вибір читачів



Популярні статті
Кодеки, що стискають звук без втрат, стали користуватися популярністю в світі портативних MP3-плеєра порівняно недавно. Справа в тому, що цим кодекам не під силу такі величезні ступеня стиснення, якими можуть похвалитися кодеки, що стискають звук з втратами якості. Великі обсяги пам'яті стали широко доступні користувачам MP3-плеєр лише останні роки три-чотири - і з приходом великих обсягів пам'яті в MP3 -плеєри, стиснення музики без втрат стало популярним. Звичайно, ті, хто хотів слухати музику без втрат якості, робили це завжди (наприклад, за допомогою Audio CD-програвач), а в наш час всі бажаючі (природно, при наявності підтримки відповідних кодеків їх плеєрами) можуть спробувати Lossless -кодекі в дії .
Головна відмінність кодеків, що стискають звукові дані без втрати якості від кодеків, що стискають з втратами, полягає в тому, що кодеки без втрати якості не видаляють з аудиопотока інформацію, яка при стисненні з втратами може вважатися надмірною. Головне завдання Lossless -кодека полягає в тому, щоб якомога сильніше стиснути вихідну звукову інформацію, не втративши при цьому жодного біта інформації.
Ситуація з підтримкою Lossless -кодеков в даний час така, що найбільш широко поширена підтримка кодека ALAC, який має безпосереднє відношення до фірми Apple і її плеєрів. Решта ж кодеки підтримуються поки небагатьма плеєрами, іноді для того, щоб плеєр підтримував кодек, потрібно перепрошивка плеєра, причому, мабуть, найбільш відома прошивка для плеєрів, що підтримує Lossless -кодекі, RockBox - це альтернативна, а ніяк не офіційна прошивка.
В ході роботи з Lossless -кодекамі вам можуть зустрітися так звані Cue-файли або індексні карти файлів. Cue-файли поширюються, наприклад, разом з FLAC або APE-файлами, рідше - з MP3 і WAV-файл, які представляють собою один великий (близько 300 Мб) файл, в якому зберігається цілий альбом. Cue - файл - містить в собі інформацію про розбиття великого файлу на треки і про назви цих треків. З окремими файлами працювати зручніше, проте, навіть якщо до вас в руки потрапить, скажімо, великий FLAC- файл з CUE-файл, на основі інформації, що міститься в CUE-файл, вихідний файл можна розділити на окремі треки - ми розглянемо ПО, яке може вирішити цю задачу.
Почнемо опис форматів стиснення даних без втрат з популярного формату FLAC.
FLAC (Free Lossless Audio Codec) - це формат стиснення аудіо без втрат, який розробила Xiph. Org Foundation. Це абсолютно безкоштовний формат, яким можуть користуватися всі бажаючі.
Робота FLAC і інших кодеків, які зберігали звукові дані без втрат, нагадує роботу звичайних архиваторов. Однак, за рахунок спеціальних алгоритмів ефективність таких кодеків при стисненні аудіоінформації набагато вище, ніж у звичайних архиваторов.
Формат FLAC розроблявся як потоковий - інформація у FLAC-файлі розбита на фрейми (кадри), кожен з яких може бути розкодувати окремо від інших фреймів.
Як правило, FLAC здатний стиснути вихідний файл, наприклад, Audio CD-якості на 40-50%. В результаті бітрейт отриманої записи виявляється рівним близько 800 Кбіт / c.
У форматі FLAC передбачена можливість збереження CD-дисків таким чином, що при необхідності можна повністю відтворити початковий диск - це дуже зручно для тих, хто хоче створити цифрові копії своїх CD з можливістю подальшого відновлення.
Швидкість кодування і декодування FLAC-файлів неоднакова. Швидкість кодування залежить від рівня стиснення і від швидкості системи - на високих рівнях стиснення вона може бути досить повільної. Однак розкодування ведеться дуже швидко - з ним легко можуть впоратися сучасні MP3 -плеєри.
За рахунок можливості безкоштовного вільного використання, з FLAC можна працювати на базі практично будь-якої сучасної ОС, все більше MP3-плеєра підтримують цей формат.
Завантажити утиліту для кодування FLAC-файлів можна на. Вона включає в себе сам кодек і так званий Frontend - програмну оболонку для кодека. Розмір дистрибутива займає близько 2,5 Мб. Робота з кодеком проста: ви додаєте ваші файли у вікно програми (Рис. 4.1.) за допомогою кнопки Add Files (Додати файли), налаштовуєте опції кодування і натискаєте кнопку Encode (Кодувати) - програма створює FLAC-файл.
Мал. 4.1.
Давайте розглянемо найбільш значущі установки кодека. Для початку зупинимося на групі параметрів Encoding Options (Параметри кодування)
Параметр Level (Рівень) відповідає за рівень стиснення даних. Він може змінюватися від 0 до 8. Чим більше рівень стиснення, тим, відповідно, менше готовий файл, але більше час, необхідний для кодування файлів. На швидких комп'ютерах різниця між Level 0 і Level 8 при кодуванні, скажімо, 30-мегабайтного WAV-файлу може скласти кілька секунд. Розмір відрізняється приблизно на 10% від початкового розміру файлу. Вам варто поекспериментувати з цим параметром на вашому ПК - можливо, якщо ви будете кодувати кілька сотень файлів, ви віддасте перевагу менший рівень стиснення більшої швидкості роботи.
Параметр Verify (Перевірити) наказує кодеру перевірку вихідних файлів.
Параметр Add tags (Додати теги) додає в готовий файл теги (наприклад, вони можуть містити назву композиції, автора і т. Д.) - налаштувати їх можна, натиснувши на кнопку Tag Conf. (Налаштування тегів).
Параметр Replaygain (Рівень програвання) додає в файли параметр, який вказує на рівень гучності файлу. Якщо встановлено параметр Treat input files as one album (Обробляти вхідні файли як один альбом) - все записи в альбомі будуть звучати з однаковою гучністю.
Група параметрів General Options (Загальні параметри) містить два параметри. Мабуть, тут слід зазначити параметр OGG-Flac. Якщо цей параметр скинутий, то FLAC-дані упаковуються в стандартний FLAC-контейнер. Якщо ви плануєте лише прослуховувати отримані FLAC-файли, цей параметр можна не встановлювати, а якщо ваші плани на ці файли більш великі - наприклад, ви плануєте редагувати їх, використовувати їх для вставки в відеофільми, найкраще включити параметр Ogg-FLAC.
Параметр Output Directory (Вихідна директорія) містить шлях до директорії, де будуть міститися вихідні файли.
У групі параметрів Decoding options (Опції декодування) є параметр Dec. Through errors (Декодувати незважаючи на помилки) - встановіть його, якщо хочете декодувати будь-якої файл навіть у тому випадку, якщо під час декодування виникають помилки. Декодування - процес зворотний кодування - тобто декодувати ви можете FLAC-файли, перетворивши їх в WAV-файли. Для декодування, природно, вам доведеться додати в вікно програми FLAC-файли.
Після того, як все налаштовано, досить натиснути на кнопку Encode (Кодувати) для створення FLAC-файлів, або, якщо ви хочете декодувати існуючі FLAC-файли - натисніть кнопку Decode (Декодувати).
