів російського алфавіту, носить назву кодування ISO (International Standard Organization - Міжнародний інститут стандартизації). На практиці дана кодування використовується рідко (таблиця 1.4).
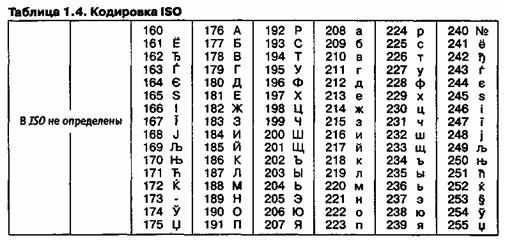
На комп'ютерах, що працюють в операційних системах MS-DOS, можуть діяти ще два кодування (кодування ГОСТ і кодування ГОСТ-альтернативна). Перша з них вважалася застарілою навіть в перші роки появи персональної обчислювальної техніки, але друга використовується і до цього дня (див. Таблицю 1.5).
У зв'язку з великою кількістю систем кодування текстових даних, що діють в Росії, виникає задача межсистемного перетворення даних - це одна з поширених завдань інформатики.
Якщо проаналізувати організаційні труднощі, пов'язані зі створенням єдиної системи кодування текстових даних, то можна прийти до висновку, що вони викликані обмеженим набором кодів (256). У той же час очевидно, що якщо, наприклад, кодувати символи НЕ восьмирозрядних двійковими числами, а числами з великою кількістю розрядів, то і діапазон можливих значень кодів стане на багато більше. Така система, заснована на 16разрядном кодуванні символів, отримала назву універсальної - UNICODE .Шестнадцать розрядів дозволяють забезпечити унікальні коди для 65 536 різних символів - цього поля досить для розміщення в одній таблиці символів більшості мов планети.
Незважаючи на тривіальну очевидність такого підходу, простий механічний перехід на дану систему тривалий час стримувався через недостатні ресурсів засобів обчислювальної техніки (під час передачі сигналу UNICODE всі текстові документи автоматично стають вдвічі довше). У другій половині 90хгодов технічні засоби досягли необхідного рівня забезпеченості ресурсами, і сьогодні ми спостерігаємо поступове переведення документів і програмних засобів на універсальну систему кодування. Для індивідуальних користувачів це ще більше додало турбот за погодженням документів, виконаних в різних системах кодування, з програмними засобами, але це треба розуміти як труднощі перехідного періоду.
Розглянуто основи інформатики та описані сучасні апаратні засоби персонального комп'ютера. Сформульовано підходи до визначення основних понять в галузі інформатики та розкрито їх зміст. Дана класифікація сучасних апаратних засобів персонального комп'ютера і наведено їх основні характеристики. Всі основні положення ілюстровані прикладами, в яких при вирішенні конкретних завдань використовуються відповідні програмні засоби.
при введенні текстової інформації в комп'ютер символи (літери, цифри, знаки) кодуються за допомогою різних кодових систем, які складаються з набору кодових таблиць, розміщених на відповідних сторінках стандартів для кодування текстової інформації. У таких таблицях кожному символу присвоюється певний числовий код в шістнадцятковій або десятковій системі числення, т. Е. Кодові таблиці відображають відповідність між зображеннями символів і числовими кодами і призначені для кодування і декодування текстової інформації. При введенні текстової інформації за допомогою клавіатури комп'ютера кожен символ, що вводиться піддається кодування, т. Е. Перетворюється в числовий код, при виведенні текстової інформації на пристрій виведення комп'ютера (дисплей, принтер або плоттер) по числовому коду символу будується його зображення. Присвоєння символу певного числового коду є результатом угоди між відповідними організаціями різних країн. В даний час немає єдиної універсальної кодової таблиці, що задовольняє буквах національних алфавітів різних країн.
Сучасні кодові таблиці включають в себе міжнародну і національну частини, т. Е. Містять букви латинського та національного алфавітів, цифри, знаки арифметичних операцій і пунктуації, математичні і керуючі символи, символи псевдографіки. Міжнародна частина кодової таблиці, що базується на стандарті ASCII (American Standard Code for Information Interchange),кодує першу половину символів кодової таблиці з числовими кодами від 0 до 7 F 16,або в десятковій системі числення від 0 до 127. При цьому коди від 0 до 20 16 (0? 32 10) відведені функціональних клавіш (F1, F2, F3 і т. д.) клавіатури персонального комп'ютера. На рис. 3.1 приведена міжнародна частина кодових таблиць, заснована на стандарті ASCII.Осередки таблиць пронумеровані відповідно до десяткової і шістнадцятковій системі числення.
