
вибір читачів





Популярні статті
при введенні текстової інформації в комп'ютер символи (літери, цифри, знаки) кодуються за допомогою різних кодових систем, які складаються з набору кодових таблиць, розміщених на відповідних сторінках стандартів для кодування текстової інформації. У таких таблицях кожному символу присвоюється певний числовий код в шістнадцятковій або десятковій системі числення, т. Е. Кодові таблиці відображають відповідність між зображеннями символів і числовими кодами і призначені для кодування і декодування текстової інформації. При введенні текстової інформації за допомогою клавіатури комп'ютера кожен символ, що вводиться піддається кодування, т. Е. Перетворюється в числовий код, при виведенні текстової інформації на пристрій виведення комп'ютера (дисплей, принтер або плоттер) по числовому коду символу будується його зображення. Присвоєння символу певного числового коду є результатом угоди між відповідними організаціями різних країн. В даний час немає єдиної універсальної кодової таблиці, що задовольняє буквах національних алфавітів різних країн.
Сучасні кодові таблиці включають в себе міжнародну і національну частини, т. Е. Містять букви латинського та національного алфавітів, цифри, знаки арифметичних операцій і пунктуації, математичні і керуючі символи, символи псевдографіки. Міжнародна частина кодової таблиці, що базується на стандарті ASCII (American Standard Code for Information Interchange),кодує першу половину символів кодової таблиці з числовими кодами від 0 до 7 F 16,або в десятковій системі числення від 0 до 127. При цьому коди від 0 до 20 16 (0? 32 10) відведені функціональних клавіш (F1, F2, F3 і т. д.) клавіатури персонального комп'ютера. На рис. 3.1 приведена міжнародна частина кодових таблиць, заснована на стандарті ASCII.Осередки таблиць пронумеровані відповідно до десяткової і шістнадцятковій системі числення.
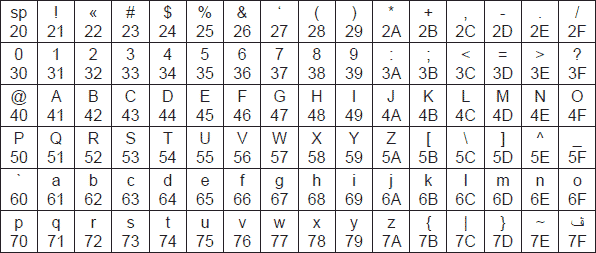
Рис 3.1. Міжнародна частина кодової таблиці (стандарт ASCII)з номерами осередків, представлених в десяткового (а) і шістнадцятковій (б) системі числення
Національна частина кодових таблиць містить коди національних алфавітів, яку називають також таблицею наборів символів (Charset).
В даний час для підтримки букв російського алфавіту (кирилиці) існує кілька кодових таблиць (кодувань), які використовуються різними операційними системами, що є істотним недоліком і в ряді випадків призводить до проблем, пов'язаних з операціями декодування числових значень символів. У табл. 3.1 наведені назви кодових сторінок (стандартів), на яких розміщені кодові таблиці (кодування) кирилиці.
Таблиця 3.1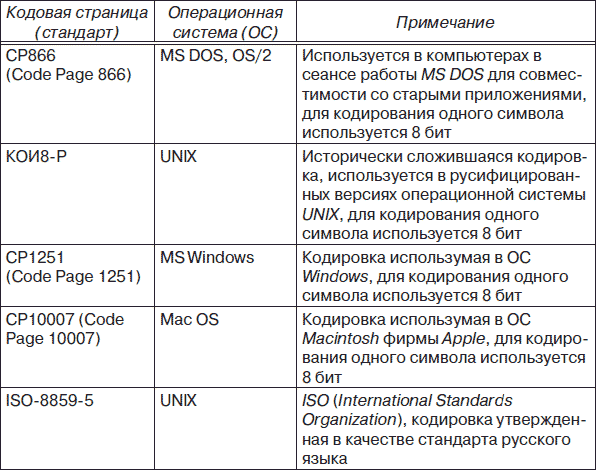
Одним з перших стандартів кодування кирилиці на комп'ютерах був стандарт КОІ8-Р. Національна частина кодової таблиці цього стандарту наведена на рис. 3.2.

Мал. 3.2. Національна частина кодової таблиці стандарту КОІ8-Р
В даний час застосовується і кодова таблиця, Розміщена на сторінці ср866 стандарту кодування текстової інформації, яка використовується в операційній системі MS DOSабо сеансі роботи MS DOSдля кодування кирилиці (рис. 3.3, а).


Мал. 3.3. Національна частина кодової таблиці, розміщена на сторінці ср866 (а) і на сторінці СР1251 (б) стандарту кодування текстової інформації
В даний час для кодування кирилиці найбільшого поширення набула кодова таблиця, розміщена на сторінці СР1251 відповідного стандарту, яка використовується в операційних системах сімейства Windowsфірми Microsoft(Рис. 3.2, б).У всіх представлених кодових таблицях, крім таблиці стандарту Unicode,для кодування одного символу відводиться 8 двійкових розрядів (8 біт).
В кінці минулого століття з'явився новий міжнародний стандарт Unicode,в якому один символ представляється двобайтовим двійковим кодом. Застосування цього стандарту - продовження розробки універсального міжнародного стандарту, що дозволяє вирішити проблему сумісності національних кодувань символів. За допомогою даного стандарту можна закодувати 2 16 = 65536 різних символів. На рис. 3.4 приведена кодова таблиця 0400 (російський алфавіт) стандарту Unicode.
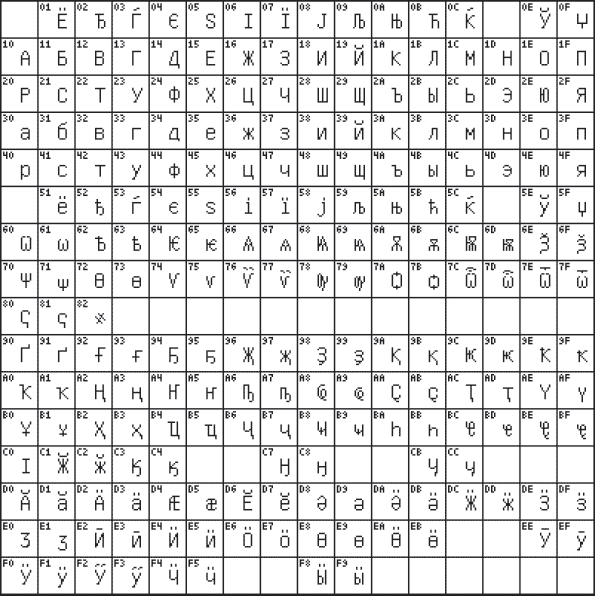
Мал. 3.4. Кодова таблиця 0400 стандарту Unicode
Пояснимо сказане, що стосується кодування текстової інформації, на прикладі.