Крім вищеописаної, кодувати FLAC можуть і інші програми. Наприклад, це вже відома вам ImTOO Audio Encoder - для кодування в формат FLAC досить вибрати його зі списку форматів (Рис. 4.2.), Після чого можна відразу ж натискати на кнопку Розрізати, або зробити це трохи пізніше, попередньо налаштувавши імена файлів.
Доброго вам дня.
Сьогодні я хочу торкнутися теми стиснення даних без втрат. Незважаючи на те, що на Хабре вже були статті, присвячені деяким алгоритмам, мені захотілося розповісти про це трохи детальніше.
Я постараюся давати як математичний опис, так і опис в звичайному вигляді, для того, щоб кожен міг знайти для себе щось цікаве.
У цій статті я торкнуся фундаментальних моментів стиснення і основних типів алгоритмів.
Зрозуміло, так. Звичайно, всі ми розуміємо, що зараз нам доступні і носії інформації великого обсягу, і високошвидкісні канали передачі даних. Однак, одночасно з цим зростають і обсяги переданої інформації. Якщо кілька років тому ми дивилися 700-мегабайтні фільми, що уміщаються на одну болванку, то сьогодні фільми в HD-якості можуть займати десятки гігабайт.
Звичайно, користі від стиснення всього і вся не так багато. Але все ж існують ситуації, в яких стиснення вкрай корисно, якщо не потрібно.
Звичайно, можна придумати ще безліч різних ситуацій, в яких стиснення виявиться корисним, але нам досить і цих кількох прикладів.
Всі методи стиснення можна розділити на дві великі групи: стиснення з втратами і стиснення без втрат. Стиснення без втрат застосовується в тих випадках, коли інформацію потрібно відновити з точністю до біта. Такий підхід є єдино можливим при стисненні, наприклад, текстових даних.
У деяких випадках, однак, не потрібно точного відновлення інформації та допускається використовувати алгоритми, що реалізують стиснення з втратами, яке, на відміну від стиснення без втрат, зазвичай простіше реалізується і забезпечує більш високу ступінь архівації.
Отже, перейдемо до розгляду алгоритмів стиснення без втрат.
У загальному випадку можна виділити три базові варіанти, на яких будуються алгоритми стиснення.
перша група методів - перетворення потоку. Це передбачає опис нових надходять незжатих даних через уже оброблені. При цьому не обчислюється ніяких ймовірностей, кодування символів здійснюється тільки на основі тих даних, які вже були оброблені, як наприклад в LZ - методах (названих по імені Абрахама Лемпеля і Якоба Зива). В цьому випадку, друге і подальші входження якоїсь підрядка, вже відомої кодувальнику, замінюються посиланнями на її перше входження.
друга група методів - це статистичні методи стиснення. У свою чергу, ці методи поділяються на адаптивні (або потокові), і блокові.
У першому (адаптивному) варіанті, обчислення ймовірностей для нових даних відбувається за даними, вже оброблених при кодуванні. До цих методів належать адаптивні варіанти алгоритмів Хаффмана і Шеннона-Фано.
У другому (блочному) випадку, статистика кожного блоку даних вираховується окремо, і додається до самого стислому блоку. Сюди можна віднести статичні варіанти методів Хаффмана, Шеннона-Фано, і арифметичного кодування.
третя група методів - це так звані методи перетворення блоку. Вхідні дані розбиваються на блоки, які потім трансформуються цілком. При цьому деякі методи, особливо засновані на перестановці блоків, можуть не приводити до істотного (або взагалі будь-якого) зменшення обсягу даних. Однак після подібної обробки, структура даних значно поліпшується, і подальше стиснення іншими алгоритмами проходить більш успішно і швидко.
Всі методи стиснення даних засновані на простому логічному принципі. Якщо уявити, що найбільш часто зустрічаються елементи закодовані більш короткими кодами, а рідше зустрічаються - довшими, то для зберігання всіх даних буде потрібно менше місця, ніж якби всі елементи представлялися кодами однакової довжини.
Точна взаємозв'язок між частотами появи елементів, і оптимальними довжинами кодів описана в так званої теореми Шеннона про джерелі шифрування (Shannon "s source coding theorem), яка визначає межу максимального стиснення без втрат і ентропію Шеннона.
Якщо ймовірність появи елемента s i дорівнює p (s i), то найбільш вигідно буде представити цей елемент - log 2 p (s i) битами. Якщо при кодуванні вдається домогтися того, що довжина всіх елементів буде приведена до log 2 p (s i) бітам, то і довжина всієї кодируемой послідовності буде мінімальною для всіх можливих методів кодування. При цьому, якщо розподіл ймовірностей всіх елементів F = (p (s i)) незмінно, і ймовірності елементів взаємно незалежні, то середня довжина кодів може бути розрахована як
Це значення називають ентропією розподілу ймовірностей F, або ентропією джерела в заданий момент часу.
Однак зазвичай ймовірність появи елемента не може бути незалежною, навпаки, вона знаходиться в залежності від якихось чинників. В цьому випадку, для кожного нового кодованого елемента s i розподіл ймовірностей F прийме деяке значення F k, тобто для кожного елемента F = F k і H = H k.
Іншими словами, можна сказати, що джерело знаходиться в стані k, якому відповідав би якийсь набір ймовірностей p k (s i) для всіх елементів s i.
Тому, з огляду на цю поправку, можна висловити середню довжину кодів як
Де P k - ймовірність знаходження джерела в стані k.
Отже, на даному етапі ми знаємо, що стиснення засноване на заміні часто зустрічаються елементів короткими кодами, і навпаки, а так само знаємо, як визначити середню довжину кодів. Але що ж таке код, кодування, і як воно відбувається?
Коди без пам'яті є найпростішими кодами, на основі яких може бути здійснено стиснення даних. У коді без пам'яті кожен символ в кодованому векторі даних замінюється кодовим словом з префіксного безлічі двійкових послідовностей або слів.
На мій погляд, не саме зрозуміле визначення. Розглянемо цю тему трохи більш докладно.
Нехай заданий деякий алфавіт ![]() , Що складається з деякого (кінцевого) числа букв. Назвемо кожну кінцеву послідовність символів з цього алфавіту (A = a 1, a 2, ..., a n) словом, А число n - довжиною цього слова.
, Що складається з деякого (кінцевого) числа букв. Назвемо кожну кінцеву послідовність символів з цього алфавіту (A = a 1, a 2, ..., a n) словом, А число n - довжиною цього слова.
Нехай заданий також інший алфавіт ![]() . Аналогічно, позначимо слово в цьому алфавіті як B.
. Аналогічно, позначимо слово в цьому алфавіті як B.
Введемо ще два позначення для безлічі всіх непустих слів в алфавіті. Нехай - кількість непустих слів в першому алфавіті, а - в другому.
Нехай також поставлено відображення F, яке ставить у відповідність кожному слову A з першого алфавіту деякий слово B = F (A) з другого. Тоді слово B буде називатися кодом слова A, а перехід від вихідного слова до його коду буде називатися кодуванням.
Оскільки слово може складатися і з однієї літери, то ми можемо виявити відповідність букв першого алфавіту і відповідних їм слів з другого:
a 1<-> B 1
a 2<-> B 2
…
a n<-> B n
Це відповідність називають схемою, І позначають Σ.
У цьому випадку слова B 1, B 2, ..., B n називають елементарними кодами, А вид кодування з їх допомогою - алфавітним кодуванням. Звичайно, більшість з нас стикалися з таким видом кодування, нехай навіть і не знаючи всього того, що я описав вище.