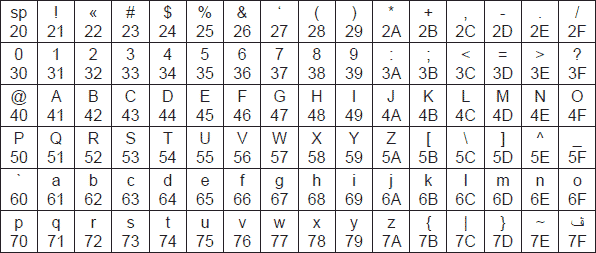
Рис 3.1. Міжнародна частина кодової таблиці (стандарт ASCII)з номерами осередків, представлених в десяткового (а) і шістнадцятковій (б) системі числення
Національна частина кодових таблиць містить коди національних алфавітів, яку називають також таблицею наборів символів (Charset).
В даний час для підтримки букв російського алфавіту (кирилиці) існує кілька кодових таблиць (кодувань), які використовуються різними операційними системами, що є істотним недоліком і в ряді випадків призводить до проблем, пов'язаних з операціями декодування числових значень символів. У табл. 3.1 наведені назви кодових сторінок (стандартів), на яких розміщені кодові таблиці (кодування) кирилиці.
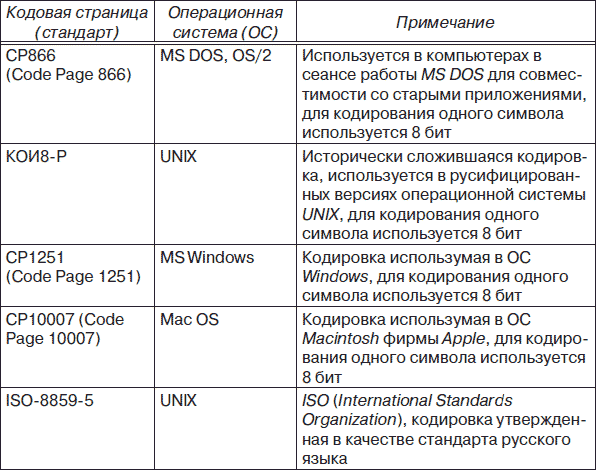
Одним з перших стандартів кодування кирилиці на комп'ютерах був стандарт КОІ8-Р. Національна частина кодової таблиці цього стандарту наведена на рис. 3.2.

Мал. 3.2. Національна частина кодової таблиці стандарту КОІ8-Р
В даний час застосовується і кодова таблиця, розміщена на сторінці ср866 стандарту кодування текстової інформації, яка використовується в операційній системі MS DOSабо сеансі роботи MS DOSдля кодування кирилиці (рис. 3.3, а).


Мал. 3.3. Національна частина кодової таблиці, розміщена на сторінці ср866 (а) і на сторінці СР1251 (б) стандарту кодування текстової інформації
В даний час для кодування кирилиці найбільшого поширення набула кодова таблиця, розміщена на сторінці СР1251 відповідного стандарту, яка використовується в операційних системах сімейства Windowsфірми Microsoft(Рис. 3.2, б).У всіх представлених кодових таблицях, Крім таблиці стандарту Unicode,для кодування одного символу відводиться 8 двійкових розрядів (8 біт).
В кінці минулого століття з'явився новий міжнародний стандарт Unicode,в якому один символ представляється двобайтовим двійковим кодом. Застосування цього стандарту - продовження розробки універсального міжнародного стандарту, що дозволяє вирішити проблему сумісності національних кодувань символів. За допомогою даного стандарту можна закодувати 2 16 = 65536 різних символів. На рис. 3.4 приведена кодова таблиця 0400 (російський алфавіт) стандарту Unicode.