приклад 3.1Закодувати слово «Комп'ютер» у вигляді послідовності десяткових і шістнадцяткових чисел, використовуючи кодування СР1251. Які символи будуть відображені в кодових таблицях ср866 і КОІ8-Р при використанні отриманого коду.
Послідовності шістнадцятирічного і двійкового коду слова «Комп'ютер» на основі кодувальної таблиці СР1251 (див. Рис. 3.3, б)будуть виглядати наступним чином:
Дана кодова послідовність в кодуваннях ср866 і КОІ8-Р призведе до відображення наступних символів:
Для перетворення російськомовних текстових документів з одного стандарту кодування текстової інформації в інший використовуються спеціальні програми - конвертори. Конвертори зазвичай вбудовуються в інші програми. Прикладом може служити програма браузер - Internet Explorer (IE),яка має вбудований конвертор. Програма браузер - це спеціальна програма для перегляду вмісту Web-сторінокв глобальній комп'ютерній мережі Інтернет. Скористаємося цією програмою для підтвердження отриманого в прикладі 3.1 результату відображення символів. Для цього слід виконати такі дії.
1. Запустимо програму Блокнот (NotePad).Програма Блокнот в операційній системі Windows ХРзапускається за допомогою команди: [Кнопка Пуск - Програми - Стандартні - Блокнот]. У вікні програми Блокнот надрукуємо слово «Комп'ютер» з використанням синтаксису мови розмітки гіпертекстових документів - HTML (Hyper Text Markup Language).Ця мова використовується для створення документів в Інтернеті. Текст повинен виглядати наступним чином:
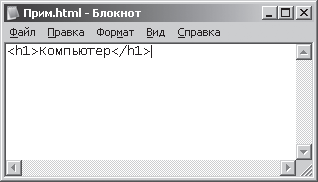
Мал. 3.5. Відображення тексту в вікні Блокнот
Збережемо цей текст, виконавши команду: [Файл - Зберегти як ...] у відповідній папці комп'ютера, при збереженні тексту файлу дамо ім'я - Прим, з розширенням файлу. html.
2. Запустимо програму Internet Explorer,виконавши команду: [Кнопка Пуск - Програми - Internet Explorer].При запуску програми з'явиться вікно, представлене на рис. 3.6
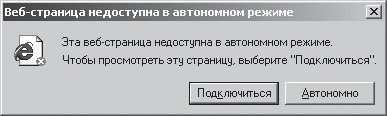
Мал. 3.6. Вікно доступу в автономний режим
Виберемо і активізуємо кнопку автономнопри цьому не відбудеться підключення комп'ютера до глобальної мережі Інтернет. З'явиться головне вікно програми Microsoft Internet Explorer,представлене на рис. 3.7.
Мал. 3.7. Основне вікно Microsoft Internet Explorer
Виконаємо наступну команду: [Файл - Відкрити], з'явиться вікно (рис. 3.8), в якому необхідно вказати ім'я файлу і натиснути кнопку ОК або натиснути кнопку Огляд ...і знайти файл Прім.html.
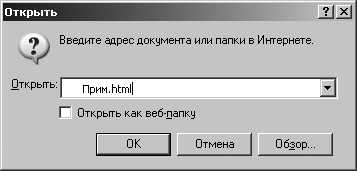
Мал. 3.8. Вікно «Відкрити»
Основне вікно програми Internet Explorer набуде вигляду, показаний на рис. 3.9. У вікні відобразиться слово «Комп'ютер». Далі, використовуючи верхнє меню програми Internet Explorer,виконаємо наступну команду: [Вид - Кодування - Кирилиця (DOS)].Після виконання цієї команди у вікні програми Internet Ехplorerвідобразяться символи, зображені на рис. 3.10. При виконанні команди: [Вид - Кодування - Кирилиця (KOI8-R)]у вікні програми Internet Explorerвідобразяться символи, зображені на рис. 3.11.
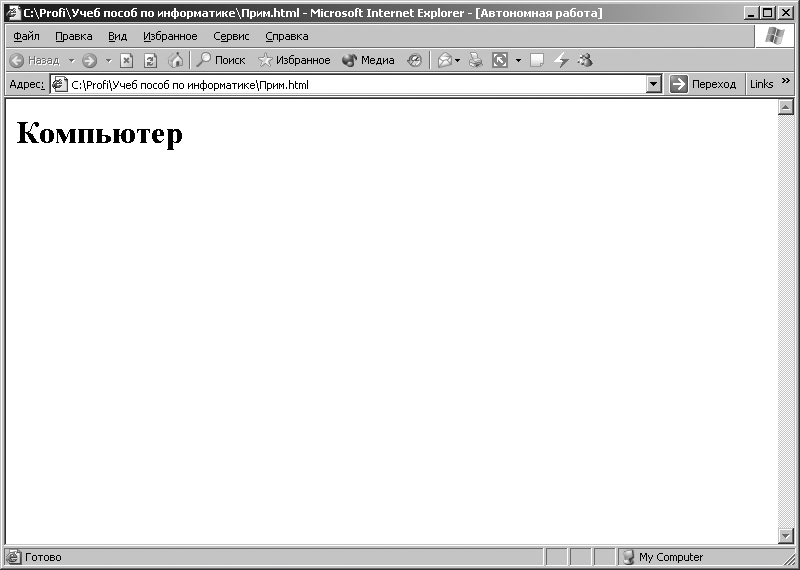
Мал. 3.9. Символи, які відображаються при кодуванні СР1251
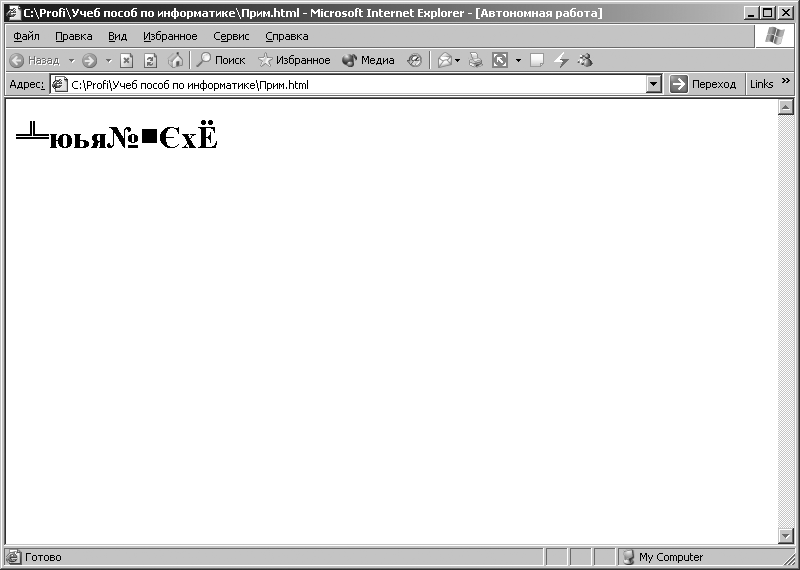
Мал. 3.10. Символи, які відображаються при включенні кодування ср866 для кодової послідовності, представленої в кодуванні СР1251
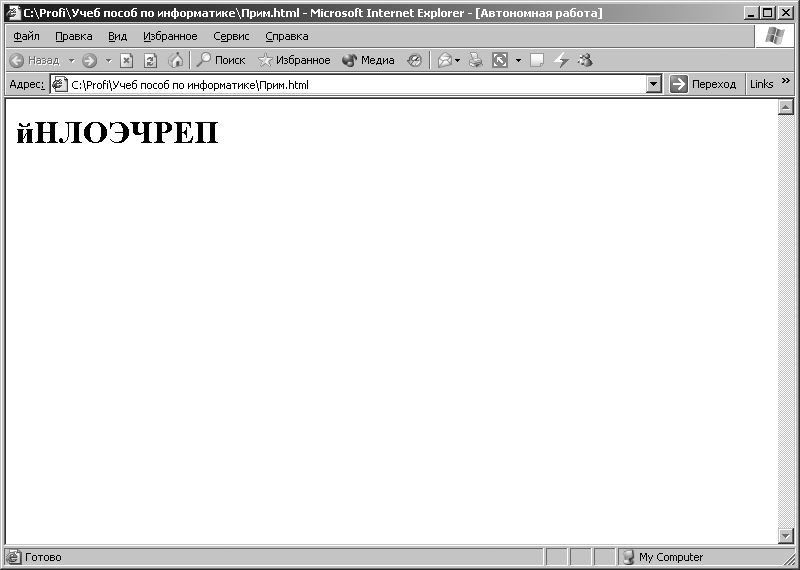
Мал. 3.11. Символи, які відображаються при включенні кодування КОІ8-Р для кодової послідовності, представленої в кодуванні СР1251
Таким чином, отримані за допомогою програми Internet Explorerпослідовності символів збігаються з послідовностями символів, отриманих за допомогою кодових таблиць ср866 і КОІ8-Р в прикладі 3.1.