Отже, ми визначилися з поняттями алфавіт, слово, код, і кодування. Тепер введемо поняття префікс.
Нехай слово B має вигляд B = B "B" ". Тоді B" називають початком, або префіксом слова B, а B "" - його кінцем. Це досить просте визначення, але потрібно відзначити, що для будь-якого слова B, і якесь порожнє слово ʌ ( «пробіл»), і саме слово B, можуть вважатися і началами і кінцями.
Отже, ми підійшли впритул до розуміння визначення кодів без пам'яті. Останнє визначення, яке нам залишилося зрозуміти - це префіксних безліч. Схема Σ має властивість префікса, якщо для будь-яких 1≤i, j≤r, i ≠ j, слово B i не є префіксом слова B j.
Простіше кажучи, префіксних безліч - це таке кінцеве безліч, в якому жоден елемент не є префіксом (або початком) будь-якого іншого елемента. Простим прикладом такого безлічі є, наприклад, звичайний алфавіт.
Отже, ми розібралися з основними визначеннями. Так як же відбувається саме кодування без пам'яті?
Воно відбувається в три етапи.
Одним з канонічних алгоритмів, які ілюструють даний метод, є алгоритм Хаффмана.
Алгоритм Хаффмана використовує частоту появи однакових байт у вхідному блоці даних, і ставить у відповідність часто зустрічається блокам ланцюжка біт меншої довжини, і навпаки. Цей код є мінімально - надлишковим кодом. Розглянемо випадок, коли, не залежно від вхідного потоку, алфавіт вихідного потоку складається з усього 2 символів - нуля і одиниці.
В першу чергу при кодуванні алгоритмом Хаффмана, нам потрібно побудувати схему Σ. Робиться це в такий спосіб:
Кроки 2 і 3 повторюються до тих пір, поки в алфавіті не залишиться тільки 1 псевдосімвол, що містить всі початкові символи алфавіту. При цьому, оскільки на кожному кроці і для кожного символу відбувається зміна відповідного йому слова B i (шляхом додавання одиниці або нуля), то після завершення цієї процедури кожному споконвічного символу алфавіту a i буде відповідати якийсь код B i.
Для кращої ілюстрації, розглянемо невеликий приклад.
Нехай у нас є алфавіт, що складається з усього чотирьох символів - (a 1, a 2, a 3, a 4). Припустимо також, що ймовірності появи цих символів рівні відповідно p 1 = 0.5; p 2 = 0.24; p 3 = 0.15; p 4 = 0.11 (сума всіх ймовірностей, очевидно, дорівнює одиниці).
Отже, побудуємо схему для даного алфавіту.
Якщо зробити ілюстрацію цього процесу, вийде приблизно наступне:
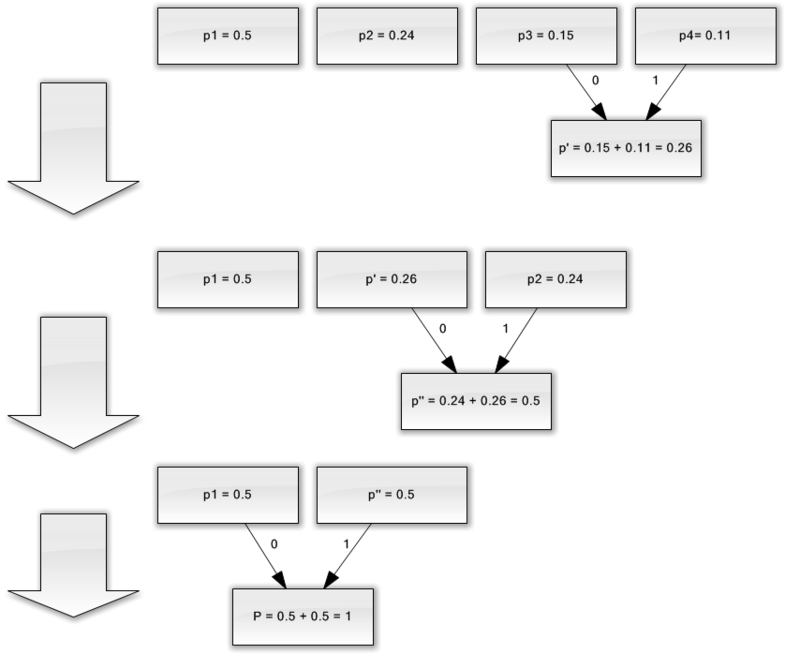
Як ви бачите, при кожному об'єднанні ми присвоюємо об'єднуються символам коди 0 і 1.
Таким чином, коли дерево побудовано, ми можемо легко отримати код для кожного символу. У нашому випадку коди будуть виглядати так:
a 1 = 0
a 2 = 11
a 3 = 100
a 4 = 101
Оскільки жоден з даних кодів не є префіксом якогось іншого (тобто, ми отримали горезвісне префіксних безліч), ми можемо однозначно визначити кожен код у вихідному потоці.
Отже, ми домоглися того, що найчастіший символ кодується найкоротшим кодом, і навпаки.
Якщо припустити, що спочатку для зберігання кожного символу використовувався один байт, то можна порахувати, наскільки нам вдалося зменшити дані.
Нехай на входу у нас був рядок з 1000 символів, в якій символ a 1 зустрічався 500 раз, a 2 - 240, a 3 - 150, і a 4 - 110 разів.
Спочатку даний рядок займала 8000 біт. Після кодування ми отримаємо рядок довжиною в Σp i l i = 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 = 1760 біт. Отже, нам вдалося стиснути дані в 4,54 рази, витративши в середньому 1,76 біта на кодування кожного символу потоку.
Нагадаю, що згідно з Шеннону, середня довжина кодів становить ![]() . Підставивши в це рівняння наші значення ймовірностей, ми отримаємо середню довжину кодів рівну 1.75496602732291, що вельми і вельми близько до отриманого нами результату.
. Підставивши в це рівняння наші значення ймовірностей, ми отримаємо середню довжину кодів рівну 1.75496602732291, що вельми і вельми близько до отриманого нами результату.
Проте, слід враховувати, що крім самих даних нам необхідно зберігати таблицю кодування, що злегка збільшить підсумковий розмір закодованих даних. Очевидно, що в різних випадках можуть з використовуватися різні варіації алгоритму - наприклад, іноді ефективніше використовувати заздалегідь задану таблицю ймовірностей, а іноді - необхідно скласти її динамічно, шляхом проходу по стисливим даними.
Отже, в цій статті я постарався розповісти про загальні принципи, за якими відбувається стиснення без втрат, а також розглянув один з канонічних алгоритмів - кодування по Хаффману.
Якщо стаття припаде до смаку хабросообществу, то я із задоволенням напишу продовження, так як є ще безліч цікавих речей, що стосуються стиснення без втрат; це як класичні алгоритми, так і попередні перетворення даних (наприклад, перетворення Барроуза-Уіліра), ну і, звичайно, специфічні алгоритми для стиснення звуку, відео і зображень (сама, на мій погляд, цікава тема).
У першій частині розглянемо формати аудіо. Що таке FLAC, WavPack, TAK, Monkey "s Audio, OptimFROG, ALAC, WMA, Shorten, LA, TTA, LPAC, MPEG-4 ALS, MPEG-4 SLS, Real Lossless? А ви знаєте скільки на сьогодні зареєстровано типів аудіо- файлів? Розбираємося поки з форматами стиснення аудіо-матеріалів без втрат, а відповідь на питання про кількість аудіо-розширень дивимося в самому кінці статті. Приємного прочитання!