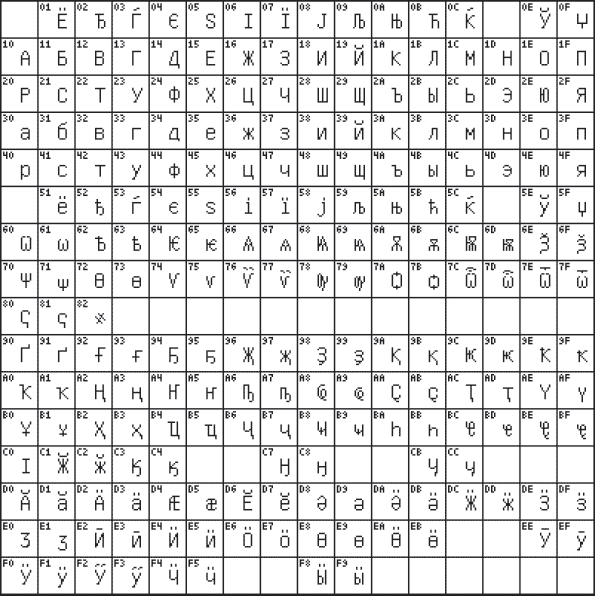
Мал. 3.4. Кодова таблиця 0400 стандарту Unicode
Пояснимо сказане, що стосується кодування текстової інформації, на прикладі.
Закодувати слово «Комп'ютер» у вигляді послідовності десяткових і шістнадцяткових чисел, використовуючи кодування СР1251. Які символи будуть відображені в кодових таблицях ср866 і КОІ8-Р при використанні отриманого коду.
Послідовності шістнадцятирічного і двійкового коду слова «Комп'ютер» на основі кодувальної таблиці СР1251 (див. Рис. 3.3, б)будуть виглядати наступним чином:
Дана кодова послідовність в кодуваннях ср866 і КОІ8-Р призведе до відображення наступних символів:
Для перетворення російськомовних текстових документів з одного стандарту кодування текстової інформації в інший використовуються спеціальні програми - конвертори. Конвертори зазвичай вбудовуються в інші програми. Прикладом може служити програма браузер - Internet Explorer (IE),яка має вбудований конвертор. Програма браузер - це спеціальна програма для перегляду вмісту Web-сторінокв глобальній комп'ютерній мережі Інтернет. Скористаємося цією програмою для підтвердження отриманого в прикладі 3.1 результату відображення символів. Для цього слід виконати такі дії.
1. Запустимо програму Блокнот (NotePad).Програма Блокнот в операційній системі Windows ХРзапускається за допомогою команди: [Кнопка Пуск - Програми - Стандартні - Блокнот]. У вікні програми Блокнот надрукуємо слово «Комп'ютер» з використанням синтаксису мови розмітки гіпертекстових документів - HTML (Hyper Text Markup Language).Ця мова використовується для створення документів в Інтернеті. Текст повинен виглядати наступним чином:
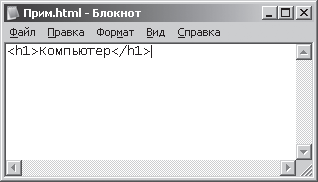
Мал. 3.5. Відображення тексту в вікні Блокнот
Збережемо цей текст, виконавши команду: [Файл - Зберегти як ...] у відповідній папці комп'ютера, при збереженні тексту файлу дамо ім'я - Прим, з розширенням файлу. html.
2. Запустимо програму Internet Explorer,виконавши команду: [Кнопка Пуск - Програми - Internet Explorer].При запуску програми з'явиться вікно, представлене на рис. 3.6
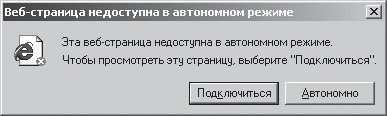
Мал. 3.6. Вікно доступу в автономний режим
Виберемо і активізуємо кнопку автономнопри цьому не відбудеться підключення комп'ютера до глобальної мережі Інтернет. З'явиться головне вікно програми Microsoft Internet Explorer,представлене на рис. 3.7.
Мал. 3.7. Основне вікно Microsoft Internet Explorer
Текстова інформація складається з символів: букв, цифр, знаків пунктуації та ін. Одного байта досить для зберігання 256 різних значень, що дозволяє розміщувати в ньому будь-який з алфавітно-цифрових символів. Перші 128 символів (що займають сім молодших біт) стандартизовані за допомогою кодування ASCII (American Standart Code for Information Interchange). Суть кодування полягає в тому, що кожному символу ставлять у відповідність двійковий код від 00000000 до 11111111 або відповідний йому десятковий код від 0 до 255. Для кодування російських букв використовують різні кодові таблиці (КОI-8R, СР1251, CP10007, ISO-8859-5):
KOI8R - восьмибитового стандарт кодування букв кириличних алфавітів (для операційної системи UNIX). розробники KOI8R помістили символи російського алфавіту в верхній частині розширеної таблиці ASCII таким чином, що позиції кириличних символів відповідають їх фонетичним аналогам в англійському алфавіті в нижній частині таблиці. Це означає, що з тексту написаного в KOI8R, Виходить текст, написаний латинськими символами. Наприклад, слова «будинок високий» набувають форму «dom vysokiy»;
СР1251 - восьмибитового стандарт кодування, що використовується в OS Windows;
CP10007- восьмибитового стандарт кодування, що використовується в кирилиці операційної системи Macintosh (комп'ютерів фірми Apple);
ISO-8859-5 - восьмибитового код, затверджений як стандарт для кодування російської мови.