Графічна інформація, представлена у вигляді малюнків, фотографій, слайдів, рухливих зображень (анімація, відео), схем, креслень, може створюватися і редагуватися за допомогою комп'ютера, при цьому вона відповідним чином кодується. В даний час існує досить велика кількість прикладних програм для обробки графічної інформації, але всі вони реалізують три види комп'ютерної графіки: растрову, векторну і фрактальну.
Якщо пильніше розглянути графічне зображення на екрані монітора комп'ютера, то можна побачити велику кількість різнокольорових точок (пікселів - від англ. pixel,утвореного від picture element -елемент зображення), які, будучи зібрані разом, і утворюють дане графічне зображення. З цього можна зробити висновок: графічне зображення в комп'ютері певним чином кодується і має бути представлено у вигляді графічного файлу. Файл є основною структурною одиницею організації та зберігання даних в комп'ютері і в даному випадку повинен містити інформацію про те, як представити цей набір точок на екрані монітора.
Файли, створені на основі векторної графіки, містять інформацію у вигляді математичних залежностей (математичних функцій, що описують лінійні залежності) і відповідних даних про те, як побудувати зображення об'єкта за допомогою відрізків ліній (векторів) при виведенні його на екран монітора комп'ютера.
Файли, створені на основі растрової графіки, припускають зберігання даних про кожну окрему точці зображення. Для відображення растрової графіки не потрібно складних математичних розрахунків, достатньо лише отримати дані про кожну точку зображення (її координати і колір) і відобразити їх на екрані монітора комп'ютера.
У процесі кодування зображення проводиться його просторова дискретизація, т. Е. Зображення розбивається на окремі точки і кожній точці задається код кольору (жовтий, червоний, синій і т. Д.). Для кодування кожної точки кольорового графічного зображення застосовується принцип декомпозиції довільного кольору на основні його складові, в якості яких використовують три основні кольори: червоний (англійське слово Red,позначають буквою К),зелений (Green,позначають буквою G),синій (Blue,позначають букой В).Будь-який колір точки, що сприймається людським оком, можна отримати шляхом адитивного (пропорційного) складання (змішування) трьох основних кольорів - червоного, зеленого і синього. Така система кодування називається колірною системою RGB.Файли графічних зображень, в яких застосовується колірна система RGB,представляють кожну точку зображення у вигляді колірного триплета - трьох числових величин R, Gі В,відповідних интенсивностям червоного, зеленого і синього кольорів. Процес кодування графічного зображення здійснюється за допомогою різних технічних засобів (сканера, цифрового фотоапарата, цифрової відеокамери та т. Д.); в результаті виходить растрове зображення. При відтворенні кольорових графічних зображень на екрані кольорового монітора комп'ютера колір кожної точки (пікселя) такого зображення виходить шляхом змішування трьох основних кольорів R, G і B.
Якість растрового зображення визначається двома основними параметрами - дозволом (кількістю точок по горизонталі і вертикалі) і використовуваної палітрою кольорів (кількістю поставлених квітів для кожної точки зображення). Дозвіл задається зазначенням числа точок по горизонталі і по вертикалі, наприклад 800 на 600 точок.
Між кількістю квітів, що задаються точці растрового зображення, і кількістю інформації, яке необхідно виділити для зберігання кольору точки, існує залежність, яка визначається співвідношенням (формула Р. Хартлі):
де I - кількість інформації; N -кількість квітів, що задаються точці.
Кількість інформації, необхідне для зберігання кольору точки, називають також глибиною кольору, або якістю передачі кольору.
Так, якщо кількість квітів, що задаються для точки зображення, N =256, то кількість інформації необхідне для її зберігання (глибина кольору) відповідно до формули (3.1) дорівнюватиме I = 8 біт.