Отже, спочатку визначимося з термінами:
« алгоритм - це точне розпорядження, що визначає обчислювальний процес, що йде від варійованих вихідних даних до шуканого результату ».
« кодек (Англ. Codec, від coder / decoder - шифратор / дешифратор - кодировщик / декодировщик або compressor / decompressor) - пристрій або програма, здатна виконувати перетворення даних або сигналу. Кодеки можуть як кодувати потік / сигнал (часто для передачі, зберігання або шифрування), так і розкодувати - для перегляду або зміни у форматі, більш відповідному для цих операцій. Кодеки часто використовуються при цифровій обробці відео і звуку.
Більшість кодеків для звукових і візуальних даних використовують стиснення з втратами, щоб одержувати прийнятний розмір готового (стисненого) файлу. Існують також кодеки, що стискають без втрат (англ. Lossless codecs) ».
« Стиснення без втрат (Англ. Lossless data compression) - метод стиснення інформації, при використанні якого закодована інформація може бути відновлена з точністю до біта. При цьому оригінальні дані повністю відновлюються з стисненого стану. Для кожного з типів цифрової інформації, як правило, існують свої алгоритми стиснення без втрат ».
Стиснення даних без втрат використовується коли важлива ідентичність стислих даних оригіналу. Типовий приклад - виконувані файли, документи і вихідний код. Програми використовують формати стиснення без втрат називаються архіватори, все знають популярні файлові формати ZIP, або RAR, Unix-утиліту Gzip і т.д. Всі ці програми відрізняються застосованими алгоритмами (одним або декількома) і тому різними властивостями стиснення різних файлів.
Частина I. - ТЕОРІЯ:
Методи стиснення або алгоритми стиснення без втрат можуть бути розподілені по типу даних, для яких вони були створені. Існує три основних типи даних це текст, зображення і звук.
В принципі, будь-який багатоцільовий алгоритм стиснення даних без втрат (багатоцільовий означає, що він може обробляти будь-який тип бінарних даних) може використовуватися для будь-якого типу даних, але більшість з них неефективні для кожного основного типу. Звукові дані, наприклад, не можуть бути добре стиснуті алгоритмом стиснення тексту і навпаки.
Серед методів стиснення можна відзначити наступні - ентропійне стиснення, словникові методи, статистичні методи. Кожен метод хороший для певного виду даних і включає в себе ряд алгоритмів.
Ентропійно стиснення: Алгоритм Хаффмана · Адаптивний алгоритм Хаффмана · Арифметичне кодування (Алгоритм Шеннона - Фано · Інтервальне) · Коди Голомба · Дельта · Універсальний код (Еліаса · Фібоначчі)
Словникові методи: RLE · Deflate · LZ (LZ77 / LZ78 · LZSS · LZW · LZWL · LZO · LZMA · LZX · LZRW · LZJB · LZT)
Статистичні моделі алгоритмів для тексту (або текстових бінарних даних, таких як виконувані файли) включають: Перетворення Барроуза - Уилера (блочно-сортуються пре-обробка, яка робить стиск більш ефективним) · LZ77 і LZ78 (використовується DEFLATE) · LZW.
Інше: RLE · CTW · BWT · MTF · PPM · DMC
Часто, тільки опрацьовані алгоритми отримують назву, тоді як останні розробки тільки мають на увазі (загальне використання, стандартизацію і т. Д.) Або взагалі не вказані.
Але повернемося до нашої теми. Для кодування аудіо даних відповідні алгоритми:
Алгоритм Хаффмана (також використовується DEFLATE), арифметичне кодування
Apple Lossless — ALAC (Apple Lossless Audio Codec)
Audio Lossless Coding — також відомий як MPEG-4 ALS
Free Lossless Audio Codec — FLAC
Meridian Lossless Packing — MLP
Monkey "s Audio — APE
OptimFROG
RealPlayer — RealAudio Lossless
Shorten — SHN
TAK — (T) om "s verlustfreier (A) udio (K) ompressor (нім.)
TTA — True Audio Lossless
WavPack — WavPack lossless
WMA Lossless — Windows Media Lossless
DTS — DTS Surround Sound
Сімейство алгоритмів Лемпеля-Зива, RLE (Run-length encoding - кодування довжин серій)
FLAC (Free Lossless Audio Codec)
Monkey's Audio (APE)
TTA (True Audio)
TTE
LA(LosslessAudio)
RealAudio Lossless
WavPack та ін.
Як ви помітили, більшість кодеків для стиснення без втрат використовує два (іноді і більше) різних типи алгоритму: один генерує статистичну модель для вхідних даних, інший відображає вхідні дані в бітовому поданні, використовуючи модель для отримання «імовірнісних» (тобто часто зустрічаються) даних, які використовуються частіше, ніж «невероятностной». Вигода - зменшення розміру, розплата - більший час процесора потрібний для кодування / декодування.
Коли ми трохи з'ясували теорію перейдемо до наших кодекам для стиснення аудіо даних, яких понаписували безліч: Free Lossless Audio Codec, WavPack, TAK, Monkey "s Audio (.ape, apl), OptimFROG (.ofr), Apple Lossless Audio Codec, WMA, Shorten (.SHN), LosslessAudio, True Audio, Lossless Predictive Audio Coder (.LPAC), MPEG-4 ALS, MPEG-4 SLS (.mp4), Real Lossless або RealAudio Lossless, Windows Media Audio Lossless, DTS .. . і це ще далеко не все. Багато фірм випускають професійне звукозаписне обладнання винаходили і продовжують винаходити свої формати.
Таке безліч форматів стиснення аудіо даних викликано технічною недосконалістю платформ (більшість з перерахованих кодеків були написані в кінці 90-х років), маркетингом (у випадку з ALAC), і широким інтересом математико-університетської аудиторії до алгоритмів стиснення даних.
Крім зазначених вище існує (існувало) безліч забутих заслужено чи незаслужено аудіо-архіваторів і аудіо-кодеків. Технічні характеристики деяких можна подивитися в таблиці:
клікабельно:
Ми ж розглянемо докладніше тільки ті які увійшли в повсюдне користування і які на момент написання статті можна знайти на просторах Інтернету. Їх всього дюжина.
Частина II. - ПРАКТИКА:
Зліва на право: 1. блакитна зона SSDS (Sony Dynamic Digital Sound), 2. сіра зона Dolby Digital (між перфорацією), 3. Analog Audio (як на платівці), і 4. тимчасової код DTS (синій).
А ось і свіже за 2009 рік порівняння дев'яти з перерахованих вище:
Частина III. - ТЕСТУВАННЯ:
Порівняння проводилося на платформі:
CPU: DualCore Intel Core i3 530, 2933 MHz (x86, x86-64, MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2)
Motherboard. плата: Asus P7H55-V
RAM: 2x2Gb DDR3-1333
HDD: Seagate SATA 160GB 8 MB cache (System), Hitachi SATA-II 500GB 16 MB cache (Source), Hitachi SATA-II 1000GB 32 MB cache (Destination)
1. Lossless Audio (LA) - цей вельми старий кодек (2004) став безумовним переможцем зі стиснення. При цьому треба відзначити цілком прийнятну (в порівнянні з тим же OptimFROG або WavPack) швидкість кодування, а також достатню швидкість декодування. Хоч файл LA і не береться стверджувати за допомогою плагіна foo_benchmark, програвався він прекрасно, без запинок і затримок при прокручуванні.