Графічну інформацію можна представляти в двох формах: аналогової і дискретної. живописне полотно, Створене художником, - це приклад аналогового уявлення, А зображення, надруковане за допомогою принтера, Що складається з окремих (елементів) точок різного кольору, - це дискретне уявлення.
Шляхом розбиття графічного зображення (дискретизації) відбувається перетворення графічної інформації з аналогової форми в дискретну. При цьому проводиться кодування - присвоєння кожному елементу графічного зображення конкретного значення в формі коду. Створення і зберігання графічних об'єктів можливо в декількох видах - у вигляді векторного, фрактального або реєстрового зображення. окремим предметом вважається 3D (тривимірна) графіка, В якій поєднуються векторний і растровий способи формування зображень.
Векторна графіка використовується для представлення таких графічних зображень як малюнки, креслення, схеми.
Вони формуються з об'єктів - набору геометричних примітивів (точки, лінії, кола, прямокутники), яким присвоюються деякі характеристики, наприклад, товщина ліній, колір заповнення.
Зображення у векторному форматі спрощує процес редагування, так як зображення може без втрат масштабироваться, повертатися, деформуватися. При цьому кожне перетворення знищує старе зображення (або фрагмент), і замість нього будується нове. Такий спосіб представлення хороший для схем і ділової графіки. При кодуванні векторного зображення зберігається не саме зображення об'єкта, а координати точок, використовуючи які програма кожен раз відтворює зображення заново.
основним недоліком векторної графіки є неможливість зображення фотографічної якості. У векторному форматі зображення завжди буде виглядати, як малюнок.
Растрова графіка. Будь-яку картинку можна розбити на квадрати, отримуючи, таким чином, растр - двовимірний масив квадратів. Самі квадрати - елементи растра або пікселі (Picture "s element) - елементи картинки. Колір кожного пікселя кодується числом, що дозволяє для опису картинки задавати порядок номерів квітів (зліва направо або зверху вниз). На згадку записується номер кожного осередку, в якій зберігається піксель.
Малюнок в растровому форматі
Кожному пікселю зіставляються значення яскравості, кольору, і прозорості або комбінація цих значень. Растровий образ має деяке число рядків і стовпців. Цей спосіб зберігання має свої недоліки: більший обсяг пам'яті, необхідний для роботи з зображеннями.
Обсяг растрового зображення визначається множенням кількості пікселів на інформаційний обсяг однієї точки, який залежить від кількості можливих кольорів. У сучасних комп'ютерах в основному використовують наступні роздільні здатності екрану: 640 на 480, 800 на 600, 1024 на 768 і 1280 на 1024 пікселів. Яскравість кожної точки і її координати можна виразити за допомогою цілих чисел, що дозволяє використовувати двійковий код для того щоб обробляти графічні дані.
У найпростішому випадку (чорно-біле зображення без градацій сірого кольору) кожна точка екрану може мати одне з двох станів - «чорна» або «біла», тобто для зберігання її стану необхідно 1 біт. Кольорові зображення формуються відповідно до двійковим кодом кольору кожної точки, що зберігаються у відеопам'яті. Кольорові зображення можуть мати різну глибину кольору, яка задається кількістю бітів, що використовуються для кодування кольору точки. Найбільш поширеними значеннями глибини кольору є 8, 16, 24, 32, 64 біта.
Для кодування кольорових графічних зображень довільний колір ділять на його складові. Використовуються такі системи кодування:
HSB (H - відтінок (hue), S - насиченість (saturation), B - яскравість (brightness)),
RGB (Red - червоний, Green - зелений, Blue - синій) і
CMYK ( Cyan - блакитний, Magenta - пурпурний, Yellow - жовтий і Black - чорний).