У комп'ютерах для відображення графічної інформації використовуються різні графічні режими роботи монітора. Тут необхідно зазначити, що крім графічного режиму роботи монітора є також текстовий режим, при якому екран монітора умовно розбивається на 25 рядків по 80 символів в рядку. Ці графічні режими характеризуються дозволом екрану монітора і якістю передачі кольору (глибиною кольору). Для установки графічного режиму екрану монітора в операційній системі MS Windows ХРнеобхідно виконати команду: [Кнопка Пуск - Налаштування - Панель управління - Екран]. У діалоговому вікні «Властивості: Екран» (рис. 3.12) необхідно вибрати вкладку «Параметри» і за допомогою повзунка «Дозвіл екрану» вибрати відповідний дозвіл екрана (800 на 600 точок, 1024 на 768 точок і т. Д.). За допомогою списку «Якість передачі кольору» можна вибрати глибину кольору - «Найвища (32 біта)», «Середнє (16 біт)» і т. Д., При цьому кількість квітів, що задаються кожній точці зображення, буде відповідно дорівнює 2 32 (4294967296), 2 16 (65536) і т. д.
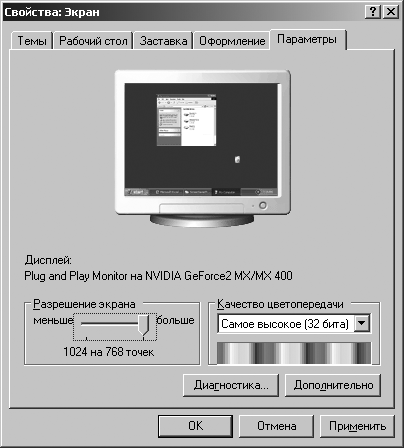
Мал. 3.12. Діалогове вікно «Властивості: Екран»
Для реалізації кожного з графічних режимів екрана монітора необхідний певний інформаційний обсяг відеопам'яті комп'ютера. Необхідний інформаційний обсяг відеопам'яті (V)визначається зі співвідношення
де К -кількість точок зображення на екрані монітора (К = А · В); А -кількість точок по горизонталі на екрані монітора; В -кількість точок по вертикалі на екрані монітора; I - кількість інформації (глибина кольору).
Так, якщо екран монітора має роздільну здатність 1024 на 768 точок і палітру, що складається з 65 536 кольорів, то глибина кольору відповідно до формули (3.1) складе I = log 2 65 538 = 16 біт, кількість точок зображення дорівнюватиме: К =1024 х 768 = 786432, і необхідний інформаційний обсяг відеопам'яті відповідно до (3.2) буде дорівнює
V =786432 · 16 біт = 12582912 біт = 1572864 байт = тисяча п'ятсот тридцять шість Кбайт = 1,5 Мбайт.
На закінчення слід зазначити, що крім перечісленнихарактерістік найважливішими характеристиками монітора є геометричні розміри його екрану і точки зображення. Геометричні розміри екрану задаються величиною діагоналі монітора. Величина діагоналі моніторів задається в дюймах (1 дюйм = 1 "= 25,4 мм) і може приймати значення, рівні: 14", 15 ", 17", 21 "т. Д. Сучасні технології виробництва моніторів можуть забезпечити розмір точки зображення рівний 0,22 мм.
Таким чином, для кожного монітора існує фізично максимально можлива роздільна здатність екрану, що визначається величиною його діагоналі і розміром точки зображення.
1. За допомогою програми MS Excelперетворити кодові таблиці ASCII, ср866, СР1251, КОІ8-Р до таблиць виду: в осередки першого шпальти таблиць записати в алфавітному порядку великі, а потім малі літери латиниці і кирилиці, в осередку другого шпальти - відповідні буквах коди в десятковій системі числення, в осередку третього стовпчика - відповідні буквах коди в шістнадцятковій системі числення. Значення кодів необхідно вибрати з відповідних кодових таблиць.
2. Закодувати і записати у вигляді послідовності чисел в десятковій і шістнадцятковій системі числення наступні слова:
a) Internet Explorer,б) Microsoft Office;в) CorelDRAW.
Кодування зробити за допомогою модернізованої кодувальної таблиці ASCII, отриманої в попередній вправі.
3. Декодувати за допомогою модернізованої кодувальної таблиці КОІ8-Р послідовності чисел записаних в шістнадцятковій системі числення:
а) FC CB DA C9 D3 D4 C5 CE C3 C9 D1;
б) EB CF CE C6 CF D2 CD C9 DA CD;
в) FC CB D3 D0 D2 C5 D3 C9 CF CE C9 DA CD.
4. Який вигляд матиме слово «Кібернетика», записане в кодуванні СР1251, при використанні кодувань ср866 і КОІ8-Р? Перевірити отримані результати за допомогою програми Internet Explorer.
5. Використовуючи кодову таблицю, наведену на рис. 3.1 а,декодувати наступні кодові послідовності, записані в двійковій системі числення:
а) 01010111 01101111 01110010 01100100;
б) 01000101 01111000 01100011 01100101 01101100;
в) 01000001 01100011 01100011 01100101 01110011 01110011.
6. Визначити інформаційний обсяг слова «Економіка», закодованого за допомогою кодових таблиць ср866, СР1251, Unicode і КОІ8-Р.
7. Визначити інформаційний обсяг файлу, отриманого в результаті сканування кольорового зображення розміром 12x12 см. Роздільна здатність сканера, що використовується при скануванні даного зображення, дорівнює 600 dpi. Сканер задає глибину кольору точки зображення рівною 16 біт.
Роздільна здатність сканера 600 dpi (Dotper inch -точок на дюйм) визначає можливість сканера з такою роздільною здатністю на відрізку довжиною 1 дюйм розрізнити 600 точок.
8. Визначити інформаційний обсяг файлу, отриманого в результаті сканування кольорового зображення розміром А4. Роздільна здатність сканера, що використовується при скануванні даного зображення, дорівнює 1200 dpi. Сканер задає глибину кольору точки зображення рівної 24 біт.
9. Визначити кількість квітів у палітрі при глибині кольору 8, 16, 24 і 32 біта.
10. Визначити необхідний обсяг відеопам'яті для графічних режимів екрана монітора 640 на 480, 800 на 600, 1024 на 768 і 1280 на 1024 пікселів при глибині кольору точки зображення 8, 16, 24 і 32 біта. Результати звести в таблицю. розробити в MS Excelпрограму для автоматизації розрахунків.