Залишається тільки дивуватися, чому автор закинув такий прекрасний кодек, навіть не відкривши при цьому вихідний код.
2. OptimFROG - не надто відстає від LA. Але за швидкістю його навряд чи можна назвати швидким. Крім того, неприємним моментом є висока затримка при прокручуванні файлу - часом це сильно напружує.
3. Monkey "s Audio - популярний, але ресурсномісткий кодек. Дає дійсно високий стиск, але знову ж таки має проблеми з прокруткою. (Автор тесту схоже затиснув файл з опцією "Insane", що ще може призвести до втрати даних).
4. TAK - цей активно розробляється кодек не перестає радувати. Якщо брати до уваги всі три параметри (стиснення, кодування, декодування), TAK виглядає найбільш привабливо. Висока швидкість роботи пояснюється активним використанням процесорних оптимізацій (в т.ч. SSSE3). А використання двох ядер дає майже дворазовий приріст швидкості кодування! Таким чином, у випадку з TAK перевага від використання сучасних процесорів найбільш відчутно.
5. WavPack - чесно кажучи, я не знаю, за рахунок чого цей кодек набув популярності. Кодування із середнім ступенем стиснення дає результати порівнянні з FLAC, а використання режимів високого стиснення призводить до невиправданого зниження швидкості. Хоча, головним плюсом цього кодека є його широка підтримка і функціональність (в т.ч. підтримка багатоканального аудіо, гібридного режиму), але нагадаю, що цей бік питання ми в даному тесті не розглядаємо.
6. True Audio (TTA) - тут треба відзначити хіба що дуже високу швидкість кодування і прийнятну ступінь стиснення (трохи вище ніж у FLAC). При цьому швидкість декодування не можна назвати дуже високою.
7. FLAC- ступінь стиснення середня, але ось швидкість декодування порадувала. Правда, головною причиною лідерства цього кодека серед громадськості є відкритий вихідний код, і, як наслідок, найширша апаратна / софтовая підтримка.
8. Apple Lossless (ALAC) - один з тих кодеків, які нічим не примітні, але продовжують активно насаджуватися розробниками (в даному випадку Apple). Низька ступінь стиснення і швидкість декодування. Швидкість стиснення - середня. Підійде хіба що користувачам iPod - у них просто немає вибору.
9. WMA Lossless - випадок аналогічний ALAC, але тут ми маємо справу зі корпорацією-гігантом Microsoft. Ще менший ступінь стиснення, середня швидкість стиснення. Швидкість декодування відносно висока. Важко уявити випадок, в якому виникла б необхідність використовувати саме цей lossless-кодек.
Частина IV. - ЗАГАЛЬНІ ВИСНОВКИ:
Вибір простий і складається з двох пунктів:
Якщо важливо місце на диску то використовуємо Monkey "s Audio (АРЄ тисне краще FLACа на 8-12%, що на диску ємністю 1ТБайт складе близько 100ГБайт або близько 300 стандартних CD альбомів). Те ж саме стосується роздач в Інтернеті. Я зберігаю свою колекцію саме в Monkey "s Audio форматі з опцією стиснення Extra High. Різними LA та іншими я не користуюся, бо виграш від їх використання в порівнянні з Monkey "s Audio малий.
Якщо важлива сумісність з різними плеєрами і медіа-залізяками які працюють під Линух і не тільки використовуємо FLAC. Хоча ІМХО для плеєрів цілком піде собі і МР3, адже головне не звук, а МУЗИКА!
Надалі будемо дивитися на розвиток ТТА, але моя суб'єктивна думка, ТТА вже запізнився на паровоз в "безлузного дали".
Для "маководов" і "Ай-фонцев" - вибір на скільки я знаю поки один - бубон і танці навколо різних перекодировщик в формат ALAC.
І запам'ятайте, ви завжди можете перевести файли з одного кодека в інший, причому без втрати якості, цим-то і хороші кодеки стиснення без втрат на відміну від кодеків "стиснення з втратами".
Відступ "ліричний" номер РАЗ.
Для "удіфілов". Різниці в звучанні форматів - НІ! "Чи не природне забарвлення високих", "легка нерозбірливість панча", аки "завуалированность середини з розмазуванням сцени" - це у вас в СИСТЕМІ. Кодеки не грають вони декодують, нічого не вносять і нічого не видаляють.
Відступ "ліричний" номер ДВА.
Ця стаття написана для меломанів і колекціонерів музики - новачків і середнячків, таким же меломаном і колекціонером.
Гурам, Квод, сенсея, і іншим Великим Кормчим від Миру Аудіо, а так само Войовничим Удіфілам тут буде не цікаво. Пишіть свою статтю "з блекджек і кодеками".
Цікава інформація:
В даний час зареєстровано 1154 розширень файлів так чи інакше пов'язаних з аудіо даними!
джерела:
wiki.hydrogenaudio.org/
ru.wikipedia.org/
а так само офіційні сайти програм.
Ще вчора здавалося, що диск розміром в один гігабайт - це так багато, що навіть неясно, чим його заповнити, і вже звичайно, кожен про себе думав: був би у мене гігабайт пам'яті, я б перестав «скупитися» і стискати свою інформацію якими -то архиваторами. Але, мабуть, світ так влаштований, що «святе місце порожнім не буває», і як тільки у нас з'являється зайвий гігабайт - тут же знаходиться ніж його заповнити. Та й самі програми, як відомо, стають все більш об'ємними. Так що, мабуть, з терабайтами і екзабайтами буде те ж саме.
Тому, як би не росли обсяги пам'яті диска, упаковувати інформацію, схоже, не перестануть. Навпаки, у міру того як «місця в комп'ютері» стає все більше, число нових архіваторів збільшується, при цьому їх розробники не просто змагаються в зручності інтерфейсів, а в першу чергу прагнуть упакувати інформацію все щільніше і щільніше.
Однак очевидно, що процес цей не нескінченний. Де лежить цю межу, які архіватори доступні сьогодні, за якими параметрами вони конкурують між собою, де знайти свіжий архіватор - ось далеко не повний перелік питань, які висвітлюються в даній статті. Крім розгляду теоретичних питань ми зробили підбірку архиваторов, які можна завантажити з нашого диска, щоб самим переконатися в ефективності тієї чи іншої програми і вибрати з них оптимальну - в залежності від специфіки розв'язуваних вами завдань.
Дозволю собі почати цю вельми серйозну тему зі старою жарти. Розмовляють два пенсіонера:
Ви не могли б сказати мені номер вашого телефону? - каже один.
Ви знаєте, - зізнається другий, - я, на жаль, точно його не пам'ятаю.
Яка жалість, - журиться перший, - ну скажіть хоча б приблизно ...
Дійсно, відповідь вражає своєю безглуздістю. Цілком очевидно, що в семизначну наборі цифр досить помилитися в одному символі, щоб інша інформація стала абсолютно марною. Однак уявімо собі, що той же самий телефон написаний словами російської мови і, скажімо, при передачі цього тексту частина букв втрачена - що станеться в подібному випадку? Для наочності розглянемо собі конкретний приклад: телефонний номер 233 34 44.