Перша система зручна для людини, Друга - для комп'ютерної обробки, А остання - для друкарень. Використання цих колірних систем пов'язано з тим, що світловий потік може формуватися випромінюваннями, що представляють собою комбінацію "чистих" спектральних кольорів: червоного, зеленого, синього або їх похідних.
фрактал - це об'єкт, окремі елементи якого успадковують властивості батьківських структур. Оскільки більш детальний опис елементів меншого масштабу відбувається по простому алгоритму, описати такий об'єкт можна всього лише декількома математичними рівняннями. Фрактали дозволяють описувати зображення, для детального уявлення яких потрібно відносно мало пам'яті.

Малюнок в фрактальному форматі
Тривимірна графіка (3D) оперує з об'єктами в тривимірному просторі. Комп'ютерна графіка широко використовується в кіно, комп'ютерних іграх, де всі об'єкти представляються як набір поверхонь або частинок. Всіма візуальними перетвореннями в 3D-графіці управляють за допомогою операторів, що мають матричне уявлення.
Кодування звукової інформації
Музика, як і будь-який звук, є не чим іншим, як звуковими коливаннями, зареєструвавши які, її можна досить точно відтворити. Для подання звукового сигналу в пам'яті комп'ютера, необхідно надійшли акустичні коливання уявити в цифровому вигляді, тобто перетворити в послідовність нулів і одиниць. За допомогою мікрофона звук перетворюється в електричні коливання, після чого можна виміряти амплітуду коливань через рівні проміжки часу (кілька десятків тисяч разів в секунду), використовуючи спеціальний пристрій - аналого-цифровий перетворювач (АЦП). Для відтворення звуку цифровий сигнал необхідно перетворити в аналоговий за допомогою цифро-аналогового перетворювача (ЦАП). Обидва ці пристрої вбудовані в звукову карту комп'ютера. Зазначена послідовність перетворень представлена на рис. 2.6 ..
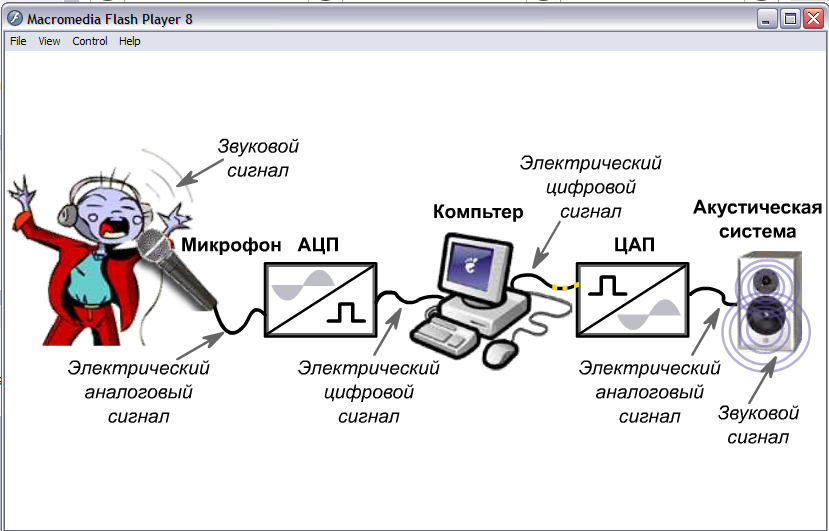
Трансформація аналогового сигналу в цифровий і назад
Кожен вимір звуку записується в двійковому коді. Цей процес називається дискретизацией (семплірованіє),виконуваних за допомогою АЦП.
семпл (Sample англ. Зразок) - це проміжок часу між двома вимірами амплітуди аналогового сигналу. Крім проміжку часу семплом називають також будь-яку послідовність цифрових даних, які отримали шляхом аналого-цифрового перетворення. важливим параметром семплірованіяє частота - кількість вимірювань амплітуди аналогового сигналу в секунду. Діапазон частоти дискретизації звуку від 8000 до 48000 вимірювань за одну секунду.
Графічне представлення процесу дискретизації
На якість відтворення впливають частота дискретизації і дозвіл(Розмір комірки, відведеної під запис значення амплітуди). Наприклад, під час запису музики на компакт-диски використовуються 16-розрядні значення і частота дискретизації 44032 Гц.