11. Визначити максимальне число кольорів, яке допустимо використовувати для зберігання зображення розміром 32 на 32 точки, якщо в комп'ютері виділено під зображення 2 Кбайт пам'яті.
12. Визначити максимально можливу роздільну здатність екрана монітора, що має довжину діагоналі 15 "і розмір точки зображення 0,28 мм.
13. Які графічні режими роботи монітора може забезпечити відеопам'ять об'ємом 64 Мбайт?
Матеріал для самостійного вивчення по темі Лекції 2
Кодування ASCII
Кодировочная таблиця ASCII (ASCII - American Standard Code for Information Interchange - Американський стандартний код для обміну інформацією).
Всього за допомогою таблиці кодування ASCII (рисунок 1) можна закодувати 256 різних символів. Ця таблиця розділена на дві частини: основну (з кодами від OOh до 7Fh) і додаткову (від 80h до FFh, де буква h позначає приналежність коду до шестнадцатеричной системі числення).
Малюнок 1
Для кодування одного символу з таблиці відводиться 8 біт (1 байт). При обробці текстової інформації один байт може містити код деякого символу - літери, цифри, знака пунктуації, знака дії і т.д. Кожному символу відповідає свій код у вигляді цілого числа. При цьому всі коди збираються в спеціальні таблиці, звані кодіровочние. З їх допомогою виробляється перетворення коду символу в його видиме уявлення на екрані монітора. В результаті будь-який текст в пам'яті комп'ютера представляється як послідовність байтів з кодами символів.
Наприклад, слово hello! буде закодовано наступним чином (таблиця 1).
Таблиця 1
|
код двійковий | ||||||
|
код десятковий |
На малюнку 1 представлені символи, що входять в стандартну (англійську) і розширену (російську) кодування ASCII.
Перша половина таблиці ASCII стандартизована. Вона містить керуючі коди (від 00h до 20h і 77h). Ці коди з таблиці вилучені, так як вони не відносяться до текстових елементів. Тут же розміщуються знаки пунктуації та математичні знаки: 2lh -!, 26h - &, 28h - (, 2Bh - +, ..., великі і малі латинські букви: 41h - A, 61h - а.
Друга половина таблиці містить національні шрифти, символи псевдографіки, з яких можуть бути побудовані таблиці, спеціальні математичні знаки. Нижню частину таблиці кодувань можна замінювати, використовуючи відповідні драйвери - керуючі допоміжні програми. Цей прийом дозволяє застосовувати кілька шрифтів і їх гарнітур.
Дисплей по кожному коду символу повинен вивести на екран зображення символу - не просто цифровий код, а відповідну йому картинку, так як кожен символ має свою форму. Опис форми кожного символу зберігається в спеціальній пам'яті дисплея - знакогенератор. Висвітлення символу на екрані дисплея IBМ PC, наприклад, здійснюється за допомогою точок, що утворюють символьне матрицю. Кожен піксель в такій матриці є елементом зображення і може бути яскравим або темним. Темна точка кодується цифрою 0, світла (яскрава) - 1. Якщо зображати в матричному полі знака темні пікселі точкою, а світлі - зірочкою, то можна графічно зобразити форму символу.
люди в різних країнах використовують символи для запису слів їхніх рідних Зиков. У наші дні більшість додатків, включаючи системи електронної пошти і веб-браузери, є чисто 8-бітними, тобто вони можуть показувати і коректно сприймати лише 8-бітові символи, відповідно до стандарту ISO-8859-1.
Існує більше 256 символів в світі (якщо врахувати кирилицю, арабську, китайську, японську, корейську та тайський мови), а також з'являються все нові і нові символи. І це створює такі прогалини для багатьох користувачів:
Неможливо використовувати символи різних наборів кодувань в одному і тому ж документі. Так як кожен текстовий документ використовує свій власний набір кодувань, то виникають великі труднощі з автоматичним розпізнаванням тексту.
З'являються нові символи (наприклад: Євро), внаслідок чого ISO розробляє новий стандарт ISO-8859-15, який дуже схожий зі стандартом ISO-8859-1. Різниця полягає в наступному: з таблиці кодування старого стандарту ISO-8859-1 були прибрані символи позначення старих валют, які не використовуються в даний час, для того, щоб звільнити місце під знову з'явилися символи (такі, як Євро). В результаті у користувачів на дисках можуть лежати одні і ті ж документи, але в різних кодуваннях. Рішенням цих проблем є прийняття єдиного міжнародного набору кодувань, який називається універсальним кодуванням або Unicode.
Кодування Unicode
Стандарт запропонований в 1991 році некомерційною організацією «Консорціум Юнікоду» (англ. Unicode Consortium, Unicode Inc.). Застосування цього стандарту дозволяє закодувати дуже велике число символів з різних писемностей: у документах Unicode можуть сусідити китайські ієрогліфи, математичні символи, букви грецького алфавіту, латиниці і кирилиці, при цьому стає непотрібним переключення кодових сторінок.
Стандарт складається з двох основних розділів: універсальний набір символів (англ. UCS, universal character set) і сімейство кодувань (англ. UTF, Unicode transformation format). Універсальний набір символів задає однозначну відповідність символів кодам - елементам кодового простору, що представляє невід'ємні цілі числа. Сімейство кодувань визначає машинне представлення послідовності кодів UCS.
Стандарт Unicode був розроблений з метою створення єдиної кодування символів всіх сучасних і багатьох давніх писемних мов. Кожен символ в цьому стандарті кодується 16 бітами, що дозволяє йому охопити незрівнянно більшу кількість символів, ніж прийняті раніше 8-бітові кодування. Ще однією важливою відмінністю Unicode від інших систем кодування є те, що він не тільки приписує кожному символу унікальний код, але і визначає різні характеристики цього символу, наприклад:
тип символу (прописна буква, мала літера, цифра, розділовий знак і т.д.);
атрибути символу (відображення зліва направо або справа наліво, пробіл, розрив рядка і т.д.);
відповідна прописна або рядкова буква (для малих і великих літер відповідно);
відповідне числове значення (для цифрових символів).
Весь діапазон кодів від 0 до FFFF розбитий на кілька стандартних підмножин, кожне з яких відповідає або алфавітом якоїсь мови, або групі спеціальних символів, подібних за своїми функціями. На наведеній нижче схемі міститься загальний перелік підмножин Unicode 3.0 (малюнок 2).