Відповідно запис «Двсті трцать три тріцть Четрі Сорк чтре», в якій є не один, а кілька пропущених символів, як і раніше легко читається. Це пов'язано з тим, що наша мова має певну надмірність, яка, з одного боку, збільшує довжину записи, а з іншого - підвищує надійність її передачі. Пояснюється це тим, що ймовірність появи кожного наступного символу в цифровому записі телефону однакова, в той час як в тексті, записаному словами російської мови, це не так. Очевидно, наприклад, що твердий знак в російській мові з'являється значно рідше, ніж, наприклад, буква «а». Більш того, деякі поєднання букв більш вірогідні, ніж інші, а такі, як два твердих знака поспіль, неможливі в принципі, і так далі. Знаючи, наскільки ймовірним є появи будь-якої літери в тексті, і порівнявши її з максимальною, можна встановити, наскільки економічний даний спосіб кодування (в нашому випадку - російська мова).
Ще одна очевидна зауваження можна зробити, повернувшись до прикладу з телефоном. Для того щоб запам'ятати номер, ми часто шукаємо закономірності в наборі цифр, що, в принципі, також є спробою стиснення даних. Цілком логічно запам'ятати вищезгаданий телефон як «два, три трійки, три четвірки».
Теорія інформації свідчить, що інформації в повідомленні тим більше, чим більше його ентропія. Для будь-якої системи кодування можна оцінити її максимальну інформаційну ємність (Hmax) і дійсну ентропію (Н). Тоді випадок Н
R = (Hmax - H) / Hmax
Вимірювання надмірності природних мов (тих, на яких ми говоримо) дає приголомшливі результати: виявляється, надмірність цих мов складає близько 80%, а це свідчить про те, що практично 80% переданої за допомогою мови інформації є надлишковою, тобто зайвою. Цікавий і той факт, що показники надмірності різних мов дуже близькі. Дана цифра приблизно визначає теоретичні межі стиснення текстових файлів.
Говорячи про коди стиснення, розрізняють поняття «стиснення без втрат» і «стиснення з втратами». Очевидно, що коли ми маємо справу з інформацією типу «номер телефону», то стиснення такого запису за рахунок втрати частини символів не веде ні до чого хорошого. Проте можна уявити цілий ряд ситуацій, коли втрата частини інформації не призводить до втрати корисності залишилася. Стиснення з втратами застосовується в основному для графіки (JPEG), звуку (MP3), відео (MPEG), тобто там, де в силу величезних розмірів файлів ступінь стиснення дуже важлива, і можна пожертвувати деталями, неістотними для сприйняття цієї інформації людиною. Особливі можливості для стиснення інформації є при компресії відео. У ряді випадків більша частина зображення передається з кадру в кадр без змін, що дозволяє будувати алгоритми стиснення на основі вибіркового відстеження тільки частини «картинки». В окремому випадку зображення людини, що говорить, що не змінює свого положення, може оновлюватися тільки в області особи або навіть тільки рота - тобто в тій частині, де відбуваються найбільш швидкі зміни від кадру до кадру.
В цілому ряді випадків стиснення графіки з втратами, забезпечуючи дуже високі ступеня компресії, практично непомітно для людини. Так, з трьох фотографій, показаних нижче, перша представлена в TIFF-форматі (формат без втрат), друга збережена в форматі JPEG c мінімальним параметром стиснення, а третя з максимальним. При цьому можна бачити, що останнє зображення займає майже на два порядки менший обсяг, ніж первая.Однако методи стиснення з втратами мають і низку недоліків.
Перший полягає в тому, що компресія з втратами застосовна не для всіх випадків аналізу графічної інформації. Наприклад, якщо в результаті стиснення зображення на обличчі зміниться форма родимки (але обличчя при цьому залишиться повністю впізнається), то ця фотографія виявиться цілком прийнятною, щоб послати її поштою знайомим, однак якщо пересилається фотознімок легких на медекспертизу для аналізу форми затемнення - це вже зовсім інша справа. Крім того, в разі машинних методів аналізу графічної інформації результати кодування з втратою (непомітні для очей) можуть бути «помітні» для машинного аналізатора.
Друга причина полягає в тому, що повторна компресія і декомпресія з втратами призводять до ефекту накопичення похибок. Якщо говорити про ступінь застосовності формату JPEG, то, очевидно, він корисний там, де важливим є великий коефіцієнт стиснення при збереженні вихідної колірної глибини. Саме це властивість зумовило широке застосування даного формату в поданні графічної інформації в Інтернеті, де швидкість відображення файлу (його розмір) має першорядне значення. Негативна властивість формату JPEG - погіршення якості зображення, що робить практично неможливим його застосування в поліграфії, де цей параметр є визначальним.
Тепер перейдемо до розмови про стиснення інформації без втрат і розглянемо, які алгоритми і програми дозволяють здійснювати цю операцію.
Стиснення, або кодування, без втрат може застосовуватися для стиснення будь-якої інформації, оскільки забезпечує абсолютно точне відновлення даних після кодування і декодування. Стиснення без втрат засноване на простому принципі перетворення даних з однієї групи символів в іншу, більш компактну.
Найбільш відомі два алгоритму стиснення без втрат: це кодування Хаффмена (Huffman) і LZW-кодування (за початковими літерами імен творців Lempel, Ziv, Welch), які представляють основні підходи при стисненні інформації. Кодування Хаффмена з'явилося на початку 50-х; принцип його полягає в зменшенні кількості бітів, використовуваних для подання часто зустрічаються символів і відповідно в збільшенні кількості бітів, використовуваних для рідко зустрічаються символів. Метод LZW кодує рядки символів, аналізуючи вхідний потік для побудови розширеного алфавіту, заснованого на рядках, які він обробляє. Обидва підходи забезпечують зменшення надлишкової інформації у вхідних даних.
Кодування Хаффмена - один з найбільш відомих методів стиснення даних, який заснований на передумові, що в надлишкової інформації деякі символи використовуються частіше, ніж інші. Як уже згадувалося вище, в російській мові деякі букви зустрічаються з більшою ймовірністю, ніж інші, однак в ASCII-кодах ми використовуємо для представлення символів однакову кількість бітів. Логічно припустити, що якщо ми будемо використовувати меншу кількість бітів для часто зустрічаються символів і більше для рідко зустрічаються, то ми зможемо скоротити надмірність повідомлення. Кодування Хаффмена якраз і грунтується на зв'язку довжини коду символу з ймовірністю його появи в тексті.
У тому випадку, коли ймовірності символів вхідних даних невідомі, використовується динамічне кодування, при якому дані про ймовірність появи тих чи інших символів уточнюються «на льоту» під час читання вхідних даних.
Алгоритм LZW, запропонований порівняно недавно (в 1984 році), запатентований і належить фірмі Sperry.
LZW-алгоритм заснований на ідеї розширення алфавіту, що дозволяє використовувати додаткові символи для подання рядків звичайних символів. Використовуючи, наприклад, замість 8-бітових ASCII-кодів 9-бітові, ви отримуєте додаткові 256 символів. Робота компресора зводиться до побудови таблиці, що складається з рядків і відповідних їм кодів. Алгоритм стиснення зводиться до наступного: програма прочитує черговий символ і додає його до рядка. Якщо рядок вже знаходиться в таблиці, читання триває, якщо немає, даний рядок додається до таблиці рядків. Чим більше буде повторюваних рядків, тим сильніше будуть стиснуті дані. Повертаючись до прикладу з телефоном, можна, провівши досить спрощену аналогію, сказати, що, стискаючи запис 233 34 44 по LZW-методу, ми прийдемо до введення нових рядків - 333 і 444 і, висловлюючи їх додатковими символами, зможемо зменшити довжину запису.