На слух людина сприймає звукові хвилі, що мають частоту в межах від 16 Гц до 20 кГц (1 Гц - 1 коливання в секунду).
У форматі компакт-дисків Audio DVD за одну секунду сигнал вимірюється 96 000 разів, тобто застосовують частоту семплірованія 96 кГц. Для економії місця на жорсткому диску в мультимедійних додатках досить часто застосовують менші частоти: 11, 22, 32 кГц. Це призводить до зменшення чутного діапазону частот, а, значить, відбувається перекручування того, що чутно.
Комп'ютер - складний пристрій, за допомогою якого можна створювати, перетворювати і Однак ЕОМ працює не зовсім зрозумілим для нас способом - графічні, текстові і числові дані зберігаються у вигляді масивів двійкових чисел. У даній статті ми розглянемо, як здійснюється кодування текстової інформації.
Те, що для нас є текстом, для ЕОМ - послідовність символів. Кожен символ є певний набір нулів і одиниць. Під символами маються на увазі не тільки великі та малі алфавіту, але також і розділові знаки, арифметичні знаки, службові символи, спеціальні позначення і навіть пробіл.
Двійкове кодування текстової інформації
При натисканні певної клавіші на внутрішній контролер надсилається електричний сигнал, який перетворюється в Код зіставляється з певним символом, який і виводиться на екран. Для подання в цифровому форматі була створена міжнародна система кодування ASCII. У ній для запису одного символу необхідний 1 байт, отже, символ складається з восьмизначний послідовності нулів і одиниць. Інтервал запису - від 00000000 до 11111111, тобто кодування текстової інформації за допомогою даної системи дозволяє уявити 256 символів. У більшості випадків цього буває достатньо. 
ASCII розділена на дві частини. Перші 127 символів (від 00000000 до 01111111) є інтернаціональними і являють собою специфічні символи і букви англійського алфавіту. Друга ж частина - розширення (від 10000000 до 11111111) - призначена для представлення національного алфавіту, написання якого відмінно від латинського.
Кодування текстової інформації в ASCII побудовано за принципом зростаючої послідовності, тобто чим більше порядковий номер латинської літери, тим більше значення її ASCII-коду. Цифри і російська частина таблиці побудовані за тим же принципом.
Однак у світі існує ще кілька видів кодування для букв кирилиці. Найпоширеніші - це ЯКІ-8 (восьмібітного кодування, що застосовувалася вже в 70-х роках на перше руіфіцірованних ОС Unix), ISO 8859-5 (розроблена Міжнародним бюро стандартизації), СР тисячі двісті п'ятьдесят один (кодування текстової інформації, що застосовується в  сучасних ОС Windows), а також 2-байтовая кодування Unicode, за допомогою якої можна уявити 65536 знаків. Таке різноманіття кодувань обумовлено тим, що всі вони розроблялися в різний час, для різних операційних систем і з різних міркувань. Через це часто виникають труднощі при перенесенні тексту з одного носія на інший - при розбіжності кодувань користувач побачить лише набір незрозумілих значків. Як можна виправити цю ситуацію? В Word, наприклад, при відкритті документа видається повідомлення про проблеми з відображенням тексту і пропонується кілька варіантів перекодування.
сучасних ОС Windows), а також 2-байтовая кодування Unicode, за допомогою якої можна уявити 65536 знаків. Таке різноманіття кодувань обумовлено тим, що всі вони розроблялися в різний час, для різних операційних систем і з різних міркувань. Через це часто виникають труднощі при перенесенні тексту з одного носія на інший - при розбіжності кодувань користувач побачить лише набір незрозумілих значків. Як можна виправити цю ситуацію? В Word, наприклад, при відкритті документа видається повідомлення про проблеми з відображенням тексту і пропонується кілька варіантів перекодування.
Отже, кодування і обробка текстової інформації в надрах комп'ютера - процес досить складно організований і трудомісткий. Всі символи будь-якого алфавіту є лише певну послідовність цифр одна осередок - це один байт інформації.
| Статті по темі: | |
|
Коли збирати шишки марихуани
Ми вже підходимо до кінця, і я сподіваюся, що допоміг вам у вирощуванні ... Універсальні препарати для очищення кишечника
Доброго времени суток друзі. З вами Ірина Попова і сьогодні я розповім ... Серологічна діагностика інфекційних хвороб - методи, визначення, суть, правила
Серологічне дослідження, або, іншими словами - серологічний ... | |