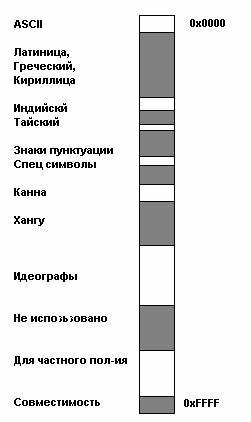
малюнок 2
Стандарт Unicode є основою для зберігання і тексту в багатьох сучасних комп'ютерних системах. Однак, він не сумісний з більшістю Інтернет-протоколів, оскільки його коди можуть містити будь-які байтові значення, а протоколи зазвичай використовують байти 00 - 1F і FE - FF в якості службових. Для досягнення сумісності були розроблені кілька форматів перетворення Unicode (UTFs, Unicode Transformation Formats), з яких на сьогодні найбільш поширеним є UTF-8. Цей формат визначає наступні правила перетворення кожного коду Unicode в набір байтів (від одного до трьох), придатних для транспортування Інтернет-протоколами.
Тут x, y, z позначають біти вихідного коду, які повинні вилучатися, починаючи з молодшого, і заноситися в байти результату справа наліво, поки не будуть заповнені всі зазначені позиції.
Подальший розвиток стандарту Unicode пов'язано з додаванням нових мовних площин, тобто символів в діапазонах 10000 - 1FFFF, 20000 - 2FFFF і т.д., куди передбачається включати кодування для письменностей мертвих мов, що не потрапили в таблицю, наведену вище. Для кодування цих додаткових символів був розроблений новий формат UTF-16.
Таким чином, існує 4 основних способи кодування байтами в форматі Unicode:
UTF-8: 128 символів кодуються одним байтом (формат ASCII), 1920 символів кодуються 2-мя байтами ((Roman, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic символи), 63488 символів кодуються 3-ма байтами (Китайська, японська та ін.) Решту 2 147 418 112 символи (ще не використані) можуть бути закодовані 4, 5 або 6-ю байтами.
UCS-2: Кожен символ представлений 2-ма байтами. Дана кодування включає лише перші 65 535 символів з формату Unicode.
UTF-16: Чи є розширенням UCS-2, налічує 1 114 112 символів формату Unicode. Перші 65 535 символів представлені 2-ма байтами, інші - 4-ма байтами.
USC-4: Кожен символ кодується 4-ма байтами.
Кодування текстової інформації в комп'ютері - часом невід'ємна умова коректної роботи пристрою або відображення того чи іншого фрагмента. Як відбувається цей процес в ході роботи комп'ютера з текстом і візуальною інформацією, звуком - все це ми розберемо в цій статті.
Електронна обчислювальна машина (яку ми в повсякденному житті називаємо комп'ютером) сприймає текст дуже специфічне. Для неї кодування текстової інформації дуже важливо, оскільки вона сприймає кожен текстовий фрагмент як група відокремлених один від одного символів.

У ролі символів для комп'ютера виступають не тільки російські, англійські та інші літери, а й ще розділові знаки, а також інші знаки. Навіть пробіл, яким ми поділяємо слова при друкуванні на комп'ютері, пристрій сприймає як символ. Чимось дуже нагадує вищу математику, адже там, на думку багатьох професорів, нуль має подвійне значення: він і є числом, і одночасно нічого не означає. Навіть для філософів питання пробілу в тексті може стати актуальною проблемою. Жарт, звичайно, але, як то кажуть, в кожному жарті є частка правди.

Отже, для сприйняття інформації комп'ютера необхідно запустити процеси обробки. А яка взагалі буває інформація? Темою цієї статті є кодування текстової інформації. Ми приділимо особливу увагу цьому завданню, але розберемося і з іншими мікротеми.
Інформація може бути текстової, числової, звуковий, графічної. Комп'ютер повинен запустити процеси, що забезпечують кодування текстової інформації, щоб вивести на екран те, що ми, наприклад, друкуємо на клавіатурі. Ми будемо бачити символи і букви, це зрозуміло. А що ж бачить машина? Вона сприймає абсолютно всю інформацію - і мова зараз йде не тільки про текст - як певної послідовності нулів і одиниць. Вони складають основу так званого двійкового коду. Відповідно, процес, який перетворює інформацію, що надходить на пристрій інформацію в зрозумілу йому, має назву " двійкове кодування текстової інформації ".

Чому найбільшого поширення в електронних машинах отримало саме кодування інформації двійковим кодом? Текстової основою, яка кодується за допомогою нулів і одиниць, може бути абсолютно будь-яка послідовність символів і знаків. Однак це не єдина перевага, яку має двійкове текстове кодування інформації. Вся справа в тому, що принцип, на якому влаштований такий спосіб кодування, дуже простий, але в той же час досить функціональний. Коли є електричний імпульс, його маркують (умовно, звичайно) одиницею. Немає імпульсу - маркують нулем. Тобто текстове кодування інформації базується на принципі побудови послідовності електричних імпульсів. Логічна послідовність, складена з символів двійкового коду, називається машинним мовою. У той же час кодування і обробка текстової інформації за допомогою двійкового коду дозволяють здійснювати операції за досить короткий проміжок часу.

Цифра, що сприймається машиною, криє в собі деяку кількість інформації. Воно дорівнює одному біту. Це стосується кожної одиниці і кожного нуля, які складають ту чи іншу послідовність зашифрованої інформації.
Відповідно, кількість інформації в будь-якому випадку можна визначити, просто знаючи кількість символів в послідовності двійкового коду. Вони будуть чисельно рівні між собою. 2 цифри в коді несуть в собі інформацію обсягом в 2 біта, 10 цифр - 10 біт і так далі. Принцип визначення інформаційного обсягу, який криється в тому чи іншому фрагменті двійкового коду, досить простий, як ви бачите.
Ось зараз ви читаєте статтю, яка складається з послідовності, як ми вважаємо, букв алфавіту російської мови. А комп'ютер, як говорилося раніше, сприймає всю інформацію (і в даному випадку теж) як послідовності не букви, а нулів і одиниць, що позначають відсутність і наявність електричного імпульсу.
Вся справа в тому, що закодувати один символ, який ми бачимо на екрані, можна за допомогою умовної одиниці виміру, званої байтом. Як написано вище, у двійкового коду є так звана інформаційна навантаження. Нагадаємо, що чисельно вона дорівнює сумарній кількості нулів і одиниць в обраному фрагменті коду. Так ось, 8 біт складають 1 байт. Комбінації сигналів при цьому можуть бути самими різними, як це легко можна помітити, намалювавши на папері прямокутник, що складається з 8 осередків рівного розміру.