Напевно, читачеві буде цікаво дізнатися, який же архіватор краще. Відповідь на це питання далеко не однозначний.
Якщо подивитися на таблицю, в якій «змагаються» архіватори (а зробити це можна як на відповідному сайті в Інтернеті, так і на нашому CD-ROM), то можна побачити, що кількість програм, які беруть участь в «змаганнях», перевищує сотню. Як же вибрати з цього різноманіття необхідний архіватор?
Цілком можливо, що для багатьох користувачів не останнім є питання способу поширення програми. Більшість архиваторов поширюються як ShareWare, і деякі програми обмежують кількість функцій для незареєстрованих версій. Є програми, які поширюються як FreeWare.
Якщо вас не хвилюють меркантильні міркування, то перш за все необхідно усвідомити, що є цілий ряд архиваторов, які оптимізовані на рішення конкретних завдань. У зв'язку з цим існують різні види спеціалізованих тестів, наприклад на стиск тільки текстових файлів або тільки графічних. Так, зокрема, Wave Zip в першу чергу вміє стискати WAV-файли, а мультимедійний архіватор ERI краще всіх упаковує TIFF-файли. Тому якщо вас цікавить стиснення якогось певного типу файлів, то можна підшукати програму, яка спочатку призначена спеціально для цього.
Існує тип архіваторів (так звані Exepackers), які служать для стиснення виконуваних модулів COM, EXE або DLL. Файл упаковується таким чином, що при запуску він сам себе розпаковує в пам'яті «на льоту» і далі працює в звичайному режимі.
Одними з кращих в даній категорії можна назвати програми ASPACK і Petite. Більш детальну інформацію про програми даного класу, а також відповідні рейтинги можна знайти за адресою.
Якщо ж вам потрібен архіватор, так би мовити, «на всі випадки життя», то оцінити, наскільки хороша конкретна програма, можна звернувшись до тесту, в якому «змагаються» програми, що обробляють різні типи файлів. Переглянути список архіваторів, що беруть участь в даному тесті, можна на нашому CD-ROM.
При цьому необхідно відзначити, що в тестах аналізуються лише кількісні параметри, такі як швидкість стиснення, коефіцієнт стиснення і деякі інші, проте існує ще цілий ряд параметрів, які визначають зручність користування архиваторами. Перерахуємо деякі з них.
Створення solid-архівів - це архівування, при якому збільшення стиснення зростає при наявності великого числа одночасно оброблюваних коротких файлів. Частина архиваторов, наприклад ACB, завжди створюють solid-архіви, інші, такі як RAR або 777, надають можливість їх створення, а деякі, наприклад ARJ, цього робити взагалі не вміють.
Я аж ніяк не прихильник консервативної позиції «раз все працює, то головне - нічого не змінювати», я лише підкреслюю, що перехід на нову програму повинен бути обгрунтованим.
КомпьютерПресс 5 «2000
Доброго вам дня.
Сьогодні я хочу торкнутися теми стиснення даних без втрат. Незважаючи на те, що на Хабре вже були статті, присвячені деяким алгоритмам, мені захотілося розповісти про це трохи детальніше.
Я постараюся давати як математичний опис, так і опис в звичайному вигляді, для того, щоб кожен міг знайти для себе щось цікаве.
У цій статті я торкнуся фундаментальних моментів стиснення і основних типів алгоритмів.
Зрозуміло, так. Звичайно, всі ми розуміємо, що зараз нам доступні і носії інформації великого обсягу, і високошвидкісні канали передачі даних. Однак, одночасно з цим зростають і обсяги переданої інформації. Якщо кілька років тому ми дивилися 700-мегабайтні фільми, що уміщаються на одну болванку, то сьогодні фільми в HD-якості можуть займати десятки гігабайт.
Звичайно, користі від стиснення всього і вся не так багато. Але все ж існують ситуації, в яких стиснення вкрай корисно, якщо не потрібно.
Звичайно, можна придумати ще безліч різних ситуацій, в яких стиснення виявиться корисним, але нам досить і цих кількох прикладів.
Всі методи стиснення можна розділити на дві великі групи: стиснення з втратами і стиснення без втрат. Стиснення без втрат застосовується в тих випадках, коли інформацію потрібно відновити з точністю до біта. Такий підхід є єдино можливим при стисненні, наприклад, текстових даних.
У деяких випадках, однак, не потрібно точного відновлення інформації та допускається використовувати алгоритми, що реалізують стиснення з втратами, яке, на відміну від стиснення без втрат, зазвичай простіше реалізується і забезпечує більш високу ступінь архівації.
Отже, перейдемо до розгляду алгоритмів стиснення без втрат.
друга група методів - це статистичні методи стиснення. У свою чергу, ці методи поділяються на адаптивні (або потокові), і блокові.
У першому (адаптивному) варіанті, обчислення ймовірностей для нових даних відбувається за даними, вже оброблених при кодуванні. До цих методів належать адаптивні варіанти алгоритмів Хаффмана і Шеннона-Фано.
У другому (блочному) випадку, статистика кожного блоку даних вираховується окремо, і додається до самого стислому блоку. Сюди можна віднести статичні варіанти методів Хаффмана, Шеннона-Фано, і арифметичного кодування.
третя група методів - це так звані методи перетворення блоку. Вхідні дані розбиваються на блоки, які потім трансформуються цілком. При цьому деякі методи, особливо засновані на перестановці блоків, можуть не приводити до істотного (або взагалі будь-якого) зменшення обсягу даних. Однак після подібної обробки, структура даних значно поліпшується, і подальше стиснення іншими алгоритмами проходить більш успішно і швидко.
Всі методи стиснення даних засновані на простому логічному принципі. Якщо уявити, що найбільш часто зустрічаються елементи закодовані більш короткими кодами, а рідше зустрічаються - довшими, то для зберігання всіх даних буде потрібно менше місця, ніж якби всі елементи представлялися кодами однакової довжини.
Точна взаємозв'язок між частотами появи елементів, і оптимальними довжинами кодів описана в так званої теореми Шеннона про джерелі шифрування (Shannon "s source coding theorem), яка визначає межу максимального стиснення без втрат і ентропію Шеннона.
Це значення називають ентропією розподілу ймовірностей F, або ентропією джерела в заданий момент часу.
Однак зазвичай ймовірність появи елемента не може бути незалежною, навпаки, вона знаходиться в залежності від якихось чинників. В цьому випадку, для кожного нового кодованого елемента s i розподіл ймовірностей F прийме деяке значення F k, тобто для кожного елемента F = F k і H = H k.
Іншими словами, можна сказати, що джерело знаходиться в стані k, якому відповідав би якийсь набір ймовірностей p k (s i) для всіх елементів s i.
Тому, з огляду на цю поправку, можна висловити середню довжину кодів як
Де P k - ймовірність знаходження джерела в стані k.
Отже, на даному етапі ми знаємо, що стиснення засноване на заміні часто зустрічаються елементів короткими кодами, і навпаки, а так само знаємо, як визначити середню довжину кодів. Але що ж таке код, кодування, і як воно відбувається?
Нехай заданий деякий алфавіт ![]() , Що складається з деякого (кінцевого) числа букв. Назвемо кожну кінцеву послідовність символів з цього алфавіту (A = a 1, a 2, ..., a n) словом, А число n - довжиною цього слова.
, Що складається з деякого (кінцевого) числа букв. Назвемо кожну кінцеву послідовність символів з цього алфавіту (A = a 1, a 2, ..., a n) словом, А число n - довжиною цього слова.
Нехай заданий також інший алфавіт ![]() . Аналогічно, позначимо слово в цьому алфавіті як B.
. Аналогічно, позначимо слово в цьому алфавіті як B.
Введемо ще два позначення для безлічі всіх непустих слів в алфавіті. Нехай - кількість непустих слів в першому алфавіті, а - в другому.
Нехай також поставлено відображення F, яке ставить у відповідність кожному слову A з першого алфавіту деякий слово B = F (A) з другого. Тоді слово B буде називатися кодом слова A, а перехід від вихідного слова до його коду буде називатися кодуванням.
Оскільки слово може складатися і з однієї літери, то ми можемо виявити відповідність букв першого алфавіту і відповідних їм слів з другого:
a 1<-> B 1
a 2<-> B 2
…
a n<-> B n
Це відповідність називають схемою, І позначають Σ.
У цьому випадку слова B 1, B 2, ..., B n називають елементарними кодами, А вид кодування з їх допомогою - алфавітним кодуванням. Звичайно, більшість з нас стикалися з таким видом кодування, нехай навіть і не знаючи всього того, що я описав вище.
Отже, ми визначилися з поняттями алфавіт, слово, код, і кодування. Тепер введемо поняття префікс.
Нехай слово B має вигляд B = B "B" ". Тоді B" називають початком, або префіксом слова B, а B "" - його кінцем. Це досить просте визначення, але потрібно відзначити, що для будь-якого слова B, і якесь порожнє слово ʌ ( «пробіл»), і саме слово B, можуть вважатися і началами і кінцями.
Отже, ми підійшли впритул до розуміння визначення кодів без пам'яті. Останнє визначення, яке нам залишилося зрозуміти - це префіксних безліч. Схема Σ має властивість префікса, якщо для будь-яких 1≤i, j≤r, i ≠ j, слово B i не є префіксом слова B j.
Простіше кажучи, префіксних безліч - це таке кінцеве безліч, в якому жоден елемент не є префіксом (або початком) будь-якого іншого елемента. Простим прикладом такого безлічі є, наприклад, звичайний алфавіт.
Отже, ми розібралися з основними визначеннями. Так як же відбувається саме кодування без пам'яті?
Воно відбувається в три етапи.
Одним з канонічних алгоритмів, які ілюструють даний метод, є алгоритм Хаффмана.
В першу чергу при кодуванні алгоритмом Хаффмана, нам потрібно побудувати схему Σ. Робиться це в такий спосіб:
Для кращої ілюстрації, розглянемо невеликий приклад.
Нехай у нас є алфавіт, що складається з усього чотирьох символів - (a 1, a 2, a 3, a 4). Припустимо також, що ймовірності появи цих символів рівні відповідно p 1 = 0.5; p 2 = 0.24; p 3 = 0.15; p 4 = 0.11 (сума всіх ймовірностей, очевидно, дорівнює одиниці).
Отже, побудуємо схему для даного алфавіту.
Якщо зробити ілюстрацію цього процесу, вийде приблизно наступне:
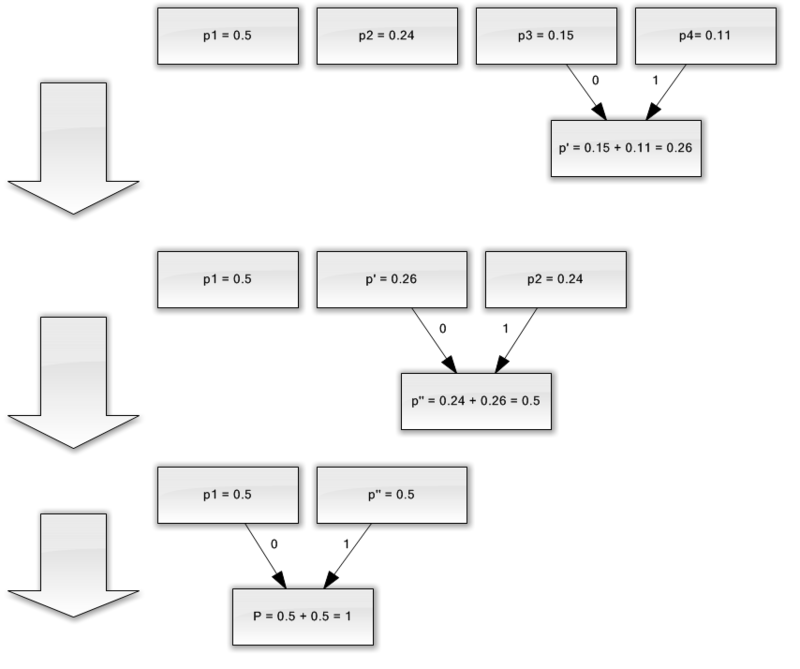
Як ви бачите, при кожному об'єднанні ми присвоюємо об'єднуються символам коди 0 і 1.
Таким чином, коли дерево побудовано, ми можемо легко отримати код для кожного символу. У нашому випадку коди будуть виглядати так:
A 1 = 0
a 2 = 11
a 3 = 100
a 4 = 101
Оскільки жоден з даних кодів не є префіксом якогось іншого (тобто, ми отримали горезвісне префіксних безліч), ми можемо однозначно визначити кожен код у вихідному потоці.
Отже, ми домоглися того, що найчастіший символ кодується найкоротшим кодом, і навпаки.
Якщо припустити, що спочатку для зберігання кожного символу використовувався один байт, то можна порахувати, наскільки нам вдалося зменшити дані.
Нехай на входу у нас був рядок з 1000 символів, в якій символ a 1 зустрічався 500 раз, a 2 - 240, a 3 - 150, і a 4 - 110 разів.
Спочатку даний рядок займала 8000 біт. Після кодування ми отримаємо рядок довжиною в Σp i l i = 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 = 1760 біт. Отже, нам вдалося стиснути дані в 4,54 рази, витративши в середньому 1,76 біта на кодування кожного символу потоку.
Нагадаю, що згідно з Шеннону, середня довжина кодів становить. Підставивши в це рівняння наші значення ймовірностей, ми отримаємо середню довжину кодів рівну 1.75496602732291, що вельми і вельми близько до отриманого нами результату.
Проте, слід враховувати, що крім самих даних нам необхідно зберігати таблицю кодування, що злегка збільшить підсумковий розмір закодованих даних. Очевидно, що в різних випадках можуть з використовуватися різні варіації алгоритму - наприклад, іноді ефективніше використовувати заздалегідь задану таблицю ймовірностей, а іноді - необхідно скласти її динамічно, шляхом проходу по стисливим даними.
| Статті по темі: | |
|
Лікування тремору рук. Чому трясеться рука? Причини, лікування
Знизити прояви такого захворювання добре допомагає дихальна ... Світлий кал - типовий симптом вірусного гепатиту
Медикаментозний (лікарський) гепатит характеризується запаленням ... Безнікотинові сигарети: відгуки, інструкція, фото
Що таке безнікотинові сигарети? Незважаючи на активну досі ... | |