Виходить, що закодувати текстову інформацію можна за допомогою алфавіту, що має потужність 256 символів. В чому полягає суть? Сенс криється в тому, що кожен символ буде мати своїм двійковим кодом. Комбінації, "прив'язують" до певних символів, починаються від 00000000 і закінчуються 11111111. Якщо переходити від двійковій до десяткової системі числення, то кодувати інформацію в такій системі можна від 0 до 255.
Не варто забувати про те, що зараз є різні таблиці, Які використовують кодування букв російського алфавіту. Це, наприклад, ISO і КОИ-8, Mac і CP в двох варіаціях: 1251 Росія і 866. Легко переконатися в тому, що текст, закодований в одній з таких таблиць, не з'явиться коректно у відмінній від даної кодуванні. Це відбувається через те, що в різних таблицях до одного і того ж двійкового коду відповідають різні символи.
Спочатку це було проблемою. Однак в даний час в програмах вже вбудовані спеціальні алгоритми, які конвертують текст, приводячи його до коректного виду. 1997 ознаменувався створенням кодування під назвою Unicode. У ній кожен символ має в своєму розпорядженні відразу 2 байта. Це дозволяє закодувати текст, який має набагато більшу кількість символів. 256 і 65536: є ж різниця?
Кодування текстової та графічної інформації має деякі схожі моменти. Як відомо, для виведення графічної інформації використовується периферійний пристрій комп'ютера під назвою "монітор". Графіка зараз (мова йде зараз саме про комп'ютерну графіку) широко використовується в самих різних сферах. Благо, апаратні можливості персональних комп'ютерів дозволяють вирішувати досить складні графічні завдання.
Обробляти відеоінформацію стало можливим в останніми роками. Але текст при цьому значно "легше" графіки, що, в принципі, зрозуміло. Через це кінцевий розмір файлів графіки необхідно збільшувати. Подолати подібні проблеми можна, знаючи суть, в якій представляється графічна інформація.
Давайте для початку розберемося, на які групи поділяється даний вид інформації. По-перше, це растрова. По-друге, векторна.
Растрові зображення досить схожі з картатою папером. Кожна клітина на такому папері закрашивается тим чи іншим кольором. Такий принцип чимось нагадує мозаїку. Тобто виходить, що в растровій графіці зображення розбивається на окремі елементарні частини. Їх називають пікселями. У перекладі на російську мову пікселі позначають "точки". Логічно, що пікселі впорядковані щодо рядків. Графічна сітка складається якраз з певної кількості пікселів. Її також називають растром. Беручи до уваги ці два визначення, можна сказати, що растрове зображення є не чим іншим, як набором пікселів, які відображаються на сітці прямокутного типу.
Растр монітора і розмір пікселя впливають на якість зображення. Воно буде тим вище, чим більше растр біля монітора. Розміри растра - це дозвіл екрана, про який напевно чув кожен користувач. Однією з найбільш важливих характеристик, які мають екрани комп'ютера, є роздільна здатність, а не тільки дозвіл. Воно показує, скільки пікселів доводиться на ту чи іншу одиницю довжини. Зазвичай роздільна здатність монітора вимірюється в пікселях на дюйм. Чим більше пікселів буде припадати на одиницю довжини, тим вищою буде якість, оскільки "зернистість" при цьому знижується.
Кодування текстової та звукової інформації, як і інші види кодування, має деякі особливості. Мова зараз піде про останній процесі: кодуванні звукової інформації.
Подання звукового потоку (як і окремого звуку) може бути вироблено за допомогою двох способів.
При цьому величина може приймати справді величезна кількість різних значень. Причому ці самі значення не залишаються постійними: вони дуже швидко змінюються, і цей процес безперервний.
![]()
Якщо ж говорити про дискретно способі, то в цьому випадку величина може приймати лише обмежену кількість значень. При цьому зміна відбувається стрибкоподібно. Закодувати дискретно можна не тільки звукову, але і графічну інформацію. Що стосується і аналогової форми, до речі.
Аналогова звукова інформація зберігається на вінілових пластинках, наприклад. А ось компакт-диск вже є дискретним способом подання інформації звукового характеру.
На самому початку ми говорили про те, що комп'ютер сприймає всю інформацію на машинному мовою. Для цього інформація кодується в формі послідовності електричних імпульсів - нулів і одиниць. Кодування звукової інформації не є винятком з цього правила. Щоб обробити на комп'ютері звук, його для початку потрібно перетворити в ту саму послідовність. Тільки після цього над потоком або одиничним звуком можуть відбуватися операції.
Коли відбувається процес кодування, потік піддається тимчасової дискретизації. Звукова хвиля неперервна, вона розвивається на малі ділянки часу. Значення амплітуди при цьому встановлюється для кожного певного інтервалу окремо.
Отже, що ж ми з'ясували в ході даної статті? По-перше, абсолютно вся інформація, яка виводиться на монітор комп'ютера, перш ніж там з'явитися, піддається кодування. По-друге, це кодування полягає в перекладі інформації на машинний мову. По-третє, машинний мова являє собою не що інше, як послідовність електричних імпульсів - нулів і одиниць. По-четверте, для кодування різних символів існують окремі таблиці. І, по-п'яте, уявити графічну і звукову інформацію можна в аналоговому і дискретно вигляді. Ось, мабуть, основні моменти, які ми розібрали. Однією з дисциплін, що вивчає цю область, є інформатика. Кодування текстової інформації і його основи пояснюються ще в школі, оскільки нічого складного в цьому немає.
Кодування текстової інформації
Згадаймо деякі відомі нам факти:
Безліч символів, за допомогою яких записується текст, називаєтьсяалфавітом.
Число символів в алфавіті - це йогопотужність.
Формула визначення кількості інформації:N = 2b,
де N - потужність алфавіту (кількість символів),
b - кількість біт (інформаційний вагу символу).
В алфавіт потужністю 256 символів можна помістити практично всі необхідні символи. Такий алфавіт називаєтьсядостатнім.
Оскільки 256 = 28 , То вага 1 символу - 8 біт.
Одиниці виміру 8 біт присвоїли назву1 байт:
1 байт = 8 біт.
Двійковий код кожного символу в комп'ютерному тексті займає 1 байт пам'яті.
Яким же чином текстова інформація представлена в пам'яті комп'ютера?
|
| Тексти вводяться в пам'ять комп'ютера за допомогою клавіатури. На клавішах написані звичні нам букви, цифри, знаки пунктуації та інші символи. В оперативну пам'ять вони потрапляють в двійковому коді. Це означає, що кожен символ представляється 8-розрядних двійковим кодом. Кодування полягає в тому, що кожному символу ставиться у відповідність унікальний десятковий код від 0 до 255 або відповідний йому двійковий код від 00000000 до 11111111. Таким чином, людина розрізняє символи за їх зображенню, а комп'ютер - по їх коду. |
Зручність побайтового кодування символів очевидно, оскільки байт - найменша адресується частина пам'яті і, отже, процесор може звернутися до кожного символу окремо, виконуючи обробку тексту. З іншого боку, 256 символів - це цілком достатня кількість для подання найрізноманітнішої символьної інформації.
Тепер виникає питання, який саме восьмизарядний двійкового коду поставити у відповідність кожному символу.
Зрозуміло, що це справа умовне, можна придумати безліч способів кодування.
Всі символи комп'ютерного алфавіту пронумеровані від 0 до 255. Кожному номеру відповідає восьмизарядний двійкового коду від 00000000 до 11111111. Цей код просто порядковий номер символу в двійковій системі числення.
Таблиця, в якій всім символам комп'ютерного алфавіту поставлені у відповідність порядкові номери, називається таблицею кодування.
Для різних типів ЕОМ використовуються різні таблиці кодування.
Міжнародним стандартом для ПК стала таблицяASCII(Читається аски) (Американський стандартний код для інформаційного обміну).
Таблиця кодів ASCII ділиться на дві частини.
Міжнародним стандартом є лише перша половина таблиці, тобто символи з номерами від0 (00000000), до127 (01111111).
Структура таблиці кодування ASCII
| Порядковий номер | код | символ |
| 0 - 31 | 00000000 - 00011111 | Символи з номерами від 0 до 31 прийнято називати керуючими. |
| 32 - 127 | 00100000 - 01111111 | Стандартна частина таблиці (англійська). Сюди входять малі та великі літери латинського алфавіту, десяткові цифри, розділові знаки, всілякі дужки, комерційні та інші символи. |
| 128 - 255 | 10000000 - 11111111 | Альтернативна частина таблиці (російська). |
Перша половина таблиці кодів ASCII
|
|
Звертаю вашу увагу на те, що в таблиці кодування букви (великі та малі) розташовуються в алфавітному порядку, а цифри впорядковані за зростанням значень. Таке дотримання лексикографічного порядку в розташуванні символів називається принципом послідовного кодування алфавіту.
Для букв російського алфавіту також дотримується принцип послідовного кодування.
Друга половина таблиці кодів ASCII
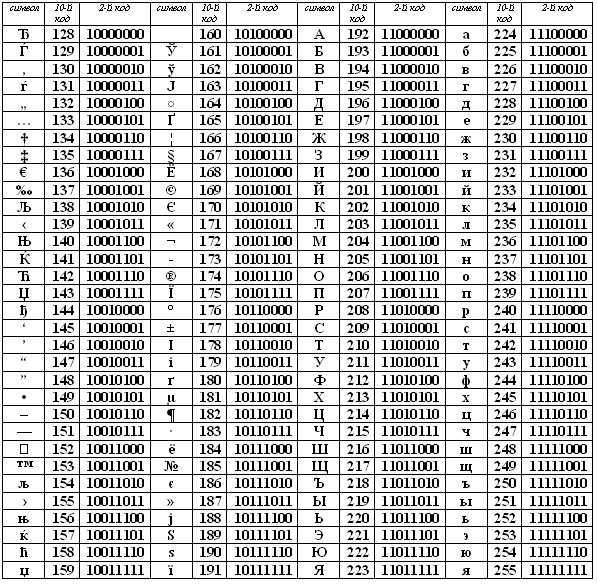
На жаль, в даний час існують п'ять різних кодувань кирилиці (КОІ8-Р, Windows. MS-DOS, Macintosh і ISO). Через це часто виникають проблеми з перенесенням російського тексту з одного комп'ютера на інший, з однієї програмної системи в іншу.
Хронологічно одним з перших стандартів кодування російських букв на комп'ютерах був КОІ8 ( "Код обміну інформацією, 8-бітний"). Це кодування застосовувалася ще в 70-ті роки на комп'ютерах серії ЄС ЕОМ, а з середини 80-х стала використовуватися в перших русифікованих версіях операційної системи UNIX.
Від початку 90-х років, часу панування операційної системи MS DOS, залишається кодування CP866 ( "CP" означає "Code Page", "кодова сторінка").
Комп'ютери фірми Apple, що працюють під управлінням операційної системи Mac OS, використовують свою власну систему кодування Mac.
Крім того, Міжнародна організація по стандартизації (International Standards Organization, ISO) затвердила в якості стандарту для російської мови ще одне кодування під назвою ISO 8859-5.
Найбільш поширеною в даний час є кодування Microsoft Windows, що позначається скороченням CP1251.
З кінця 90-х років проблема стандартизації символьного кодування вирішується введенням нового міжнародного стандарту, який називаєтьсяUnicode. Це 16-розрядна кодування, тобто в ній на кожен символ відводиться 2 байти пам'яті. Звичайно, при цьому обсяг займаної пам'яті збільшується в 2 рази. Але зате така кодова таблиця допускає включення до 65536 символів. Повна специфікація стандарту Unicode включає в себе всі існуючі, вимерлі і штучно створені алфавіти світу, а також безліч математичних, музичних, хімічних та інших символів.
Спробуємо за допомогою таблиці ASCII уявити, як будуть виглядати слова в пам'яті комп'ютера.
Внутрішнє представлення слів в пам'яті комп'ютера
| слова | пам'ять |
| file | 01100110 01101001 01101100 01100101 |
| disk | 01100100 01101001 01110011 01101011 |
Іноді буває так, що текст, що складається з букв російського алфавіту, отриманий з іншого комп'ютера, неможливо прочитати - на екрані монітора видно якась "абракадабра". Це відбувається тому, що на комп'ютерах застосовується різна кодування символів російської мови.
| Статті по темі: | |
|
Регулярний сорт конопель. Насіння марихуани. Де легалізована марихуана і чи можна від неї померти
Марихуана (канабіс) є найпоширенішим наркотиком у всьому ... Особистий кабінет платника податків: податки в один клік
Як платити податки швидко і без візиту до інспекторів? Сьогодні сайт ... Марки німецького пива: історія і технології
Пиво в Німеччині, безсумнівно, є найбільш популярним алкогольним ... | |




